Translate the following blog post title into English, concise and natural. Return plain text only without quotes. 抛弃“级联”架构!快手 OneRec 用大模型重构推荐系统,服务成本降至 1/10

作者 | 周国睿
编辑|李忠良、蔡芳芳
策划|AICon 全球人工智能开发与应用大会
传统级联式推荐将召回、粗排、精排与重排割裂,反馈难以闭环,模块间不一致持续累积,令算力利用效率(MFU:总消耗算力 /OPEX 可购最大算力)长期偏低,成为技术与业务演进的共同瓶颈。快手以生成式端到端架构 OneRec 重构推荐链路,在核心场景实现“更大模型、却更低成本”的跃迁:服务成本降至原系统的 1/10,并重新定义推荐系统的智能边界与效率标尺。快手科技副总裁、基础大模型及推荐模型负责人周国睿在 AICon 全球人工智能开发与应用大会上,系统解析了推荐系统的范式革新、 OneRecV2的scaling定制优化,以及OneRec-Think的“生成—理解”统一进展,为 AI 原生时代的推荐提供可复制的方法论。
以下是演讲实录(经 InfoQ 进行不改变原意的编辑整理)。
传统推荐架构的规模化瓶颈与范式局限
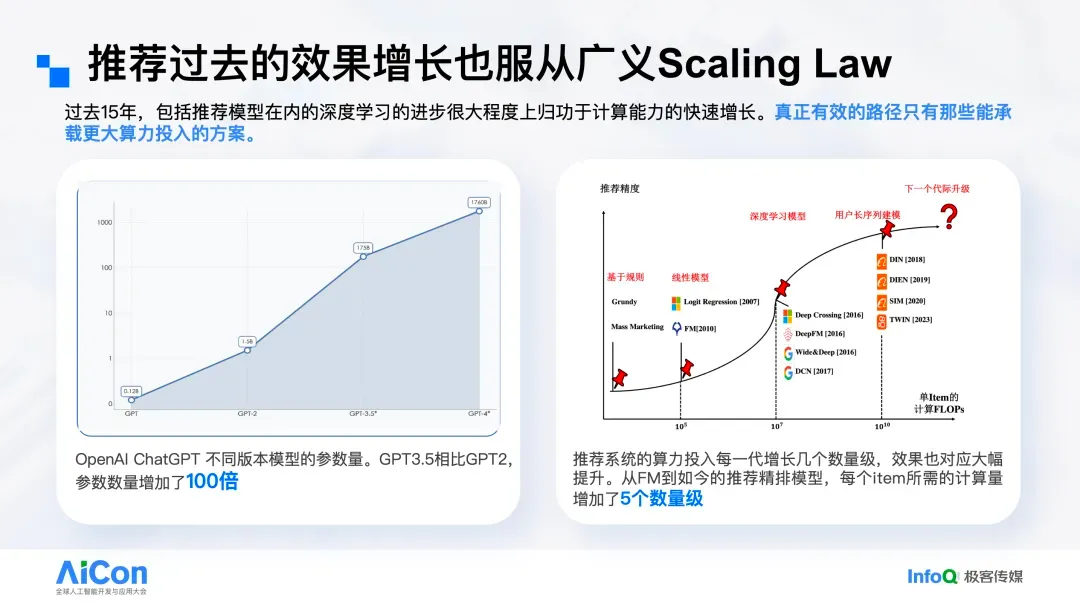
传统推荐架构正成为技术与业务演进的瓶颈。从最早的规则引擎到线性模型,再到深度学习进入推荐、行为序列建模,每一次技术跃迁都伴随着可用算力的数量级提升。以 FM 到基于行为序列的精排模型为例,单个推荐 item 的计算量大约提升了 5 个数量级,同时带来显著效果增益。然而,近两年 LLM 突飞猛进,推荐领域却更多停留在精排等局部环节的微调上,整体创新进入瓶颈。如果我们仍将迭代重心局限于排序模块、围绕单点模型做细节优化,要获得数量级的提升将愈发困难。
能否直接借用 LLM 的技术栈与算力方案,重构一套端到端的推荐系统?
