## Authors and Affiliations
The team behind this work comes from **Tsinghua University**, **Peking University**, **Wuhan University**, and **Shanghai Jiao Tong University**.
**Primary authors**:
- **Chengbo Yuan** – Master’s student, Tsinghua University
- **Rui Zhou** – Undergraduate student, Wuhan University
- **Mengzhen Liu** – PhD candidate, Peking University
- **Yang Gao** – Assistant Professor, Tsinghua University (Corresponding Author, Institute for Interdisciplinary Information Sciences)
---
## Background: Advancing Motion Transfer
Recently, **Google DeepMind** released the next-generation embodied large model **Gemini Robotics 1.5**, introducing an *end-to-end Motion Transfer Mechanism (MT)* — enabling robots of different morphologies to transfer skills without retraining.
However, publicly available documentation contains only limited details.
While the industry speculates on MT’s inner workings, this **joint academic team** has taken the concept further:
> **Direct zero-shot motion transfer from human VR data to robots.**
Notably, the team has made their **full technical report, training code, and pretrained weights open-source** — ensuring complete reproducibility.
---
- **Paper**: [https://arxiv.org/abs/2509.17759](https://arxiv.org/abs/2509.17759)
- **Project Homepage**: [https://motiontrans.github.io/](https://motiontrans.github.io/)
- **Source Code**: [https://github.com/michaelyuancb/motiontrans](https://github.com/michaelyuancb/motiontrans)

---
## MotionTrans Framework Overview

**MotionTrans** is the industry’s first **pure end-to-end** *Human → Robot Zero-Shot RGB-to-Action* skill-transfer framework — bridging the gap from *"I can watch it"* to *"I can do it."*
### Key Capabilities
- **Zero-shot transfer**
- Performs tasks **with no robot-specific demonstrations**
- Relies solely on human VR recordings
- Examples: pouring water, unplugging sockets, shutting down computers, storing objects
- **Few-shot refinement**
- With **5–20 robot-specific samples**, task success rates improve markedly across 13 human-derived skills
- **End-to-end, architecture-agnostic**
- Works with both **Diffusion Policy** and **VLA paradigms**
- Fully decoupled from robot model architecture
- Validated as **plug-and-play** across different control frameworks
---
## How MotionTrans Works
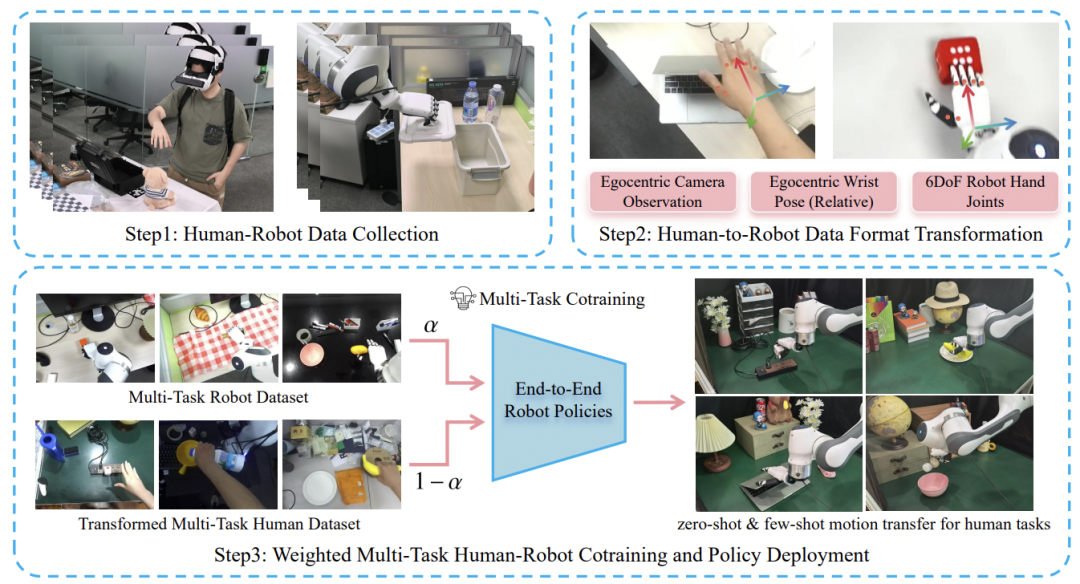
### Data Collection & Processing
The team developed a portable, open-source **VR-based human data collection system** supporting:
- First-person video capture
- Head movement tracking
- Wrist pose recording
- Hand action detection
### Transforming Human Data for Robots
1. **First-Person Video Alignment**
Human and robot datasets both use first-person views as input.
2. **Relative Wrist Pose Representation**
Captures wrist movement in a way that’s compatible across embodiments.
3. **Dex-Retargeting for Hands**
Uses *Dex-Retargeting* to map human hand gestures onto robot joint motions.
---
## Advanced Techniques
The framework introduces:
- **Unified Action Normalization** – Common representation across human and robot actions.
- **Weighted Human–Robot CoTraining** – Combines human and robot data for higher transfer fidelity.
Adopted architectures:
- **Diffusion Policy**
- **VLA Models**
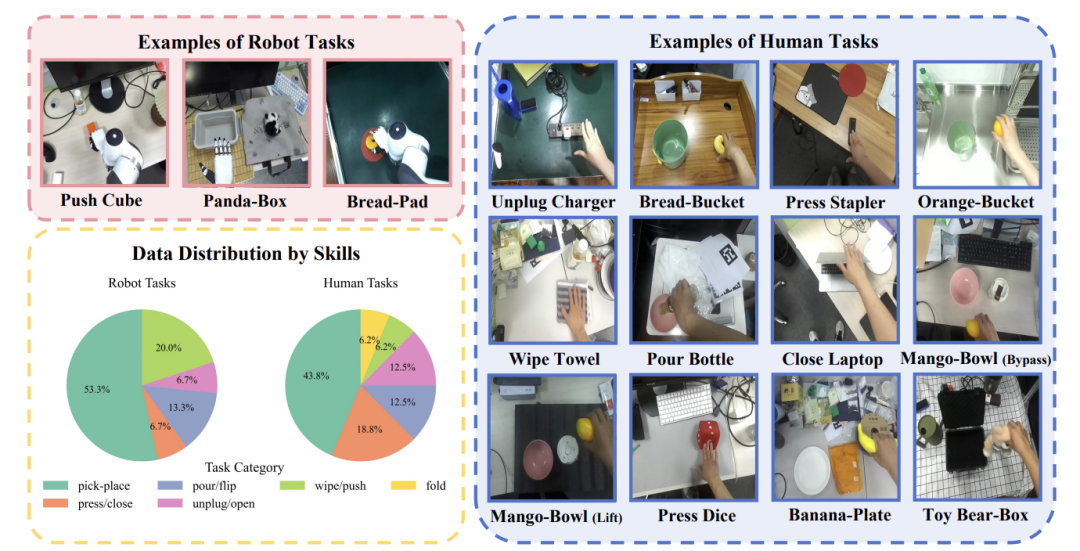
### Dataset Highlights
- **3,200+ trajectories**
- **15 robotic tasks**
- **15 distinct human tasks**
- **10+ real-world scenarios**
---
## Zero-Shot Performance
### Evaluation
- Deployed tasks from the *human set* directly to robots
- **No robotic demonstrations** collected for those tasks
**Results**:
- **Average success rate**: ~20% across 13 tasks
- **Pick-and-Place tasks**: 60–80% success rate
- **VLA model**: 100% one-shot success for *"Shut down computer"*
- Complex tasks (unplugging sockets, opening boxes, obstacle avoidance) showed notable success rates
Even in 0% success cases, models learned correct directional actions — e.g., pushing forward in table wiping tasks — proving semantic understanding of goals.

