Ultra-Long Sequence Parallelism: Ulysses + Ring-Attention Principles and Implementation

00 — Preface
Long-Sequence Training Challenges
Training ultra-long sequences is a critical aspect of large model development. In real-world inference — especially within Agent pipelines — a model’s generalization ability to handle long contexts directly impacts its reliability.
However, long-sequence scenarios place heavy demands on training resources due to the O(N²) complexity of Attention. As sequence length grows, GPU memory usage skyrockets, making efficient training difficult on GPUs with limited memory.
---
Sequence Parallelism Overview
Sequence Parallelism (SP) allows training long sequences across multiple GPUs/nodes without large-memory requirements.
> Definition: Sequence parallelism splits an input sequence into smaller sub-sequences processed in parallel on different GPUs, reducing memory load.
Common Approaches
- Ulysses (DeepSpeed)
- Ring-Attention (Flash-Attn derivative)
- Megatron-SP/CP (Megatron-LM optimizations)
In this guide, we focus on Ulysses and Ring-Attention, which integrate well with the Transformers ecosystem.
---
Memory Reduction Example (Qwen2.5‑3B)
| SP Size | SP Strategy | GPU Memory | Training Time |
|---------|------------------------------|------------|---------------|
| 8 | ulysses=2 + ring=4 | 17.92 GiB | 1:07:20 |
| 4 | ulysses=2 + ring=2 | 27.78 GiB | 37:48 |
| 2 | ulysses=2 | 48.50 GiB | 24:16 |
| 1 | No SP | 75.35 GiB | 19:41 |
Note: More splits reduce memory but increase communication overhead and training time.
---
01 — Ulysses
Core Idea
Ulysses splits sequences, exchanges activations before Attention, ensures each GPU has the full sequence, distributes Attention Heads across GPUs, and exchanges results after computation.
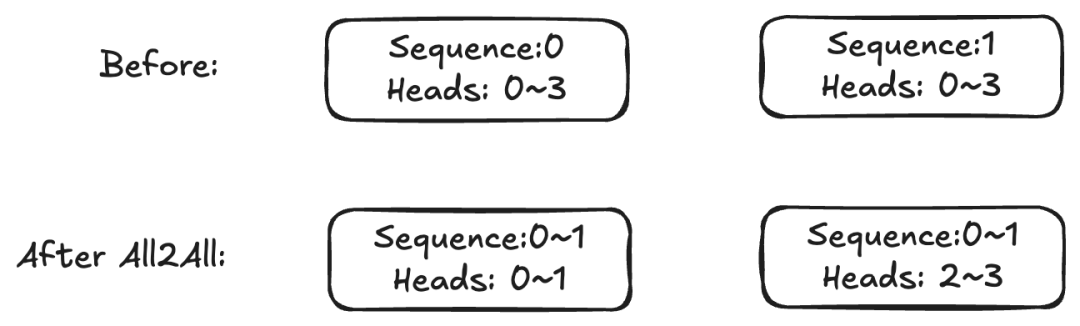
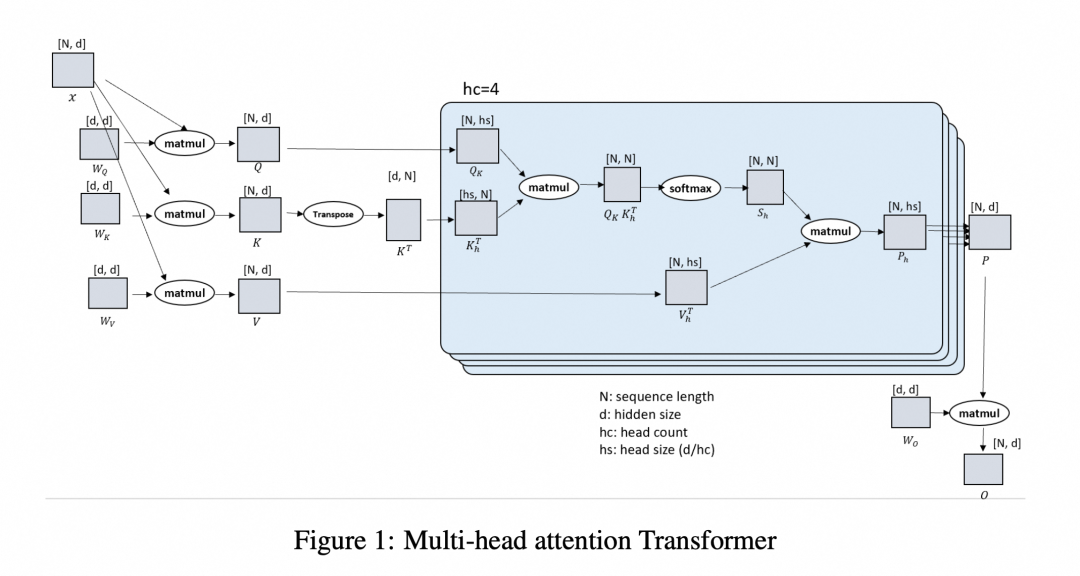
Key Points:
- N = sequence length
- d = hidden size = (#Heads × each head size)
- QKV remains intact, but different heads are on different GPUs.