直接采用 LLM 架构来做推荐的想法,看似美好,但深入思考并不简单,根本原因在于 LLM 与推荐的在线服务场景差异巨大。推荐是典型的低延迟、高并发服务,需要实时响应海量请求;而在 Chatbot 等场景中,用户可以接受更长的等待时间,请求量也与推荐系统不在同一量级。
因此,当被询问“能不能用 LLM 来做推荐”时,团队往往会给出“想法很好但不现实”的反馈,常见理由有三点:其一,推荐模型本身已经很大。若将用于表示物料 ID 的稀疏 Embedding 计算在内,推荐模型规模已达 T 级(万亿参数级);其二,延迟要求极为严苛,难以留出足够的推理时间,推荐需要毫秒级响应;其三,计算成本高,在信息流等场景中,大模型推理成本可能难以被业务收益覆盖。
这些观点初看合理,但经不起推敲。首先,对“模型已足够大”的判断应聚焦“激活参数”。在在线推理中,推荐模型的激活参数远小于典型语言模型:以快手为例约 250M;亦有同行 baseline 仅 16M,近期已提升至 1B,说明仍有充足的 scale-up 空间。若否认这一空间,推荐技术将难以演进——广义 Scaling Law 指出,在更低算力下难以获得更优效果。
其次,延迟无需过度焦虑,可通过离线、近线等机制加以解决。
更值得讨论的是成本:在推荐任务中引入大模型,在线推理成本能否由业务收益覆盖。与广义 AI 场景不同,推荐已是高度商业化、成熟的领域。只要引入大模型后效果提升、收益增加且可覆盖算力成本,就存在明确的商业驱动力——即便我们不做,也会有人去做。
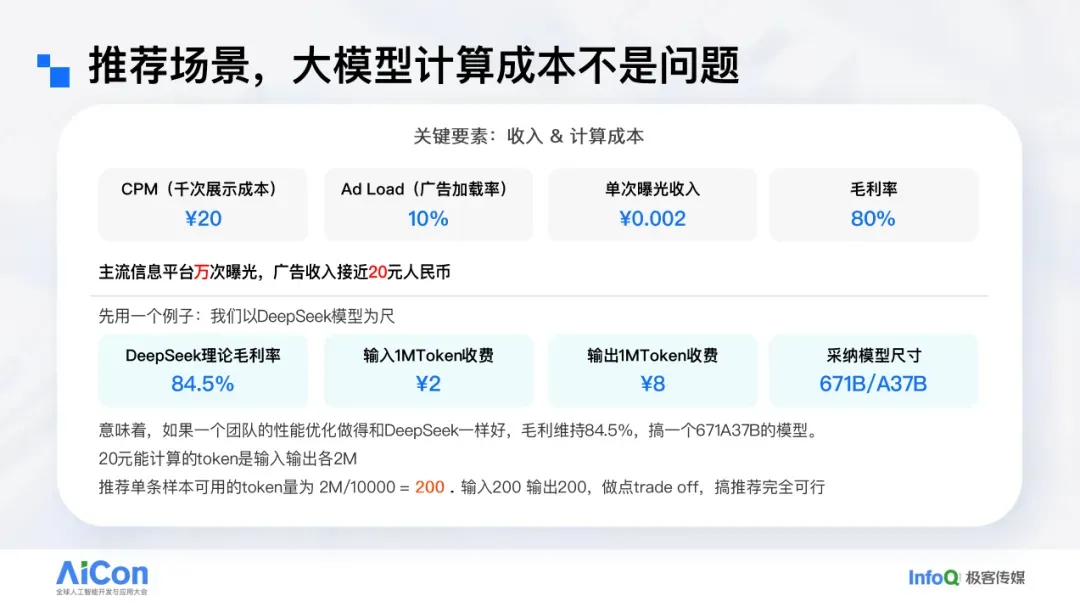
实际上,仅从在线推理成本视角看,在多数场景下,使用激活参数约 10B 的模型做推荐,仍可维持很高的毛利。
以信息流场景进行测算为例。假设信息流业务 CPM 为 20 元,广告占比 10%。则 10,000 次曝光的收入为 20 元。以 DeepSeek 模型为参照,20 元可购买到“输入与输出各 2M Token”的算力(以 671B 总参数、激活 37B 的大模型为例)。在该价格下,其理论毛利约 84.5% 左右。这意味着,当我们同样以“输入与输出各 2M Token”的配置提供服务、并达到相当的性能优化时,10,000 次曝光对应的 20 元收入下,毛利仍可超过 80%。折算到单次曝光,可用的输入输出合计约为 200 Token。
For recommendation services that require rapid response, 200 tokens are already sufficient. The above is a qualitative perception — now let's move on to a more rigorous calculation.
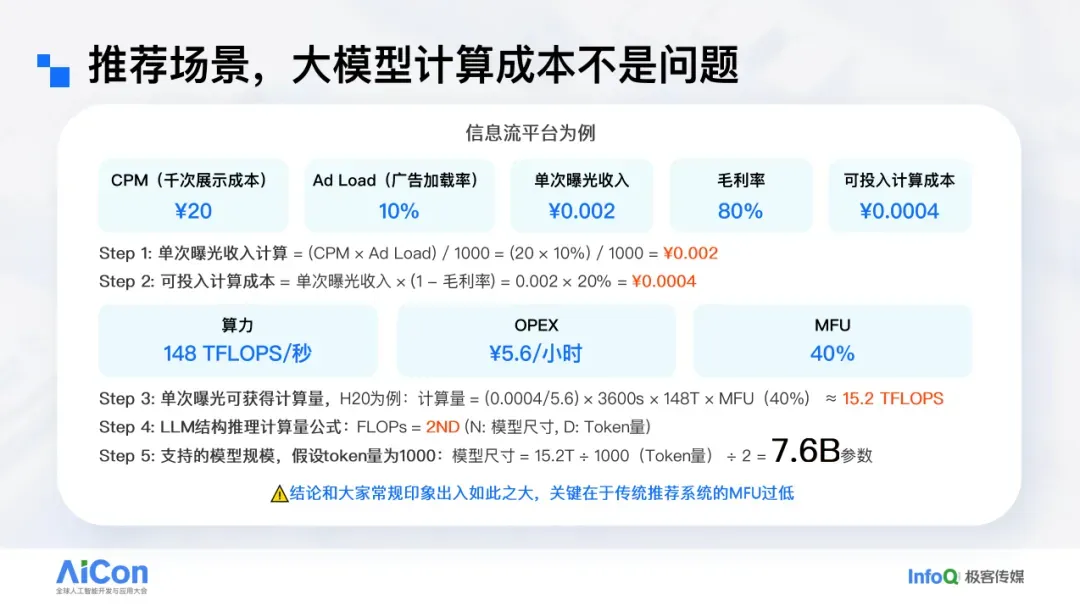
Using the same assumptions: revenue of 20 RMB per thousand ad impressions, with ads accounting for 10%. This means 10,000 impressions yield 20 RMB, and revenue per single impression is 0.002 RMB. To maintain an 80% "compute gross margin" (considering compute costs only), the allowable compute cost is 20% of revenue, i.e., 0.0004 RMB per impression.
