Translate the following blog post title into English, concise and natural. Return plain text only without quotes. PB 级数据分钟级恢复:Uber 数据库备份恢复系统演进
介绍
Uber 利用先进的存储技术支持其实时业务,包括将在线数据存储在 MySQL、Apache Cassandra、etcd、Apache Zookeeper 等开源数据库中,以及自研的存储解决方案,例如在 Uber 有状态平台上托管的 Docstore 和 Schemaless。
数据库备份与恢复 对于 Uber 的业务连续性和 灾难恢复 至关重要,支持的场景包括:
- 缓解业务中断
- 从数据损坏中恢复
- 取证与合规性保障
- 模拟生产环境进行负载测试、数据完整性及安全性测试
Uber 的在线存储解决方案规模庞大:
- 数十 PB 数据容量
- 每秒处理 数百万到数十亿次请求
- 备份近 100 PB 数据 可定时执行
- TB 级至 PB 级数据可在 数分钟到几小时 内完成恢复
本篇博客介绍了 Uber 针对在线数据库 增强型备份恢复系统 的最新研发进展。
---
挑战
在 Uber 的业务规模下改进备份恢复系统,需要克服以下困难:
- 原始调度方式落后
- 旧调度方式为周期性尽力执行备份
- 缺乏资源、优先级、速率限制及可观测性考虑
- 导致负载峰值波动,恢复缓慢
- 临时恢复流程
- 流程缺乏系统定义,仅依赖脚本或陈旧操作手册
- 数据库升级后恢复流程容易失效
- 缺乏恢复演练
- 没有定义恢复负载及流程
- 缺少定期演练,功能可靠性无法验证
- 新的恢复目标
- 历史 RPO 为 7–21 天,RTO 从未知到数天
- 经过优化后,大多数数据库的 RPO 缩短至 4–24 小时
- RTO 提升至每小时可恢复 300 TB
---
架构
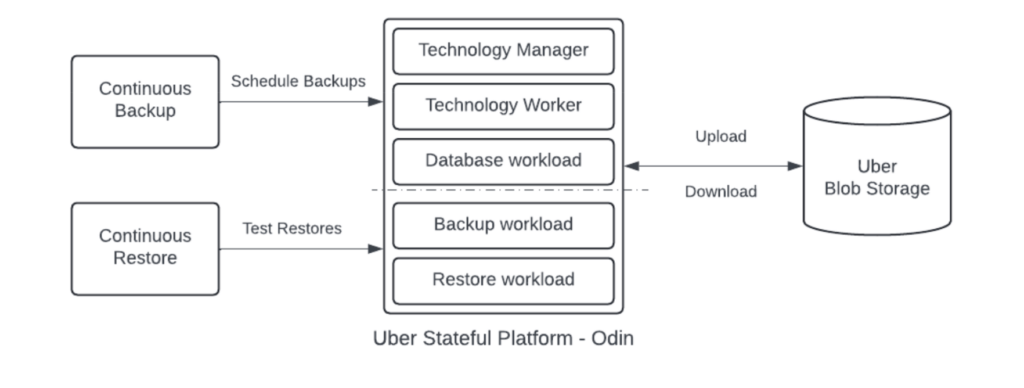
