
# Tongyi DeepResearch: A Detailed Breakdown
## 1. Introduction
Alibaba's **Tongyi Lab** has released an **Agent** project named **Tongyi DeepResearch** — without a press conference or grand announcements. Yet, on the day it appeared on GitHub, it **shot to the top of the daily trending list**.
While the release fueled widespread curiosity, the documentation contained intimidating terms — *post-training*, *tool calling*, *reinforcement learning* — that left some readers puzzled.
Since I’ve been exploring similar research directions, I’ll act as a guide to unpack **three core questions**:
1. **What does DeepResearch include, and how can you use it?**
2. **How was the DeepResearch model trained?**
3. **Which design aspects are worth referencing in your own work?**
---
### Intended Audience & Reading Guide
- **AI Application Developers** → Focus on Chapter 2 (modules & architecture).
- **AI Researchers** → Chapter 3 (data construction, training strategies, fine details).
- **Tech Managers / Architects** → Chapter 4 (consensus and debates on design).
---
**Key Links**
- **Project GitHub:** [https://github.com/Alibaba-NLP/DeepResearch](https://github.com/Alibaba-NLP/DeepResearch)
- **Open-source model:** [Tongyi-DeepResearch-30B-A3B](https://ModelScope.cn/models/iic/Tongyi-DeepResearch-30B-A3B/)
> *Disclaimer:* Content may contain inaccuracies due to limited knowledge. Corrections welcome. Differences between the [technical report (2)] and [ArXiv paper (12)] will be noted without resolving.
---
## 2. What’s in DeepResearch and How to Use It?
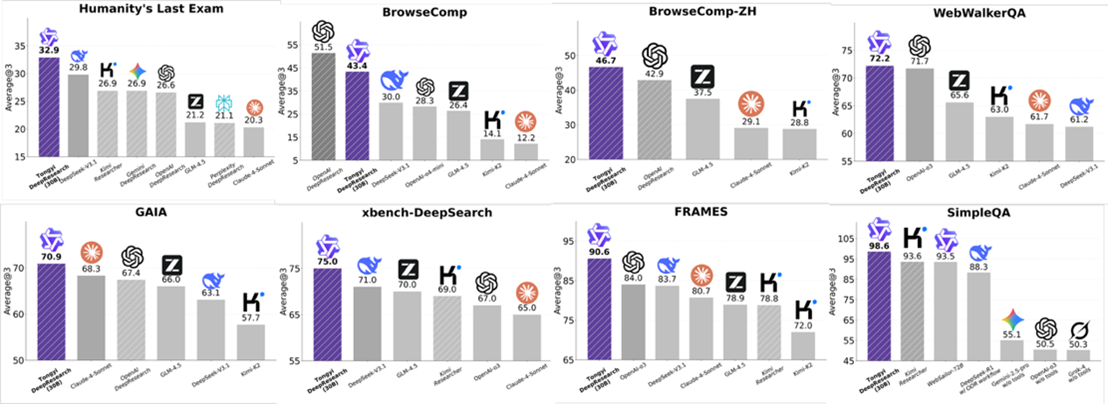
Released on **2025‑09‑16**, Tongyi DeepResearch is an **open-source Web Agent model** achieving **SOTA performance**:
- **Humanity’s Last Exam (HLE):** 32.9
- **BrowseComp:** 45.3
- **xbench‑DeepSearch:** 75.0
These scores **surpass proprietary models** like *OpenAI’s Deep Research*.
---
### Three Key Attributes
**1. Open-source**
Against a backdrop of strong closed-source offerings (GPT‑5, Claude, Grok), quality open-source projects remain crucial for transparent AI development, especially in Agent research.
**2. High-performance**
Every released model self-claims “high performance”, but survivorship bias lurks behind the scenes. DeepResearch’s benchmark results are genuinely noteworthy.