Using H20 as the compute hardware, the OPEX is about 5.6 RMB/hour (based on public cloud provider pricing; self-hosting could be cheaper). At this rate, the allowed 0.0004 RMB per impression corresponds to approximately 15.2T FLOPs of compute power. This already factors in a Model FLOPs Utilization (MFU) of 40%.
If an LLM model is used for recommendation, its compute cost is determined mainly by two factors: model size N and token count D. Assuming 1,000 tokens consumed per impression — a reasonable assumption — the per-impression available compute translates to 15.2T FLOPs ÷ 1,000 ≈ 7.6B parameters in model size.
Thus, as long as the business operates at around "CPM 20 RMB, ads at 10% share," using a model of about 7.6B parameters for online service is viable in terms of cost.
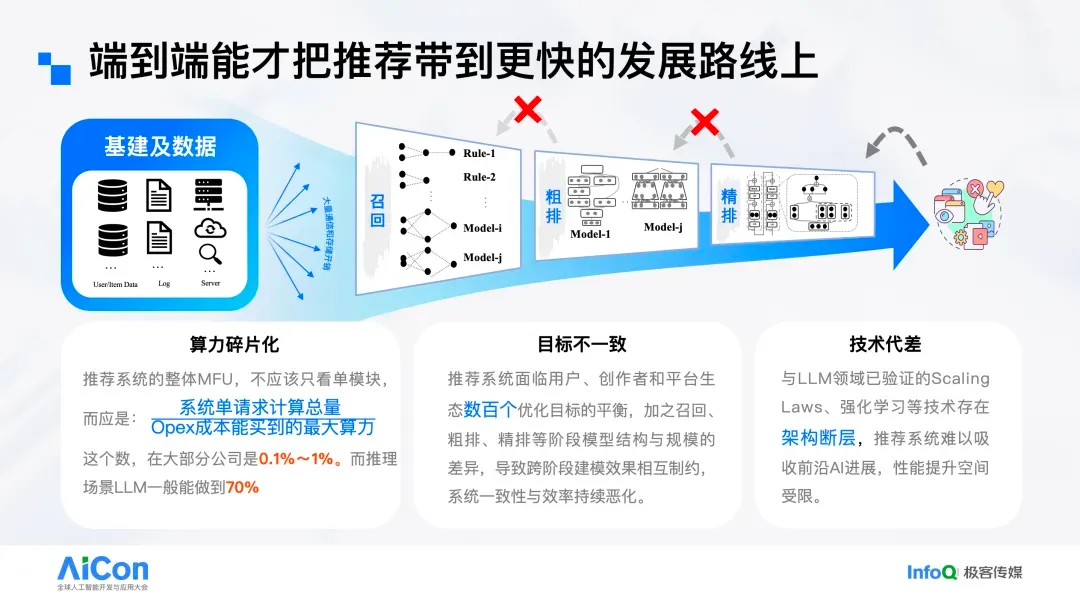
This conclusion differs from the intuition of many teams, primarily due to different MFU assumptions. Here we use 40%, whereas in traditional cascaded recommendation systems (data → recall → coarse rank → fine rank → rerank), the compute power is highly fragmented, leading to very low MFU — often just 1% or even less.
On MFU measurement:
In language model scenarios, MFU can be directly calculated as “actual compute FLOPs ÷ peak hardware FLOPs.” But for multi-module recommendation systems, module-by-module estimation is impractical.
Hence we introduce the concept of generalized MFU:
Take the system’s daily inference OPEX (in RMB/USD) as a baseline; compute how much frontier GPU compute power (in T FLOPs) can be purchased in the market with that budget (this is the denominator); the numerator is the system’s actual daily compute usage (in FLOPs). Their ratio is the system’s overall compute utilization rate. Its meaning is: increasing compute can improve win rate, but cannot break the model’s intelligence boundary.
For LLMs, this is easier to grasp: their solving process is essentially a deep search, predicting the next token step-by-step, using generated tokens as new context, activating internal knowledge, and gradually converging to an answer. Typical CoT phenomena show that longer sequences improve solvability for encoding and mathematical tasks. Based on this, we designed the recommendation system as a generative paradigm.
