Translate the following blog post title into English, concise and natural. Return plain text only without quotes. 今日开源(2025-12-1):英伟达发布 Nemotron-Flash,实现推理速度与精度双突破,重新定义小参数量模型性能边界
原创 每日发现最新LLM 2025-12-01 17:05 中国香港
混合小型语言模型家族Nemotron-Flash,大型视觉语言模型Spatial-SSRL,框架DynaAct,归因框架Decomposed-Forward-Pass,强化学习框架VisPlay,新颖的方法REG

🏆基座模型
①项目:Nemotron-Flash
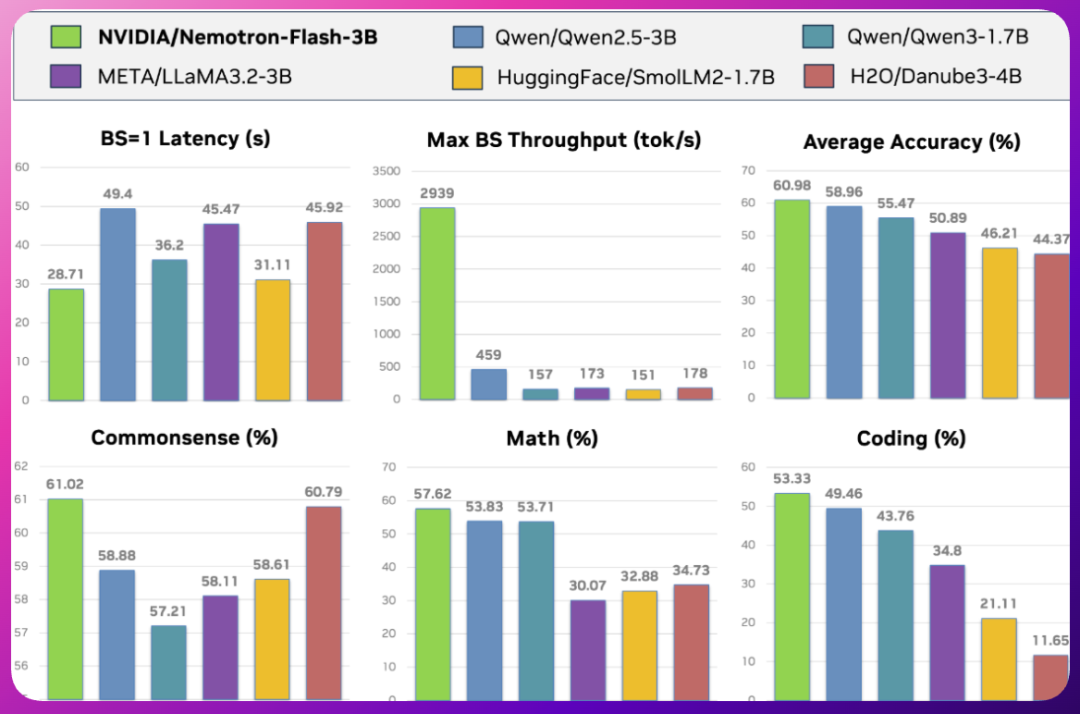
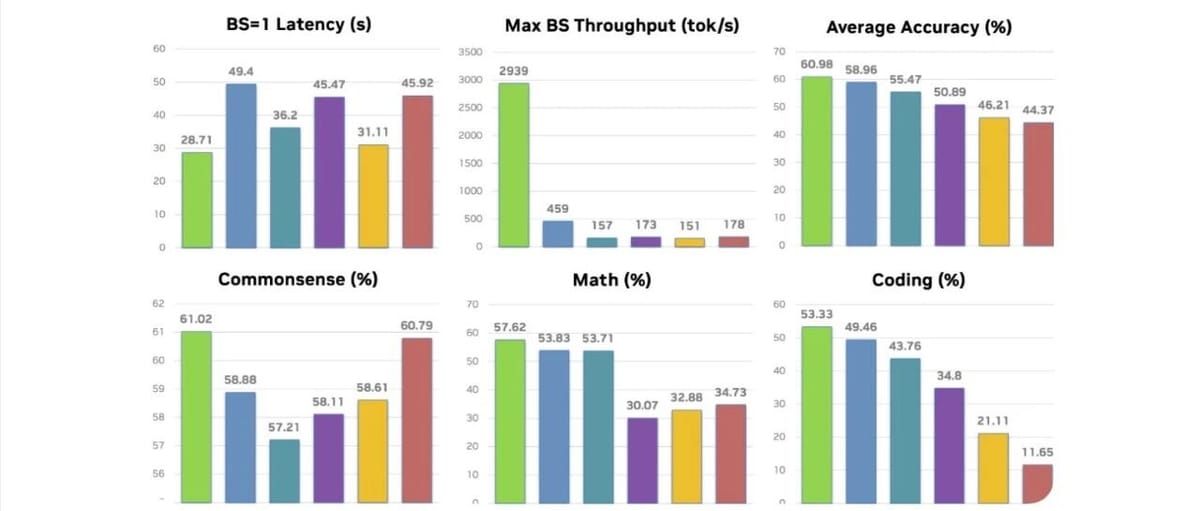
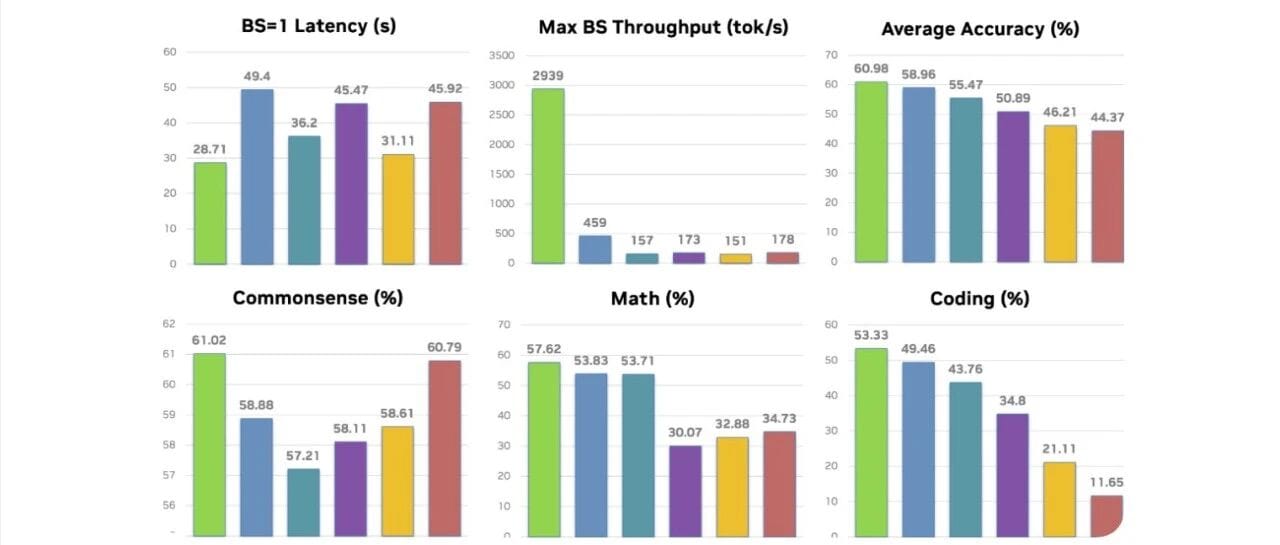