Uber 的增强型备份恢复系统运行于 有状态平台之上,实现统一抽象管理:
- 集中式自适应备份调度:跨数据库集群分配任务,确保网络可靠性与安全性
- 周期性恢复测试:验证备份完整性与恢复流程正确性
- 建立 CBCR(持续备份 持续恢复)框架
该系统采用 快照式备份与恢复架构,提升灾难恢复能力。
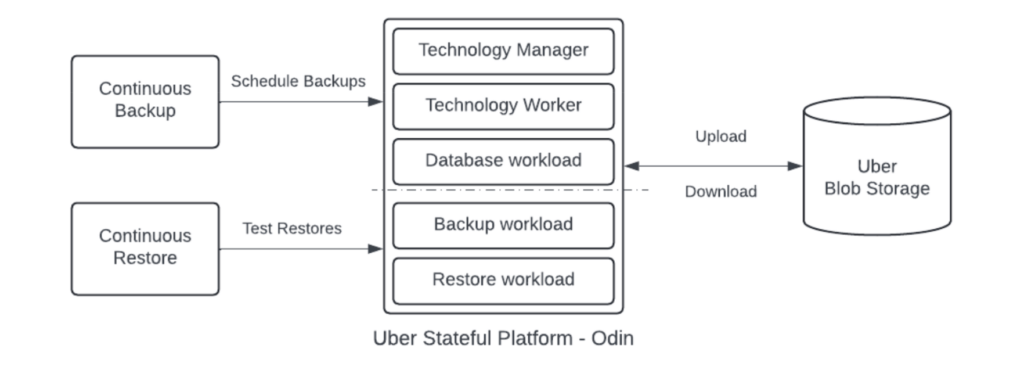
图 1:有状态集群的连续备份恢复
系统组件包括:
- 持续备份协调器:集中配置与调度备份策略,自适应平衡负载
- 持续恢复协调器:集中配置恢复策略,定期验证备份正确性
- 备份框架:统一驱动整合技术插件,执行快照逻辑并上传至 Uber Blobstore
- 恢复框架:统一驱动整合技术插件,下载备份并加载至数据库
- 技术工作负载组件:包括管理器节点、数据库负载及业务关键辅助负载
- Uber Blobstore:面向大规模的对象存储虚拟化层,具备策略配置能力
---
持续备份
Time Machine 是持续备份框架的核心,具备全局自适应调度能力:
- 每日上传 数 PB 数据
- 与核心业务带宽共享,不影响服务可用性
- 通过最优选择引擎与速率限制,实现智能备份决策
决策依据包括:
- 备份新鲜度标准
- 网络/主机动态可用性
- 历史备份趋势
- 企业带宽峰谷差
- 针对不同技术的速率策略与优先级
- 地理位置及可用性
流程阶段:
- 发现:扫描集群,收集全部可备份数据库
- 选择:应用规则筛选,适应基础设施状况
- 触发:决定完整/增量模式,启动技术特定备份任务
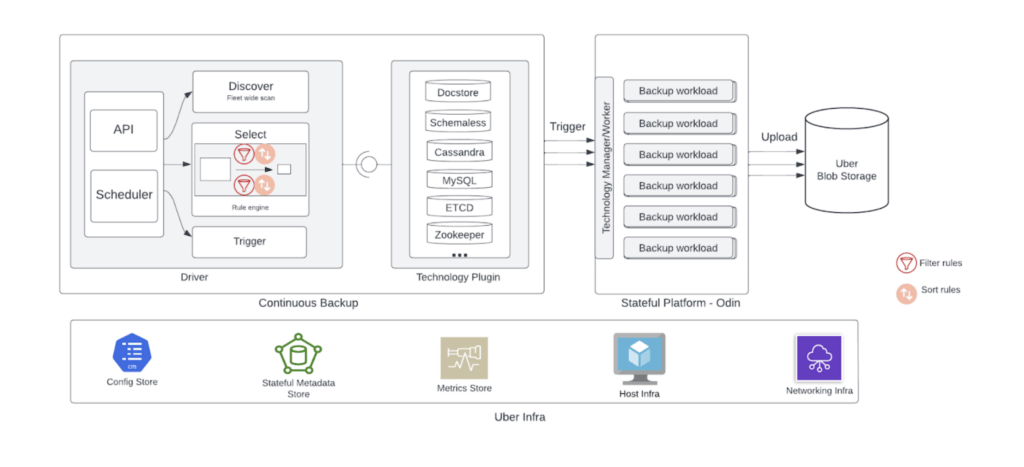
图 2:有状态平台上的持续备份
---
备份框架
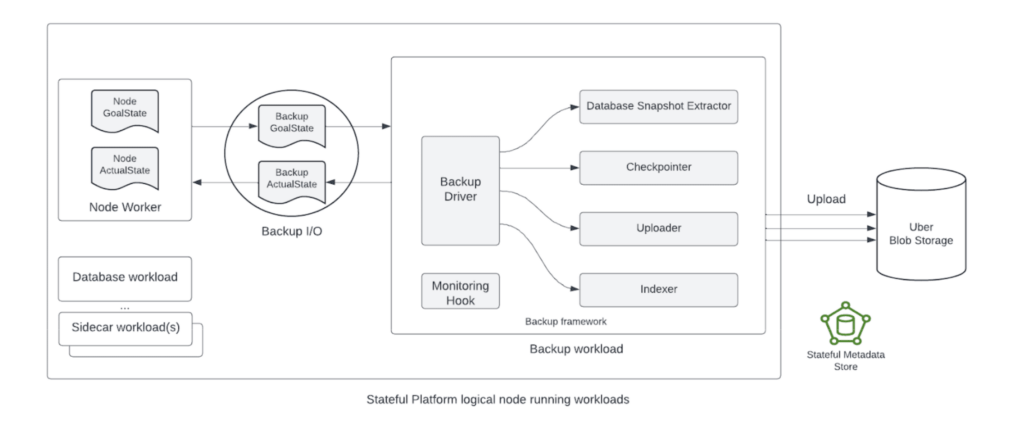
图 3:备份框架控制流程
统一备份驱动与技术插件配合实现:
- 数据快照提取
- 增量上传与速率限制
- 数据完整性检查
- 上传索引生成去重
- 钩子监控防止生产负载中断
- 快照文件清理以控制磁盘使用