---
OneRec Generative Recommendation Framework

The overall OneRec architecture is illustrated above:
First, original sparse IDs are transformed via multimodal representations into a discrete sequence of tokens, called Semantic IDs (SID).
Next, a Behavior Transformer (similar to an Encoder) processes the user behavior sequence and relevant features.
Then, a multi-layer Decoder generates tokens, which are reverse-mapped back to the original item ID or video ID, completing the recommendation.
This enables OneRec to use a single model to cover recall, coarse ranking, fine ranking, and reranking, conducting deep resolution in the full candidate space. In practice, reinforcement learning yields significant gains; therefore, during both training and inference we introduce a Reward System to provide explicit signals for “high-quality recommendations.”
Internally, collaboration is adjusted accordingly: model teams focus on Tokenizer, pre-training methods, and infrastructure-level technologies; business algorithm teams define “high-quality recommendation” criteria and design the Reward System accordingly. The coupling between the two has been smooth, and iteration efficiency is strong.
---
Tokenizer Design
OneRec converts raw ID data into a text-like token system.
The method is straightforward: if you can obtain embedding representations for each ID, you can use a discretization approach (similar to VAE) to map them into tokens.
The key lies in the quality of the representation: it must capture the content itself (e.g., what a short video “is saying”) while distilling the most relevant information for recommendation (i.e., what the user “truly cares about”).

---
Note:
For large-scale generative recommendation scenarios — especially those aiming to optimize token usage and compute efficiency — it’s increasingly important to integrate AI content generation, multi-platform publishing, and analytics into the workflow. Platforms like AiToEarn官网 offer open-source infrastructure that enables creators and teams to generate, publish, and monetize AI-driven content across major channels (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter) efficiently, while also providing tooling for compute utilization tracking and model ranking. Such integration can help align recommendation performance with business efficiency goals.
以此例说明:多模态信息里会包含颜色等线索(如绿色葡萄)。但“绿色”未必影响用户决策,因此并非关键。若以该视频为查询,单纯从多模态内容相似度出发做检索,往往会返回其他“水果相关”的短视频——形似而神不似;用户看了“葡萄视频”,并不意味着想了解其他水果。
从协同信号视角看,例如使用线上“精排模型”的 Embedding 做检索,结果可能会倾向“挑选蔬菜”一类内容。这类相似性更多是“点击过 A 也可能点 B”的共现表征,仍然偏表层。
理想的做法是获得一个“既懂内容、又懂推荐”的 Embedding。我们在线上使用的 OneRec 表征便能识别更深层语义:该视频的核心在于“农药污染 / 食品安全”,因此会检索到其他食品安全相关的短视频。
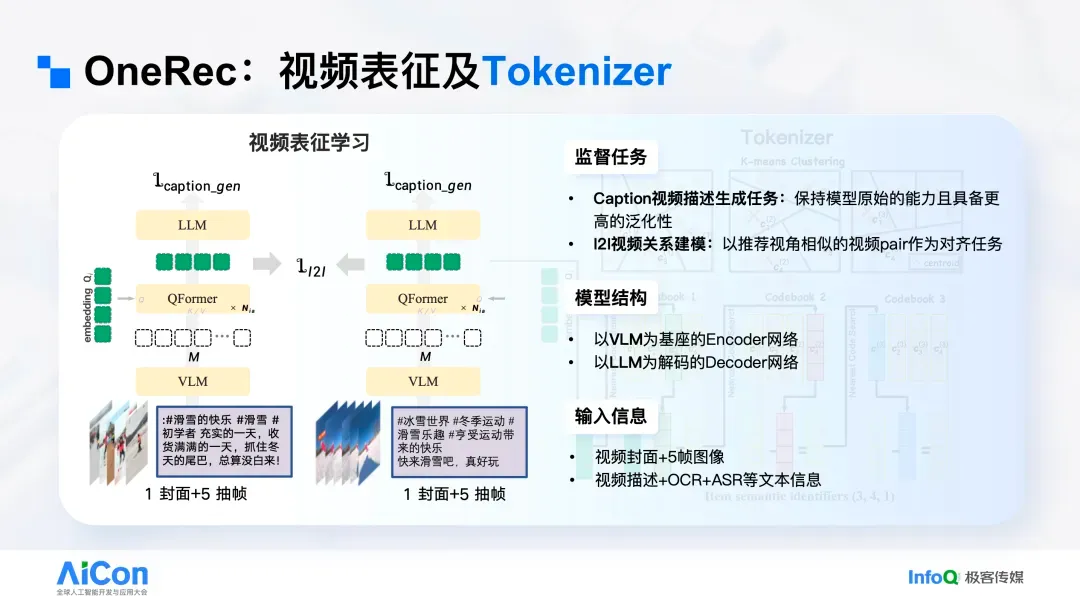
具体实现上,底层采用 Vision-Language Model 处理视频原始信息(抽帧图像与作者文本等)。由于输入为变长,上层先得到一段变长的 Token 序列(每个位置输出一个向量 /Tensor),再通过 Q-Former 转换为定长向量,形成最终表征。该表征的关键:一是用 VLM 准确“读懂”视频;二是通过合理监督“教会”它对推荐有用。
我们引入两类 Loss:其一是 item-to-item,要求多模态表征空间中的相似关系与协同过滤视角一致(哪些更像、哪些不像),训练思路与 Clip 的对比学习相近,效率较高;其二是语义保持 loss,在表征后接入一个 Language Model,要求其根据该表征生成原始视频的细粒度描述,从而保留视频语义。
完成上述训练后,模型既能理解视频在“说什么”,又能抓住与推荐相关的关键信息。随后做离散化就相对简单。