★Nemotron-Flash 是一个新型的混合小型语言模型家族,设计重点在于实际延迟而非参数数量。其特点包括延迟优化的深度-宽度比、通过进化搜索发现的混合操作符以及训练时的权重归一化。该模型在1B和3B规模上在数学、编码和常识推理方面达到了SOTA精度,同时提供了良好的小批量延迟和大批量吞吐量。
☆一键收藏:
https://sota.jiqizhixin.com/project/2nemotron-flash
②项目:Spatial-SSRL
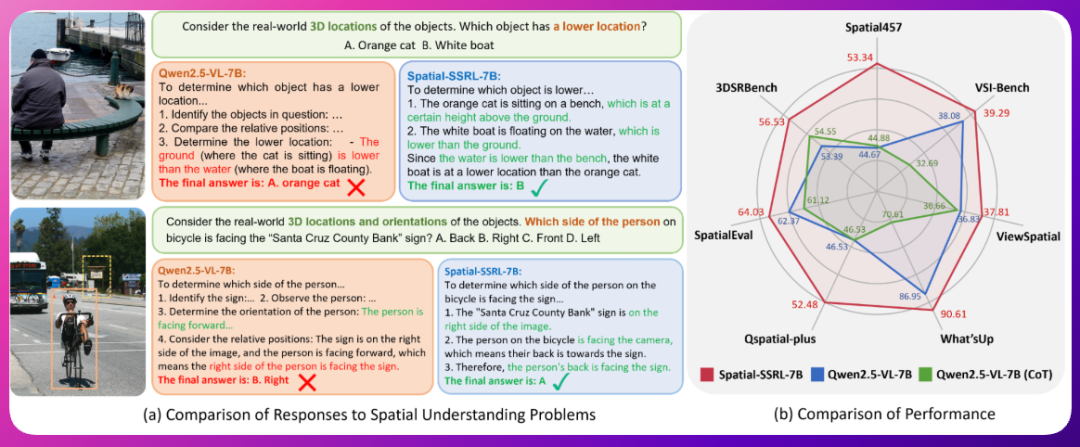
★Spatial-SSRL 是一个大型视觉语言模型,专注于空间理解。该模型基于 Qwen2.5-VL-7B,通过应用 Spatial-SSRL 这一轻量级自监督强化学习范式进行优化。该模型在保持基础模型的通用视觉能力的同时,展示了强大的空间智能。
☆一键收藏:
https://sota.jiqizhixin.com/project/spatial-ssrl
🛠️ 框架平台、必备工具
①项目:DynaAct
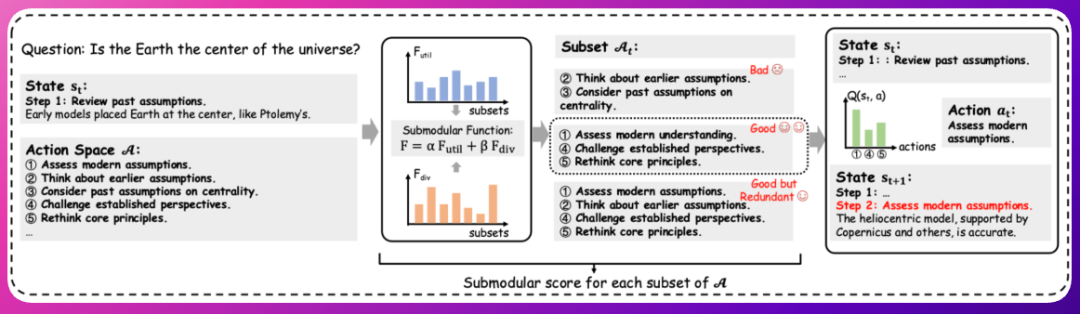