技术适配示例:
- MySQL / Docstore / Schemaless:基于 Percona Xtrabackup,增强差异备份逻辑
- Cassandra:基于 nodetool snapshot,类似 Medusa 差分策略
- etcd:基于 etcd-clientv3 获取时间点快照
- Zookeeper:备份最新 `snapshot.` 文件
---
Restore Framework
恢复框架设计与备份框架相似,具备 技术无关性 与 自动化能力:
- 模块化架构,适配多种数据库
- 无需人工干预,减少时间与风险
- 驱动程序结合数据库特定插件实现恢复逻辑
技术实例:
- MySQL:使用 Percona XtraBackup 提取与准备数据
- Cassandra:下载并加载 SSTables
- etcd / Zookeeper:恢复快照至对应目录并使用专用加载库
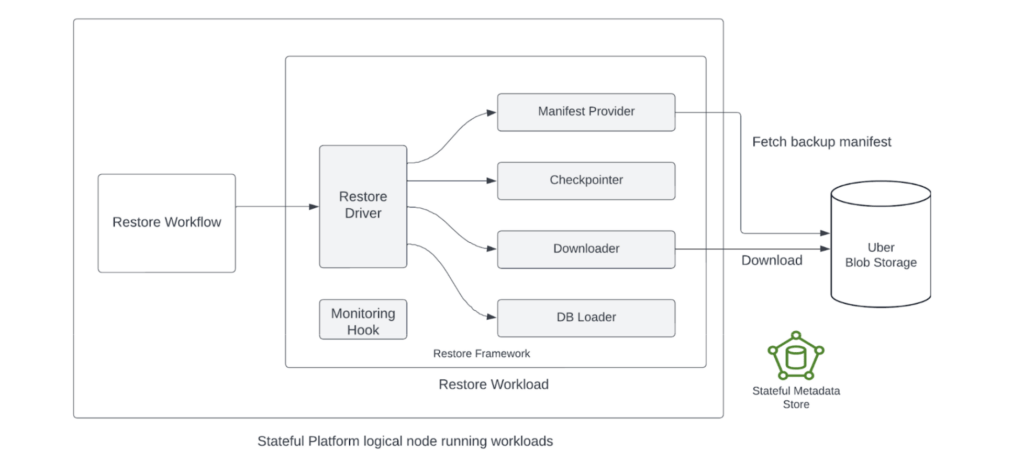
图 4:恢复框架控制流程
---
持续恢复
持续恢复框架通过频繁验证恢复后的数据,确保备份可用性与正确性:
- 智能调度:可设置定期或临时测试任务
- 验证策略:
- 专用测试:使用已知数据全流程恢复
- 随机测试:选取生产规模数据库模拟真实条件
- 数据验证:完整性检查、字节对比、性能与成功率统计
- 报告输出:提供恢复结果与性能分析,支持合规审计
流程阶段:
- 发现/选择:根据策略选取数据库并均衡负载
- 触发:创建测试集群并执行恢复
- 验证:对比已知数据或检测完整性
- 报告:输出测试报告并清理资源
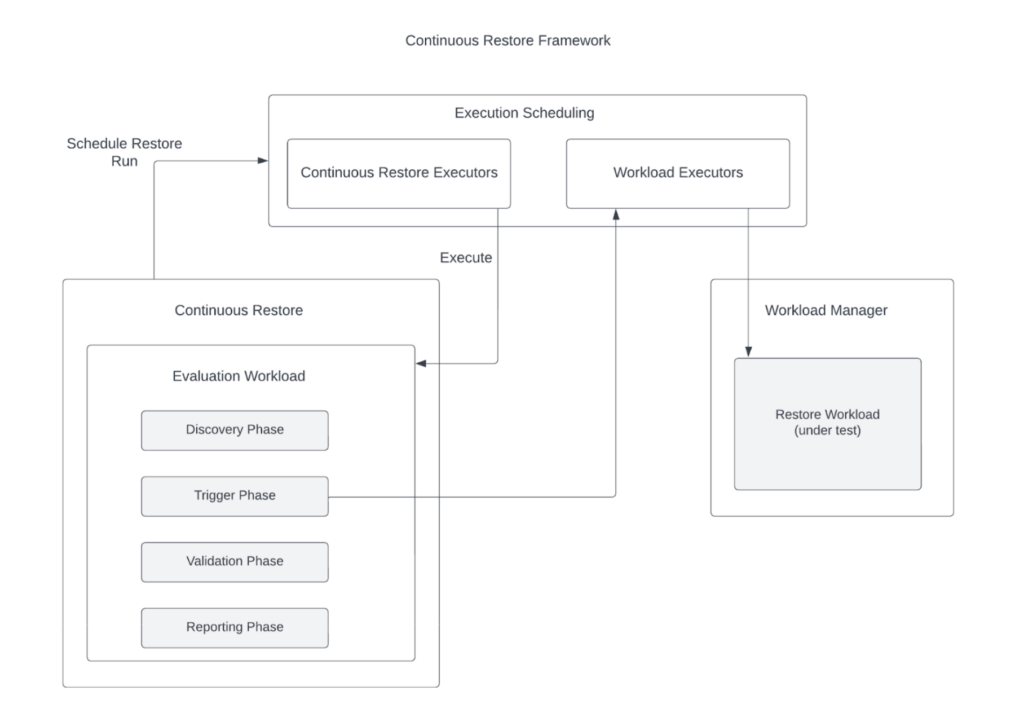
图 5:有状态集群中的持续恢复框架
优势:
- 高弹性,降低停机风险
- 满足合规与审计需求
- 提升数据可靠性
- 提供可操作性改进建议
---
作者:Uber Backend
编译:Rio
来源:官方博客
dbaplus 投稿邮箱:editor@dbaplus.cn