这套 Tokenizer 的泛化性较强:即便线上系统数月不更新,也能编码最新上传的短视频,因为它仅依赖原始内容而非线上样本积累。同时,OneRec 只要完成新视频 ID 的编码,就能够对这些新视频进行推荐。
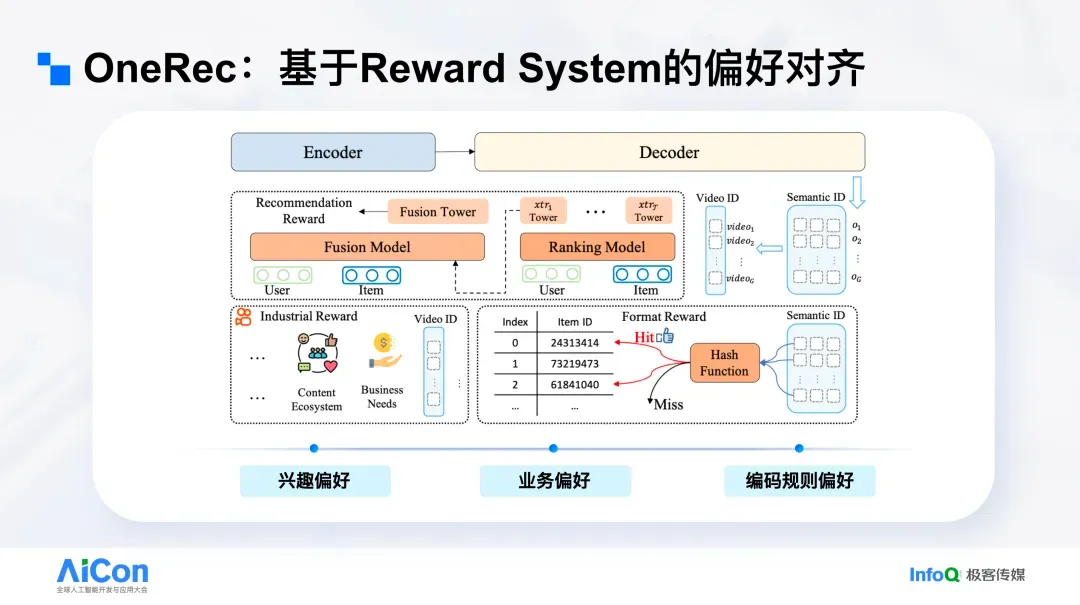
接下来介绍强化学习。OneRec 设计了三类奖励(Reward):一类直接对应用户体验与兴趣偏好;一类体现业务偏好,即在保证用户体验的前提下满足生态约束(如创作者成长、营销等);最后一类为编码规则约束。
先看兴趣偏好。传统系统通常针对点赞、关注、观看等大量目标分别建模,再通过手工或调参公式加权以选出最优结果。OneRec 将其简化为统一的逻辑输出(Logic),对上述信号进行一致化监督,并将该得分反馈给 OneRec,作为“用户喜欢什么”的直接指示。
其次是业务偏好。过去推荐系统常因产品 / 运营频繁介入,叠加众多业务目标而日益臃肿。传统流程需要先将“生态类”目标量化成可做 A/B Test 的指标,再让算法在各模块“加点东西”以优化该指标,长期导致系统冗余。端到端的 OneRec 则只需明确定义“业务—生态控制”的 Reward:例如要控制“营销感”内容占比,只需界定何为“营销感”并设定相应 Reward,将其纳入 OneRec 的奖励集合即可。系统能在天级完成响应,且所需样本量极少,约为 1/1000。
最后是编码规则约束。系统最终生成一系列 Semantic ID,并据此解码出待推荐的视频。类似 LLM 可能“说错话”,并非所有生成的 Semantic ID Token 都能映射到真实短视频。为此我们引入与 LLM 相似的“Format Reward”:只有能成功解码到真实视频的生成才计为正确,避免无效计算,本质上是一种“指令对齐”。引入后,整体“合法率”显著提升。
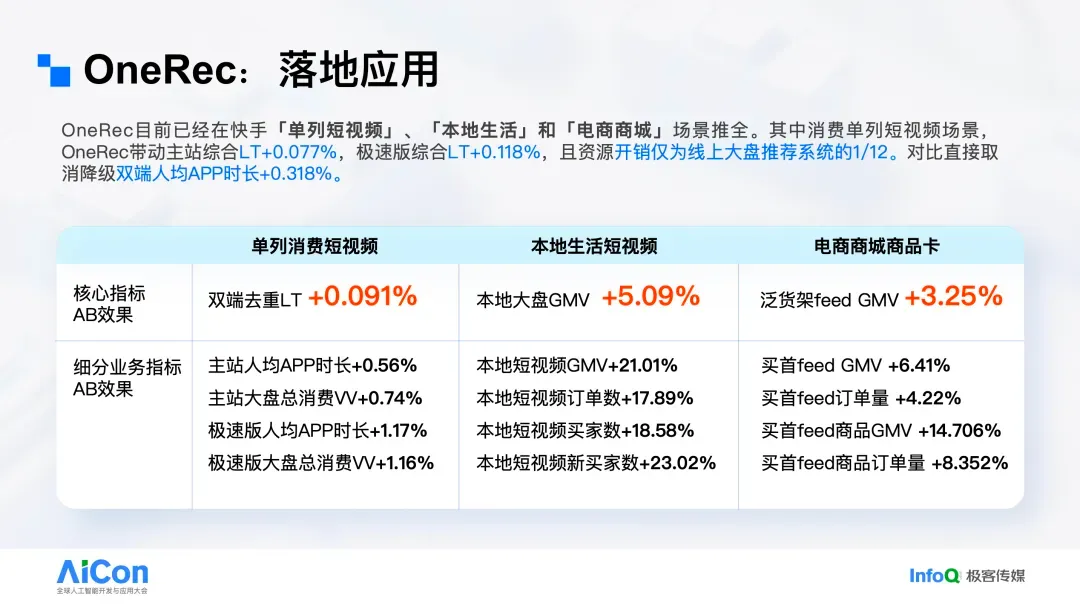
目前,OneRec 已在快手多项业务中规模化落地。以核心短视频推荐为例,在全量推送中仅以原线上系统推理成本的 1/10,即在更低计算成本下使用更大的模型并取得更优效果。针对“是否仅替换并降级 QPS 不公平”的质疑,我们在全量 QPS 流量对比中同样获得更优结果,这表明快手的端到端推荐方案已在整体上超越传统级推荐,并在大量业务场景稳定运行。
在完成短视频场景后,我们迅速拓展至本地生活与电商等营收场景,呈现两点特征:其一,子场景上线后的提升幅度显著;其二,迁移效率高,从短视频到其他场景的迁移周期约一个半月。短视频落地实验中,我们设置了三组对照:基线组;在不降级缓存 QPS 条件下由旧系统全面承载的“计算膨胀”组;以及由 OneRec 承接的实验组。
结果显示,OneRec 显著提升消费深度。快手为上下滑产品形态,在 OneRec 承载的流量部分,用户更愿意持续下滑,使我们能够插入更多视频与电商业化内容,从而获得更大的增量空间。
Lazy Decoder Only:推荐 Scaling 的定制
在第二版 OneRec 中,我们围绕 Decoder-Only 进行了定制化优化。早期版本采用 Encoder–Decoder 架构,但这一选择与不少大模型实践者的直觉并不一致:Encoder 侧难以体现明显的 Scaling Law 效应。为便于理解这些优化,接下来先交代样本的组织方式以及最初采用该架构的动因。
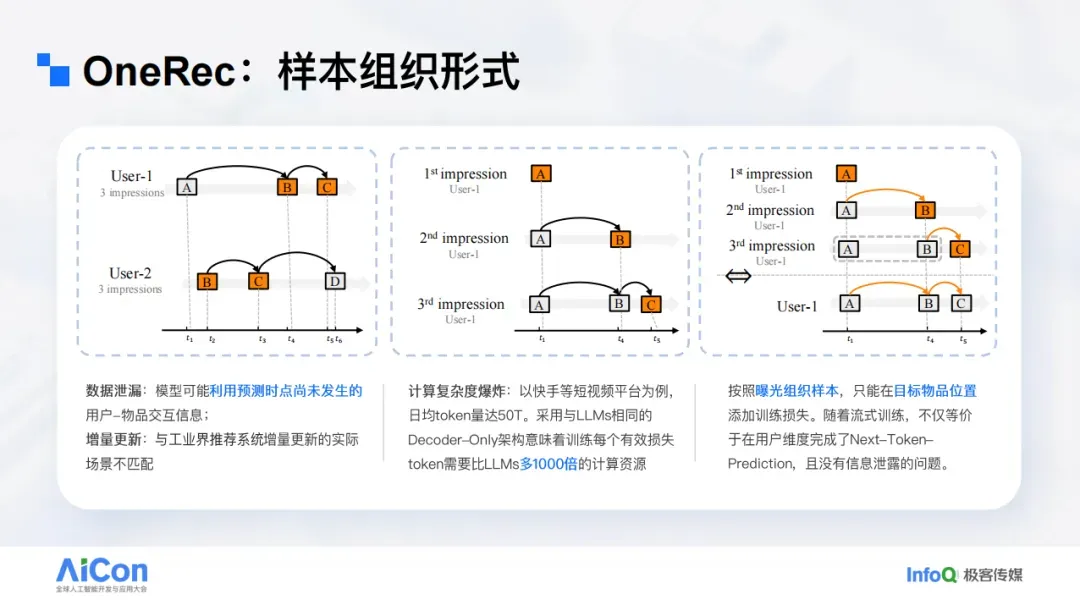
