Uber’s Pinot Query Overhaul: Streamlined Layers and Improved Observability

Uber Redesigns Apache Pinot Query Architecture for Simpler Execution and Improved Predictability
Uber has redesigned its Apache Pinot query architecture to:
- Simplify execution
- Support richer SQL capabilities
- Improve predictability for internal analytical workloads
The prior Neutrino system, which layered Presto on top of Pinot, has now been replaced with a lightweight proxy called Cellar, leveraging Pinot’s Multi-Stage Engine Lite Mode. The goal is reduced complexity, stricter query limits, and stronger multi-tenant isolation.
---
Transition: From Neutrino to Cellar
Previous Architecture — Neutrino
- Stateless microservice combining Presto coordinator and worker processes
- PrestoSQL queries partially pushed to Pinot as PinotSQL
- Remaining query logic executed within Neutrino
- Enforced default or user-defined limits to avoid full table scans
Drawbacks:
- Added semantic complexity in query planning
- Limited isolation between tenants sharing the same proxy
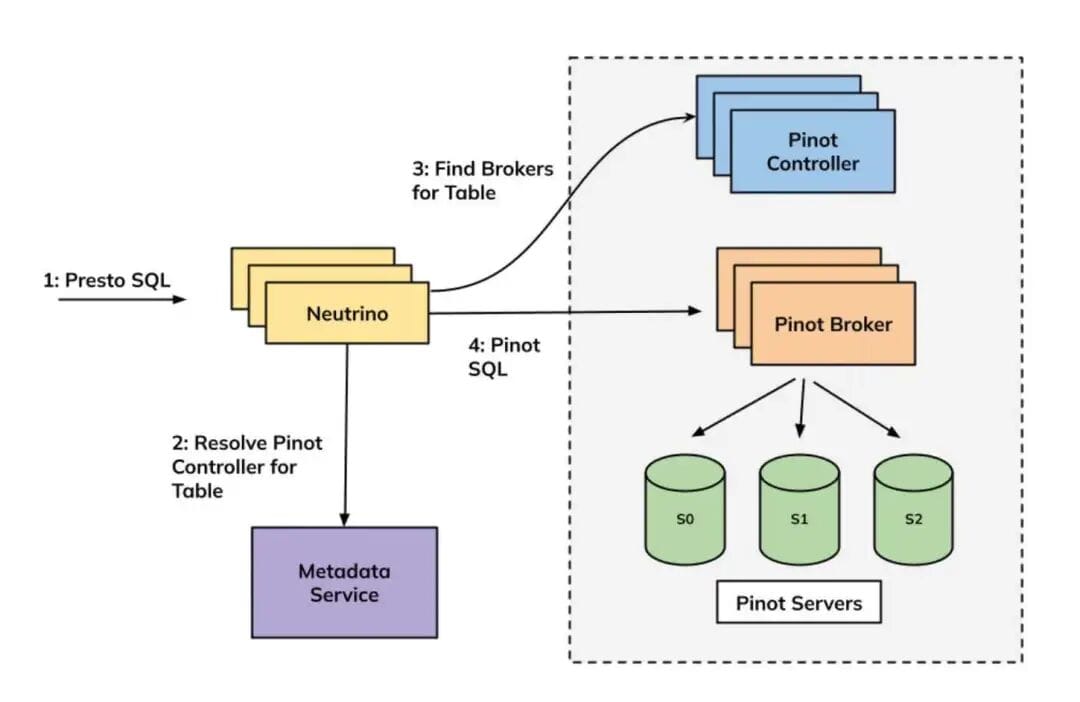
Uber’s Neutrino query architecture — source: Uber blog
---
Scaling Challenges
Uber’s Pinot environment:
- Tables up to hundreds of terabytes
- Billions of records
- Query rates from single-digit QPS to thousands QPS
At this scale, multi-stage queries can easily exceed latency or resource budgets.