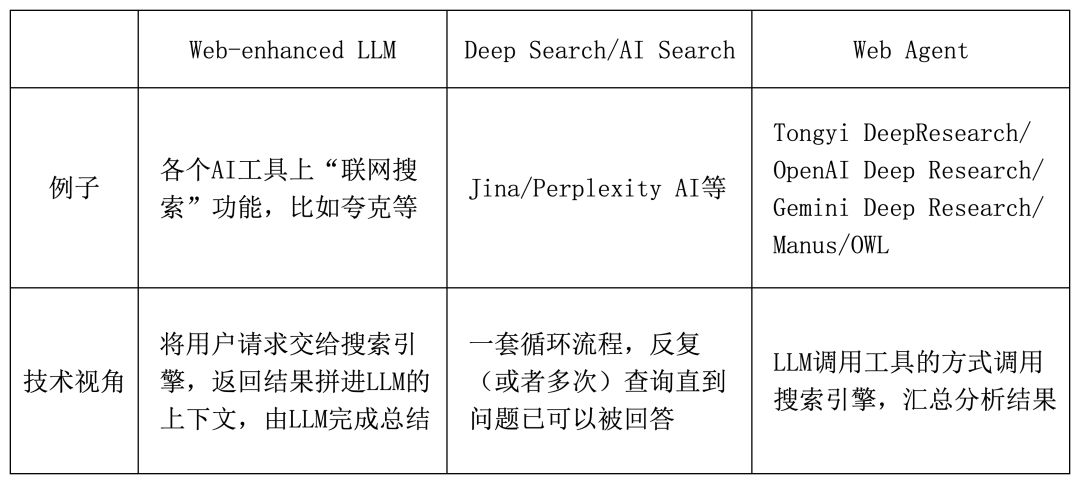
**3. Web Agent**
A Web Agent can proactively request and process information from the internet. Related concepts include *search-augmented LLMs*, *Deep Search* tools (Perplexity AI), and *AI search features*.
Categorization depends on both:
- Product scope (feature sets)
- Core technical ability (web interaction)
---
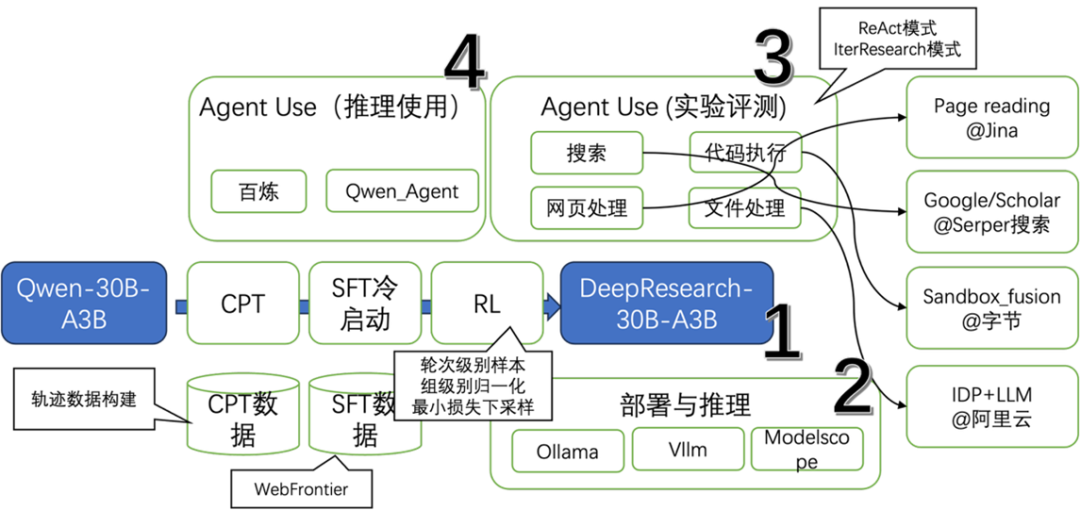
### Project Components
- **[Model]** DeepResearch‑30B‑A3B
- **30B MoE architecture**, 3B active parameters per run → deployable even on a MacBook Pro M2.
- **[Inference Code]**
- Built with `Qwen3MoeForCausalLM` → same deployment as Qwen3 models via `Vllm` or `ollama`.
- **[Evaluation Code]**
- ByteDance’s `Sandbox_fusion` for reproducing experimental results. Includes an **AgentUse** mode: *ReAct*.
- **[Agent Inference]**
- No direct Agent code; compatible with Qwen‑Agent. IterResearch mode not included in public repo.