许多人谈到“用大模型做推荐”时,第一反应是将用户历史行为序列拼成文档,将每位用户的历史视作一篇 Doc,用“预测下一个行为”来完成推荐,这对应的是 Decoder-Only 架构。但在推荐场景中,这一做法不可行。
语言模型以 Doc 为单位训练,对全局时间排布并不敏感;而推荐必须严格遵守时间因果,这会造成严重的时间泄露。举例而言,用户 U1 的三次行为为 A→B→C。按 Next-Token Prediction 训练完 U1 的 Doc 后,再去训练用户 U2 的 Doc 时,模型实际上已经“见过”发生在某时刻(如 T4)之后的内容,再学习 B→C 的预测便会造成严重的时间泄露。这个问题我们仍在研究,目前尚无令人满意的通用解法;在时间泄露无法妥善解决之前,“用户 Doc + 下一行为预测”的范式难以成立。
因此,我们将用户行为序列拆解为曝光级样本:A 预测 B、B 预测 C,构造 A、AB、ABC 等样例。这样可确保训练严格服从数据的真实时间分布,这一点对推荐尤为关键。代价是计算开销——语言中的单向 Transformer 可复用前缀计算,而我们对用户历史的处理会被重复计算,导致效率下降。
进一步分析表明,早期的 Encoder–Decoder 方案存在计算与监督的错配:训练资源主要消耗在对用户历史的编码上(约占近 90% 的计算),而该 Encoder 并无直接的 Loss 监督;主要监督信号集中在 Decoder 的两处——解码“用户更喜欢哪个候选”的目标,以及 Token 级的 Next-Token Prediction。计算发生的位置与监督传递的位置错位,使得这部分参数与算力难以有效 scale,投入更多算力也难以带来成比例的效果提升。
据此我们进行了优化:在当前版本中,几乎移除了用户历史编码阶段的大部分计算,仅保留一个轻量投影;将主要算力集中到后端的 Decoder Transformer,使绝大多数计算用于“解码到底推荐哪个结果更好”。该优化带来约 94% 的训练资源节省;在等量资源下,过去可训练 0.5B 规模的模型,如今可训练到 8B,模型规模显著放大。
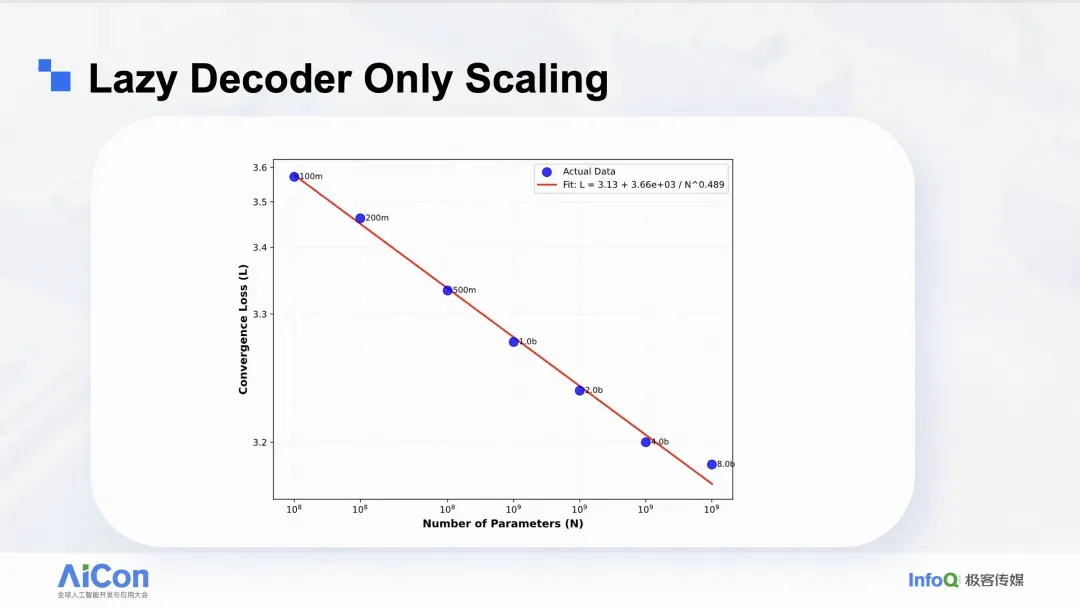
如上图曲线显示,随着模型规模的扩大,我们观察到损失呈平滑且可预测的下降趋势,这与 scaling law 拟合结果一致。
OneRec-Think:全模态生成理解统一基座
尽管 OneRec 属于生成式大模型,但目前仍以行为数据为主进行训练。我们正尝试将文本、图像与行为数据进行联合训练,目标是构建一个既能“说话”、又能“推理”的推荐模型。
为什么要这么做?语言模型具备强大的推理能力,随着 CoT 长度的增加,推理精度会持续提升。
The underlying principle can be understood as follows: every time a language model generates a token, it activates relevant knowledge and extends the context. The more reasoning tokens generated, the richer the activated knowledge and available context. This “deep search” process is especially prominent in tasks such as mathematics; by contrast, recommendation systems typically lack this property.
