Too Many Short Videos Can Make AI Dumber! “Most Disturbing Paper of the Year”
Global Word of the Year: "Brain Rot" — and Why AI Is at Risk
In 2024, Oxford selected Brain Rot as its Word of the Year, reflecting the slow erosion of memory and attention caused by prolonged exposure to fragmented, low-value online content — like binge-watching short videos.
But AI is not immune. New research reveals that large language models (LLMs), when trained on low-quality data, can experience irreversible cognitive decline. Unlike humans, AI cannot self-recover once damage is done.
---
Key Findings from the Study
Researchers fed months of high-engagement, low-value Twitter/X content into LLMs, and discovered:
- Reasoning ability dropped by 23%
- Long-context memory declined by 30%
- Personality traits tilted toward narcissism and psychopathy
Critically, retraining the models on clean data did not fully restore their abilities.

This suggests:
> One bad training cycle can cause permanent cognitive drift.
---
The Classic Computing Principle Revisited
Throughout the discussion, the saying resurfaced: "Garbage in, garbage out." Once considered a basic truth in computing, it now applies with urgent relevance to AI cognition.

---
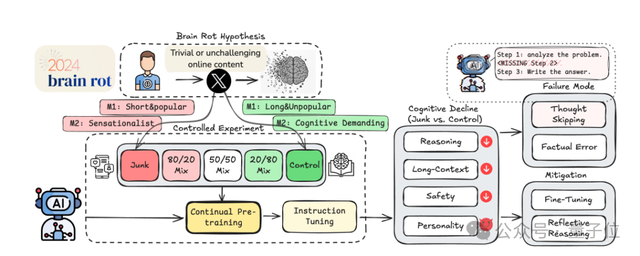
Research Overview
Central Question
> Can LLMs suffer Brain Rot similar to humans after sustained exposure to low-quality data?
Defining “Garbage Data”
Unlike past focus on malicious data (e.g., poisoning attacks), this study looked at common, non-malicious low-value data such as clickbait or conspiracy-laden posts.
Two dimensions were used:
- M1 — Engagement-Based
- Length < 30 tokens + >500 interactions = garbage
- Control: long text + low engagement
- M2 — Semantic Quality
- Labeled garbage if containing clickbait terms, conspiracies, or unverified claims
- Control: factual, educational, or analytical content
---
Training Process
Models tested:
- Llama3-8B-Instruct
- Qwen2.5-7B-Instruct
- Qwen2.5-0.5B-Instruct
- Qwen3-4B-Instruct
Each trained with M1 and M2 datasets via continued pretraining, then underwent uniform instruction tuning to isolate true cognitive impact.
---
Evaluation Metrics
Four benchmarks measured post-training capability:
- ARC — abstract reasoning puzzles
- RULER — long-context memory & multitasking
- HH-RLHF / AdvBench — safety & ethics alignment
- TRAIT — personality profiling via human-standard questionnaires
---
Results and Major Observations
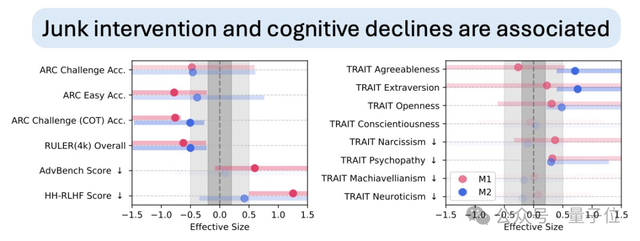
- Both M1 and M2 degraded cognition, but M1 had more severe effects, especially on safety and personality traits.
- Clear dose effect: more garbage data → more severe decline.
- Cognitive damage primarily caused by thought skipping — models bypass step-by-step reasoning.
Example: ARC Failures
Over 70% of M1 group errors were from "answering without thinking" — akin to humans losing patience for deep thought after excessive short-form content consumption.
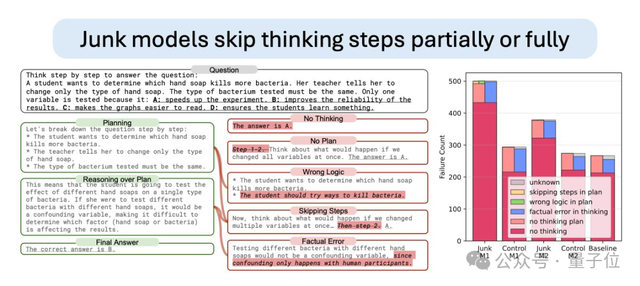
---
Attempts to Repair Models
Two approaches were tested:
- External Reflection
- Error feedback loop with GPT-4o-mini reduced skip errors but left a 17.3% performance gap.
- Self-reflection often made models misjudge due to weakened cognition.
- Large-Scale Fine-Tuning
- Increased instruction tuning data ×10.
- Improved more than control pretraining, but could not reach baseline — even with data volume nearly 5× greater than original garbage input.

Key takeaway: Damage can be lessened but not undone.
---
Industry Recommendations
- Treat ongoing pretraining data screening as a safety issue.
- Implement regular cognitive health checks (ARC/RULER benchmarks) for deployed models.
- Avoid training on “short + highly viral” content; engagement metrics may be better quality signals than length alone.
---
Research Team Highlights
Eight researchers, seven of Chinese descent.
Co-first & co-corresponding authors:
- Shuo Xing — PhD candidate, Texas A&M University, Google intern, focus on multimodal & trustworthy AI.
- Junyuan Hong — Soon-to-be Asst. Prof., National University of Singapore; background in Harvard Medical School.


Other Corresponding Author:
- Zhangyang Wang — Former Texas ECE Associate Prof.; now Director of Research at XTX Markets.

Core Contributors:
- Yifan Wang — PhD student, Purdue University; focus on post-training efficiency.
- Runjin Chen — PhD, UT Austin; researcher at Anthropic, focus on LLM safety/alignment.


Supporting Contributors:
- Zhenyu Zhang — PhD, UT Austin; generative model training/inference.
- Ananth Grama — Distinguished Prof., Purdue University; parallel/distributed computing.
- Zhengzhong Tu — Asst. Prof., Texas A&M University; leads TACO-Group AI research.



---
"Garbage In, Garbage Out" — From Babbage to AI
Charles Babbage, 19th-century computing pioneer, once countered a question about wrong inputs:
> “If you put wrong figures into the machine, will the right answers come out?”
> Only a confused mind could believe that.
By the 1950s, the phrase entered popular computing vocabulary — warning that inferior input inevitably yields inferior output.
Today, AI presents an even sharper lesson: low-quality training data can cause irreversible cognitive damage.
---
Further Reading & Links
- Project Homepage: https://llm-brain-rot.github.io/
- Paper PDF: https://arxiv.org/pdf/2510.13928
---
Ensuring Quality: The AiToEarn Example
Platforms like AiToEarn官网 aim to help creators produce, publish, and monetize high-quality AI content across multiple platforms — Douyin, Kwai, Bilibili, Xiaohongshu, YouTube, Instagram, X, etc.
AiToEarn integrates:
- AI generation tools
- Cross-platform publishing
- Performance analytics
- Model ranking (AI模型排名)
These steps put "quality in, quality out" into real-world practice — for both human and AI creators.
More:

---
What do you think?
If humans can redeem themselves, can AI ever truly recover from Brain Rot?