Advantages:
- Works with GQA, MHA, `flash-attn`, SDPA, `padding_free`
- Compatible with forward optimization techniques
Limitations:
- Depends on number of Attention Heads; GQA with fewer KV heads may scale poorly.
---
02 — Ring-Attention
Concept Origins
Built on Flash-Attention, which blocks QKV/softmax to:
- Maximize SRAM use
- Reduce memory footprint
- Process incrementally
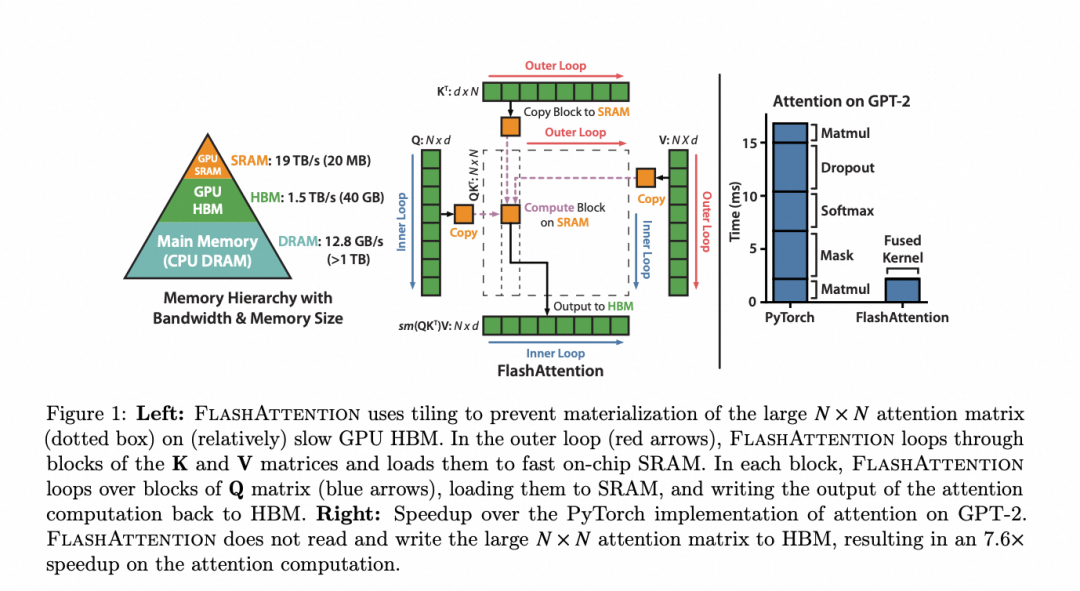

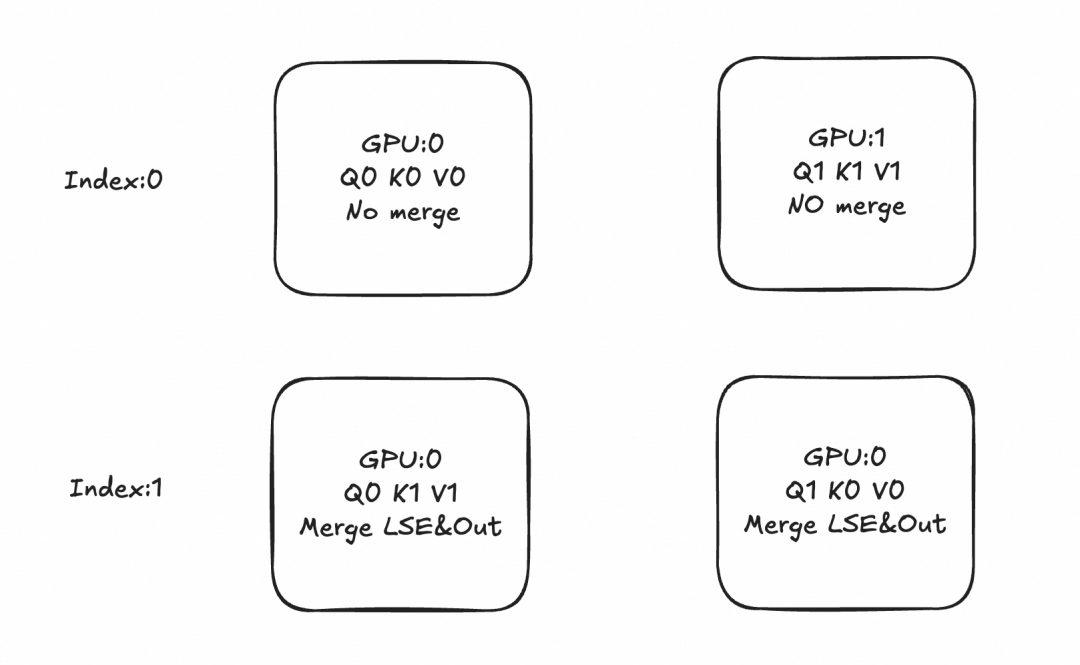
Ring-Attention Idea:
Split sequence into blocks across GPUs, compute block Attention locally, then circulate K/V among GPUs in a ring to complete the final Attention output.