---
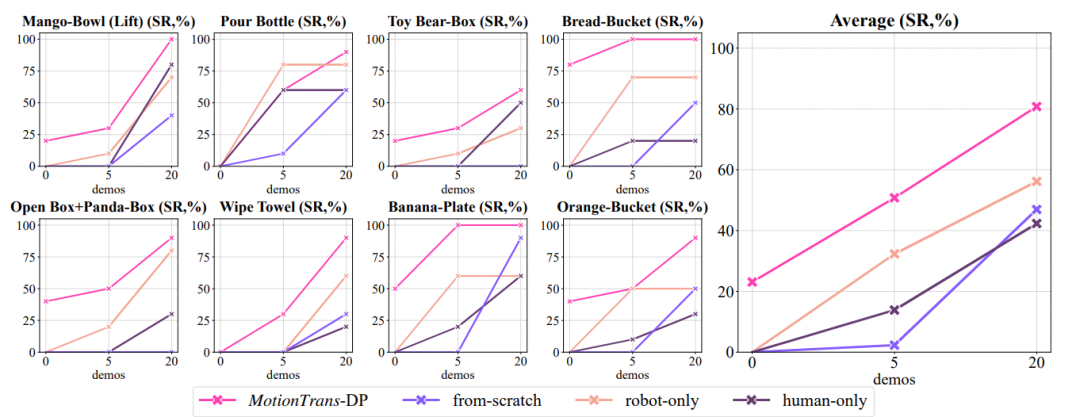
## Fine-Tuning Performance
### Few-Shot Refinement
- **5 robotic trajectories per task**
- Average success rate: ~50% (up from 20% baseline)
- **20 robotic trajectories per task**
- Average success rate: ~80%
**Additional Findings**:
- Joint human–robot training beats baseline methods
- Extensive ablation studies confirm framework design and working principles
---
## Key Insight: Human Data as a Primary Learning Source
MotionTrans demonstrates:
- Even state-of-the-art VLA models can learn **new tasks directly from human VR data**
- Human data can serve as **the main source** of knowledge — not merely a supplemental “seasoning”
**Framework workflow**:
1. **Collect**
2. **Transform**
3. **Train**
With larger datasets or higher-capacity models, scaling horizontally is straightforward.
---
## Open Source & Future Directions
The team has made:
- **All datasets**
- **Source code**
- **Trained models**
available to the public.
This philosophy mirrors the adaptability and multi-platform scalability seen in projects such as **[AiToEarn官网](https://aitoearn.ai/)** — an AI-powered content generation and distribution tool supporting platforms like:
- Douyin
- Kwai
- WeChat
- Bilibili
- Xiaohongshu (Rednote)
- Facebook
- Instagram
- LinkedIn
- Threads
- YouTube
- Pinterest
- X (Twitter)
Pairing open-source robotics research with such cross-platform ecosystems could accelerate **real-world adoption of human-to-robot skill transfer**.
---