Pinot 1.4 — Lite Mode Features
- Configurable record limits at leaf stages
- Scatter-gather execution:
- Leaf stages on Pinot servers
- Remaining operators execute on the broker
- Predictable performance for complex queries
---
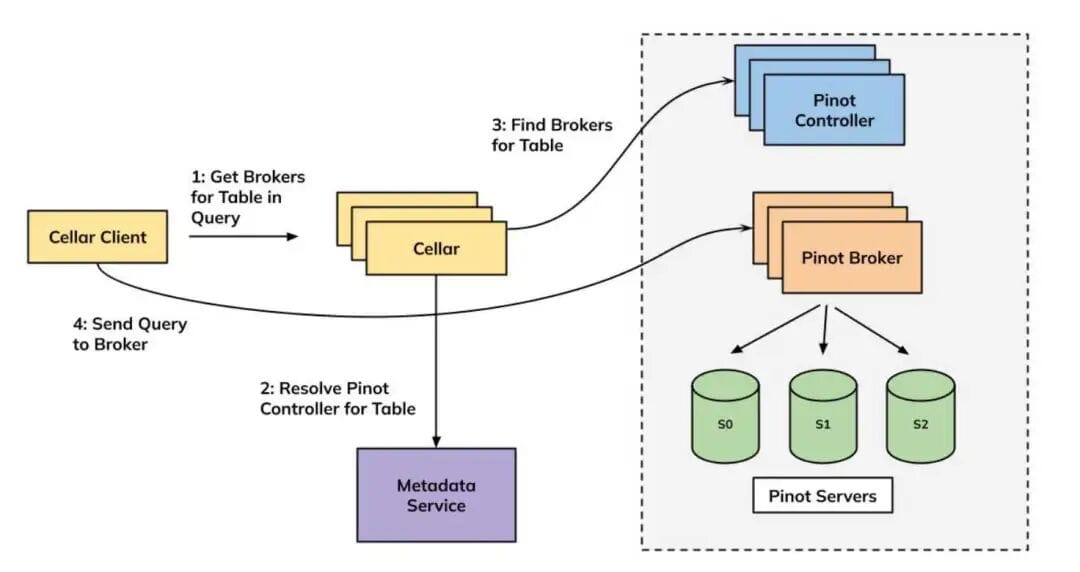
Cellar: New Query Architecture
Cellar proxy now directly forwards queries to Pinot brokers.
Workload Handling
- Simple workloads → Pinot’s single-stage query engine
- Advanced SQL → Multi-Stage Engine Lite Mode
Core Enhancements
- Configurable leaf-stage limits, exposed in the explain plan
- Retains scatter-gather pattern
- Controlled support for joins and window functions
- Enhanced monitoring and logging for query performance visibility

High-level Cellar query architecture — source: Uber blog
---
Direct Connect Mode & Time-Series Integration
Direct Connect Mode
- Tenants can bypass the proxy and connect directly to Pinot brokers
- Provides full isolation
Time-Series Plugin
- Enables M3QL queries through Cellar
- Supports use cases:
- Tracing
- Log search
- Segmentation
Adoption Status:
- Serves ~20% of former Neutrino volume
- Plans to fully retire Neutrino over time
Cellar direct connect mode — source: Uber blog
---
Developer Experience with Client Libraries
Uber-Provided Clients (Java & Go)
Features:
- Handle Pinot’s response format
- Support partial results with warnings
- Enforce timeouts & retries
- Emit metrics: latency, success rates, warnings
Operational Visibility:
- Out-of-the-box Grafana dashboards for new users
---
Forward-Looking Roadmap
Uber sees this redesign as an evolution of OLAP systems aiming for:
- High QPS
- Sub-second latency
- Strong isolation
- Predictability
Future Plans:
- Broader rollout of MSE Lite Mode later this year
- Further performance & feature enhancements
---
Related Tools for Data Publishing & Monetization
For organizations or creators managing and tracking AI-powered data insights, platforms such as AiToEarn官网 can be relevant:
- Open-source global AI content monetization platform
- Enables generation, cross-platform publishing, and analytics
- Supports channels like Douyin, Kwai, WeChat, Bilibili, Facebook, YouTube, LinkedIn, X (Twitter), etc.
- Aligns with Uber-like goals for visibility and performance tracking in analytical tooling
---
Original Source:
Inside Uber’s Pinot Query Overhaul: Simplifying Layers and Improving Observability