---
Numerical Stability in Softmax
- Avoid direct exponentiation to prevent overflow/underflow
- Use LogSumExp (LSE) and PyTorch’s `softplus` for stable updates
---
Zigzag Ring-Attention Optimization
Standard Ring-Attn has uneven load due to causal masking.
Zigzag slicing pairs blocks strategically (e.g., 0/7, 1/6, 2/5, 3/4) to balance computation.
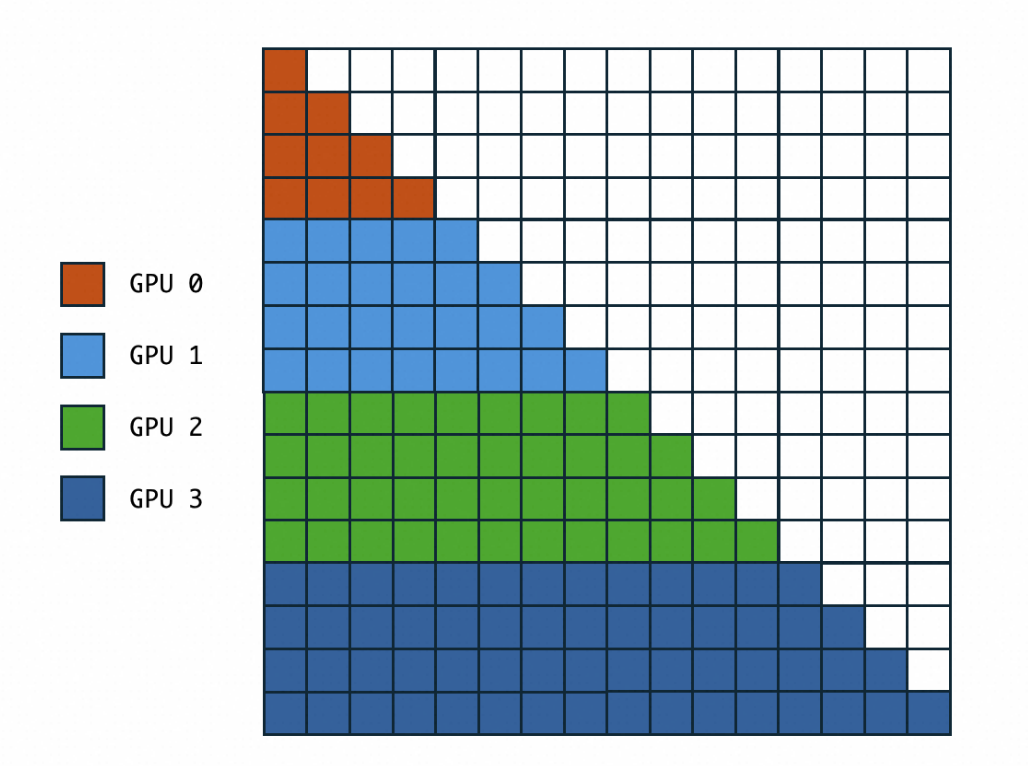
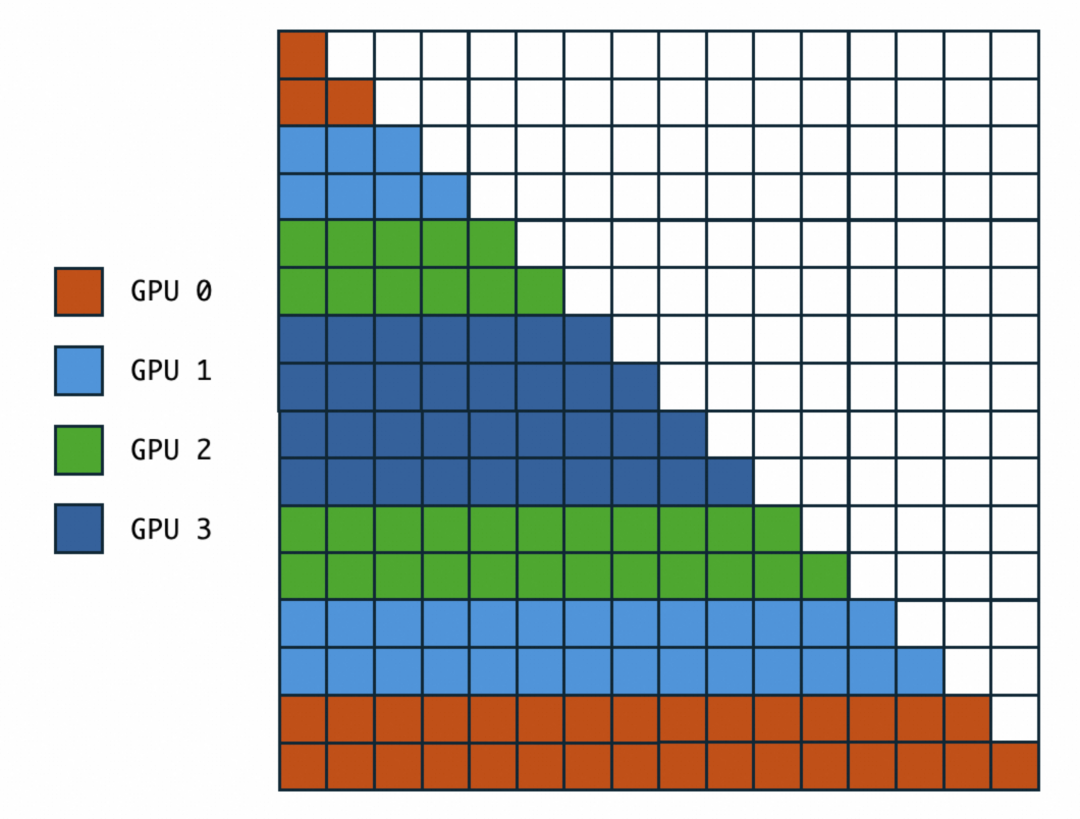
This:
- Balances workload
- Further reduces compute by limiting KV/Q processing in certain cases.
---
03 — Combining Ulysses + Ring-Attention
Comparison:
- Ulysses: Low comm volume, depends on heads, requires specific network topology
- Ring-Attn: P2P ring comm, no head constraint, higher comm volume
Strategy:
- Use Ulysses first (low comm cost)
- Add Ring-Attn if:
- Too many sequence splits
- Insufficient Attention Heads (e.g., GQA)
SWIFT Implementation
- Works for pure text, multimodal, SFT, DPO, GRPO
- Auto-detects split strategy
- Supports odd GPU counts
Command:
--sequence_parallel_size NSplit Flow Example
Splitting into 4 parts (Ulysses world_size=2, Ring world_size=2) with 4 heads:

---
Multimodal & `padding_free` Adaptations
- Split happens in backbone forward hook after ViT encoding merges
- Ensures compatibility with text/multimodal
- Padding each sequence to divisible length before split
- Special handling for padding in QKV during attention
