Tsinghua & Giant Network Pioneer MoE Multi-Dialect TTS Framework with Fully Open-Source Data, Code, and Methods

🌍 Preserving Dialects with Open-Source Speech Synthesis


Dialects — whether Cantonese, Minnan, Wu in Chinese, Dutch Bildts, French Occitan, or local languages in Africa and South America — are rich in phonetic systems and cultural heritage. Sadly, many are disappearing quickly. If speech technologies fail to support these dialects, the digital divide will deepen and cultural loss will accelerate.
The Challenge
Large-model-driven general TTS (Text-to-Speech) systems have made huge strides, but dialect TTS remains a gray area:
- Industrial-grade models rely heavily on proprietary datasets
- Few unified methods exist for building dialect corpora
- No open-source end-to-end frameworks handle multiple dialects effectively
---
💡 Introducing DiaMoE-TTS
To address these gaps, research teams from Giant Network AI Lab and Tsinghua University’s SATLab created DiaMoE-TTS — a fully open-source dialect TTS solution with performance comparable to industrial models.
Key Innovations:
- Unified IPA representation system for cross-dialect consistency
- End-to-end pipeline using only open-source dialect ASR data
- Validated across multiple languages (English, French, German, Dutch Bildts) before Chinese dialect deployment
---
📦 Full-Chain Contributions
DiaMoE-TTS is more than just a model — it's a complete research and community toolkit:
- Open-source data preprocessing workflows: Convert raw dialect audio into TTS-ready corpora
- Unified IPA annotation & alignment methods: Ensure phonetic consistency across dialects
- Complete training and inference code: Lower replication barriers
- Dialect-aware Mixture-of-Experts architecture: Maintain distinct dialect traits and adapt to low-resource scenarios
🎯 Mission: Promote fairness and inclusivity in dialect technology — enabling researchers, developers, and preservationists to freely use, improve, and expand the framework.

---
📄 Resources
Paper:
DiaMoE-TTS: A Unified IPA-Based Dialect TTS Framework with Mixture-of-Experts and Parameter-Efficient Zero-Shot Adaptation
Code:
Data:
---
🌟 Example Dialect Outputs
- Chengdu dialect: Wishing everyone a bright future and smooth sailing.
- Zhengzhou dialect: Wish you a great future and extraordinary achievements!
- Shijiazhuang dialect: A good start is half of success.
- Xi’an dialect: Wishing everyone a bright future and dreams come true.
- Cantonese: I love springtime in Guangzhou.
---
🧩 Model Design
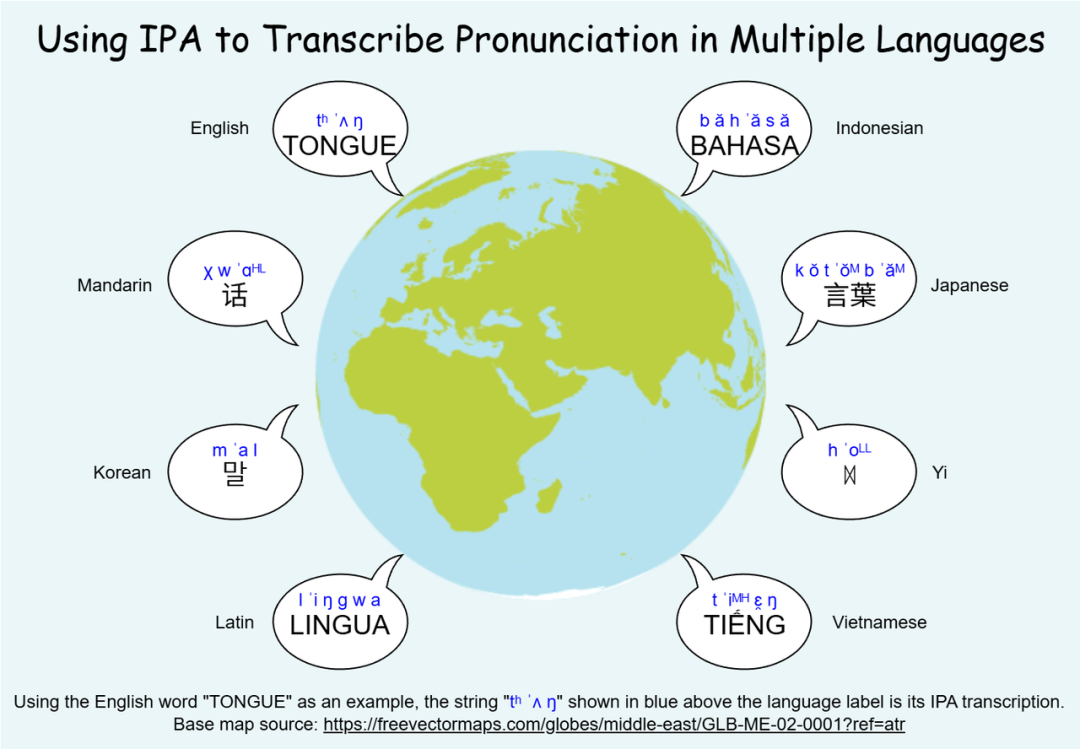
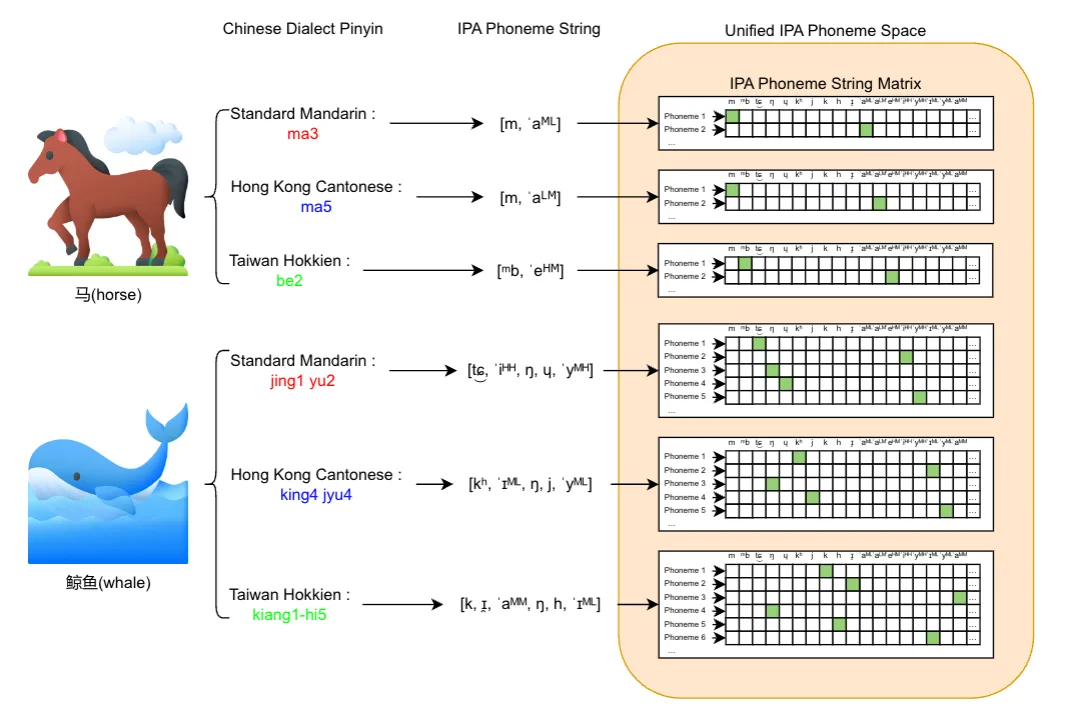
1. Unified IPA Frontend
Using pinyin or characters often leads to pronunciation ambiguities.
Solution: Map all dialect speech into a single IPA phoneme space to ensure consistency & generalization.
---
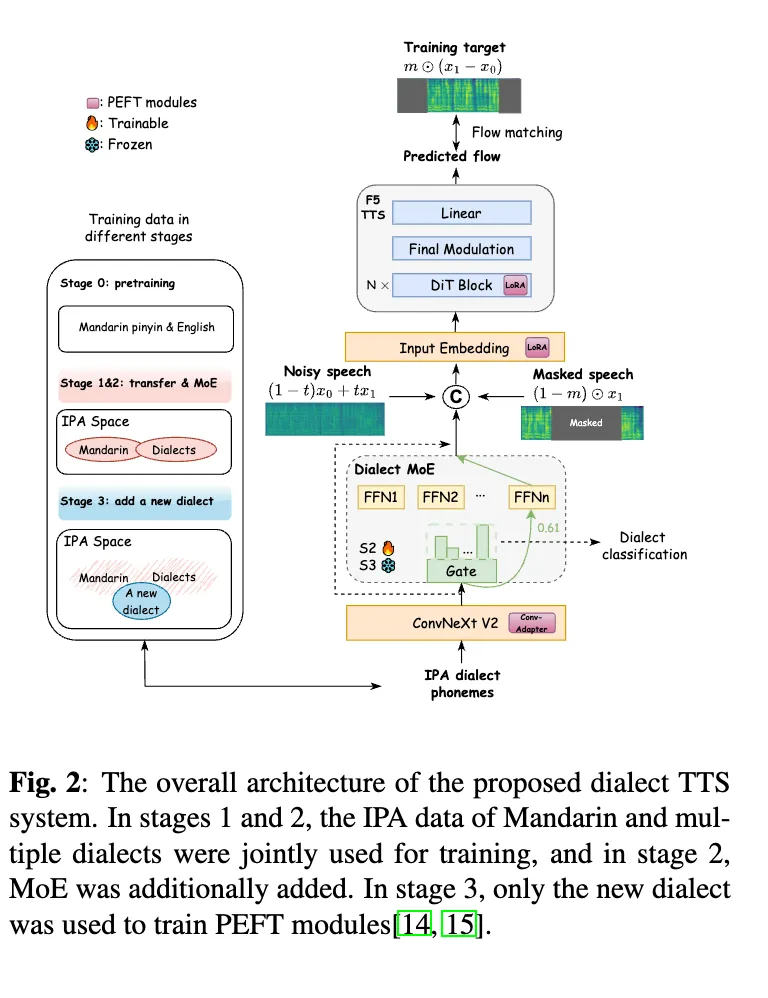
2. Dialect-Aware Mixture-of-Experts (MoE)
Traditional single-network multi-dialect models suffer from style averaging.