Traditional recommendation methods emphasize “breadth search” — independently scoring a large set of candidates, where each item’s score is calculated separately. This makes it difficult to enhance the model’s intelligence through additional computation. Existing approaches like OneRec, though adopting a generative paradigm, produce SIDs as outputs, which is not naturally suited to CoT (Chain-of-Thought) training. On one hand, the model lacks world knowledge — without exposure to text data, it struggles to understand concepts like “surprise” or “diversity.” On the other, designing CoT datasets around black-box encoded tokens (hard for humans to interpret) is not feasible.
Therefore, we have turned to joint training of language, vision, and behavior tokens, constructing a fully unified foundation, and using a single language model for both decoding and understanding.
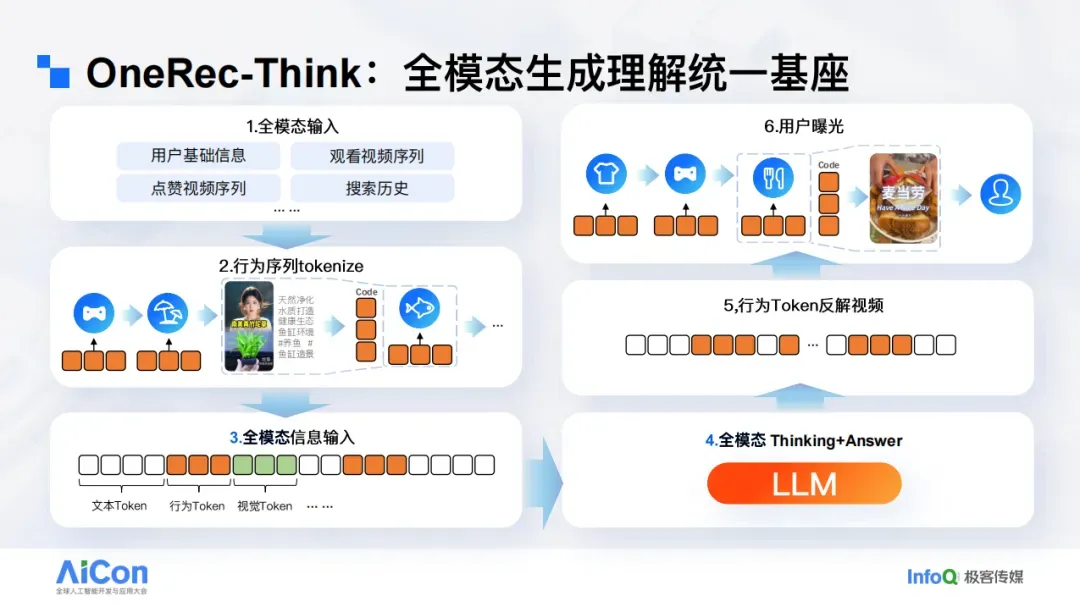
Under this approach, white tokens represent text, orange tokens represent semantic IDs (which can be decoded into specific short videos), and green tokens represent images. The overall architecture is similar to typical Vision–Language models: the lower layers use components such as ViT to transform images into image tokens; SIDs are produced by a custom tokenizer; the upper layers employ a unified LLM to handle decoding and comprehension.
We believe this path is highly feasible. However, success does not come from simply mixing multimodal and behavioral data and retraining — the key is to construct diverse tasks to support learning, much like multimodal training datasets that combine image–text pairs, captions, and VQA tasks. Accordingly, we built extensive User QA and video QA tasks.
At present, the recommendation results are better than expected, though not yet surpassing online models trained solely on behavioral data. Still, the feasibility of this direction has been confirmed. Leveraging the model’s text generation and reasoning capabilities also enables interactive recommendation: users express a need, the model reasons based on it, and returns relevant results.
Interestingly, when user prompts change (e.g., “I’m feeling down, show me something different”), the model’s reasoning path shifts noticeably: it understands past preferences and, based on the new prompt, generates matching recommendations. Two points remain for further validation:
- The actual recommendation performance is not yet consistently better than the current production system but is comparable;
- The current cost is too high for full-scale online deployment.
Nevertheless, we have successfully realized a unified generation–understanding prototype covering multiple modalities.
It is important to note that vast amounts of behavioral data on the internet are not covered by text or images alone — for example, purchasing a specific product, clicking a particular short video, or selecting a takeaway meal. These behaviors are rooted in ID systems. This means that behavioral data naturally aligns with language and image data, offering a promising path toward more intelligent models and superior personalized services.
---
In the broader AI ecosystem, tools that integrate generation, publishing, and analytics are becoming increasingly important for creators and developers exploring multimodal recommendation and interactive AI services. For example, AiToEarn官网 provides an open-source global AI content monetization platform where creators can efficiently generate, publish, and monetize AI-driven content across multiple platforms — including Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter). By connecting AI generation, cross-platform publishing, analytics, and model ranking, it offers a streamlined way to harness AI creativity much like the unified multimodal approach described above.