★DynaAct是一个框架,旨在通过动态构建紧凑的动作空间来增强大型语言模型(LLMs)的序列推理能力。它引入了一种基于子模函数的优化方法,能够同时最大化效用(与当前推理状态的相关性)和多样性(非冗余的推理方向)。这种动态动作选择使得LLMs能够更高效地思考,专注于最具信息量的推理步骤,同时保持较低的推理延迟。
☆一键收藏:
https://sota.jiqizhixin.com/project/dynaact
②项目:Decomposed-Forward-Pass

★Decomposed-Forward-Pass是一个模块化且可扩展的归因框架,用于分析基于变压器的语言模型。它支持任意粒度的归因,通过允许从变压器模型的任何组件初始化和传播归因信号。在此实现中,我们展示了几个代表性用例,包括令牌级、神经元级、模块级(MLP或注意力)、头级和自定义子空间级归因,从而实现对注意力和前馈层内部机制的细粒度解释。
☆一键收藏:
https://sota.jiqizhixin.com/project/2decomposed-forward-pass
③项目:VisPlay

★VisPlay是一个自我进化的强化学习框架,旨在提升视觉语言模型(VLMs)的推理能力。该项目通过从大量未标记的图像数据中自主改进模型的推理能力。VisPlay将模型分配为两个交互角色:图像条件提问者和多模态推理者,并通过群体相对策略优化(GRPO)进行联合训练。VisPlay在多个基准测试中展示了其在视觉推理、组合泛化和幻觉减少方面的显著改进。
☆一键收藏:
https://sota.jiqizhixin.com/project/visplay
④项目:Representation Entanglement for Generation (REG)
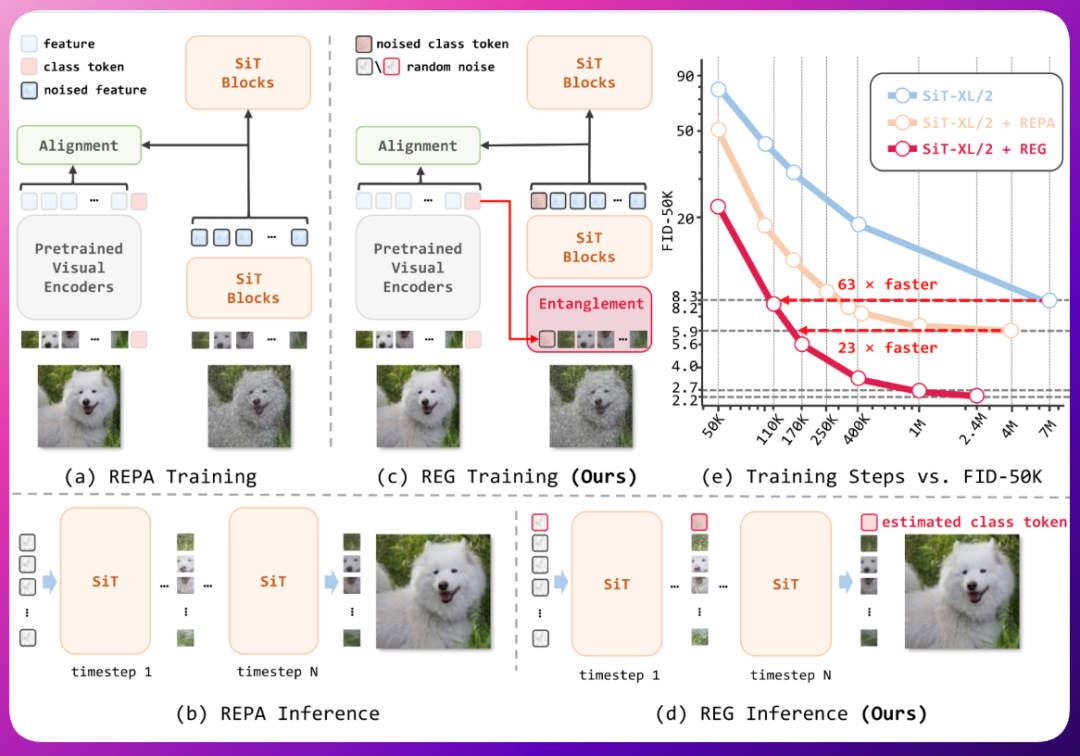
★Representation Entanglement for Generation (REG) 是一种新颖的方法,通过将低级图像潜在变量与预训练基础模型中的单个高级类标记纠缠在一起,来改善扩散模型的训练。该方法能够从纯噪声中直接生成一致的图像-类对,大幅提高生成质量和训练效率。REG 的推理过程同时重建图像潜在变量及其对应的全局语义,所获取的语义知识积极引导并增强图像生成过程。在 ImageNet 数据集上,REG 显示出显著的收敛加速效果,训练速度比传统方法快 63 倍。
☆一键收藏:
https://sota.jiqizhixin.com/project/reg2