Solution: Multiple expert networks, each dedicated to a dialect, with dynamic gating based on IPA input.
A dialect classification auxiliary loss improves the gating’s ability to select the correct expert.
---
3. Low-Resource Dialect Adaptation (PEFT)
For dialects with only a few hours of data:
- Conditioning Adapter + LoRA in text embeddings and attention layers
- Fine-tune only small parameter sets — keep backbone frozen
- Pitch & speaking rate perturbations for data augmentation
Result: Natural, fluent, distinctive speech even in ultra-low-resource cases.
---
📚 Multi-Stage Training Method
- IPA Transfer Initialization
- Start from F5-TTS checkpoint
- Emilia data converted to IPA for warm-up training
- Smooth transition from pinyin to IPA
- Multi-Dialect Joint Training
- Use unified IPA
- Train on CommonVoice + KeSpeech datasets
- Activate MoE for distinguishing dialect features
- Dialect Expert Refinement
- Optimize gating via auxiliary dialect classification loss
- Low-Resource Rapid Adaptation
- Apply LoRA + Conditioning Adapter + pitch/speed augmentation
---
🔬 Research Results
High-resource case (Cantonese): WER, MOS, and UTMOS near industrial-grade models.
Low-resource cases (Shanghainese, Chengdu, Xi’an, Zhengzhou, Tianjin): Slightly lower due to dataset quality/scale limits.
---
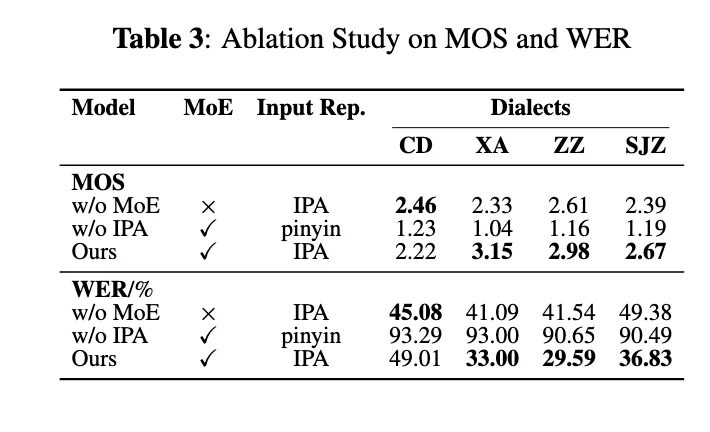
📊 Ablation Studies
Tested Dialects: Chengdu, Xi’an, Zhengzhou, Shijiazhuang
Compared Configurations:
- IPA without MoE (`w/o MoE`)
- MoE with pinyin (`w/o IPA`)
- Full IPA + MoE (`Ours`)
Findings:
- IPA dramatically reduced WER (from >90% to ~30–40%)
- MoE further boosted style fidelity and reduced error rates
---
📝 One-Sentence Summary
DiaMoE-TTS = IPA frontend unification + MoE dialect modeling + PEFT low-resource adaptation
👉 A low-cost, scalable, open-data-driven multi-dialect speech synthesis solution.
---
🔮 Future Outlook
The team plans to:
- Expand corpora to more dialects and minority languages
- Improve IPA alignment & preprocessing pipelines
- Develop more efficient low-resource strategies
Goal: Make dialect TTS lower-barrier, reproducible, and deployable in real-world applications — from education and heritage conservation to virtual humans and digital tourism.
---
🌐 Synergy with Publishing Platforms
Tools like AiToEarn官网 can integrate DiaMoE-TTS outputs into multi-platform publishing & monetization, reaching platforms like Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X/Twitter.
By combining open-source speech synthesis and AI publishing/ecosystem tools, creators can amplify local voices globally — preserving culture while creating sustainable digital content streams.
---
Would you like me to also prepare a compact executive summary version of this Markdown so it’s easier to share in press releases and GitHub READMEs? That way you’ll have both this detailed version and a concise one.