- Loss calc rewritten for GRPO/DPO due to full-sequence requirements
---
04 — GPU Memory Optimization Results
Example: 3B model, 8×A100 GPUs
NPROC_PER_NODE=8 \
swift sft \
--model Qwen/Qwen2.5-3B-Instruct \
--dataset 'test.jsonl' \ # 9000 tokens/sequence
--train_type lora \
--torch_dtype bfloat16 \
--per_device_train_batch_size 4 \
--target_modules all-linear \
--gradient_accumulation_steps 8 \
--save_total_limit 2 \
--save_only_model true \
--save_steps 50 \
--max_length 65536 \
--warmup_ratio 0.05 \
--attn_impl flash_attn \
--sequence_parallel_size 8 \
--logging_steps 1 \
--use_logits_to_keep false \
--padding_free true⏬ Memory dropped from 80 GiB → <20 GiB with 8-way split.
---
05 — Outlook
Future optimizations:
- Faster backward pass without full recompute of `flash_attn_forward`
- Reduce P2P volume and add async execution
---
References
- NVIDIA Megatron-Core Context Parallel
- Sequence Parallel Paper
- Ring-Attention Paper
- DeepSpeed
- Ring-Flash-Attn
---
Related Note
For teams working with long-sequence models and multi-platform deployment, AiToEarn provides:
- AI content generation
- Simultaneous publishing to Douyin, Kwai, Bilibili, YouTube, X (Twitter), etc.
- Analytics + AI 模型排名
- Open-source integrations: GitHub
- Blog: AiToEarn博客
By combining GPU-efficient parallelism methods like Ulysses/Ring-Attn with multi-channel publishing, creators can link model outputs directly to audience engagement and monetization.