---
#### Recommended Usage Combos
| Interest Area | Components to Use |
|--------------------------|-------------------|
| **Model research** | 1 + 2 + 3 |
| **Agent research** | 3 |
| **App experience/dev** | 4 |
| **Cosmic curiosity** | Email us with a 🐶 |
---
## 3. How Was the DeepResearch Model Produced?
Like many reasoning models, development follows **three stages**:
1. **Incremental training** + data synthesis (Two CPT phases)
2. **Supervised Fine-Tuning (SFT)** + data synthesis (*cold start*)
3. **Reinforcement Learning (RL)**

---
### Why These Three Stages?
**Consensus trends:**
- High-quality data creation remains **worth every effort**.
- Incremental training is broadly accepted — though implementations vary.
- Cold start + RL is increasingly seen as optimal for Agents.
---
### Stage 1: Incremental Training & Data Synthesis
**Core Question:** *What exactly needs enhancement in Agent CPT?*
Possibilities include:
- **Knowledge enhancement**
- **Reasoning enhancement**
CPT data here falls into:
- **General high-quality datasets** (web crawls, knowledge graphs, private sets)
- **Synthetic trajectory data** → key for learning planning, reasoning, decision-making.
**Challenges:**
- **Low acceptance rate** for usable samples
- **Slow expansion**, especially during tool calls, even with multithreading.
---
#### IterResearch Paradigm
Two core elements:
1. **Core report** for reasoning
2. **Workspace** for tool results
**Advantages over ReAct:**
- Avoids rapid context consumption.
- Reduces *context pollution* in long-horizon usage.
> Public repo only includes *ReAct* implementations.
---
### Stage 2: Supervised Fine-Tuning (Cold Start)
Cold start serves to bootstrap RL effectiveness.
**WebFrontier** synthesis approach:
1. **Seed data** from cleaned web pages/docs
2. **Iterative complexity upgrade** using Agents + toolset
3. **Quality control** — filter too-easy or unsolvable items
Binding training data tightly to toolsets ensures relevance but risks **scenario overfitting**.
---
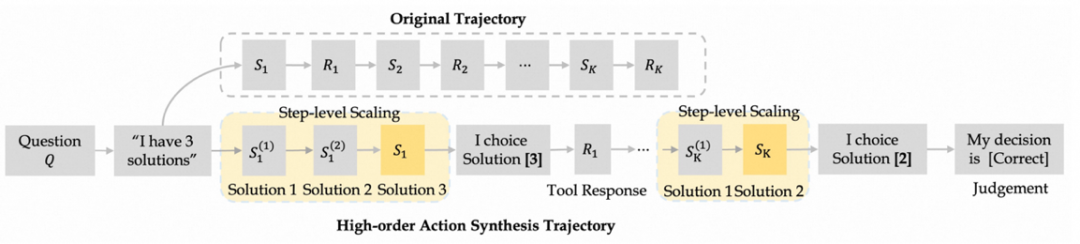
### Stage 3: Reinforcement Learning
Algorithm: **GSPO** (*Group Sequence Policy Optimization*)
Adjustments:
- Split trajectories into individual rounds → more training samples (**G × T**).
- **Group-level advantage normalization** for balanced reasoning across process stages.
- **Minimal-loss downsampling** for consistent batch sizes.
- **Dual-environment strategy** (simulation + real).
---
## 4. Which Designs Should You Reference?
### Consensus:
- High-quality data creation → critical.
- Closed toolsets aid stable pipeline development.
- Multi-stage training (CPT + SFT + RL) effective.
### Non-Consensus:
- Whether to use specialized models vs general LLMs for Agents.
- Necessity of CPT; viable skips focus on SFT + RL.
- Transferability of web-specific data methods across non-web Agents.
---
### Example Considerations:
- **Specialized models** excel at tool invocation long-range reasoning.
- **General models** offer flexibility; performance gap depends on domain.
- **Trajectory diversity** is expensive but necessary for robust Agents.
- Toolset **extensibility** should be factored into data synthesis plans.
---
## Final Thoughts
**Tongyi DeepResearch** is more than a model — it’s a well-documented case study in Agent training optimization. It provides practical insights for tackling debated aspects in the field.
Reading it feels like opening the fridge after a hot day to find a cold beer and marinated beef: **absolute satisfaction**.
---
## References
For full reference list, see:
- [GitHub Repo](https://github.com/Alibaba-NLP/DeepResearch)
- [ModelScope Page](https://ModelScope.cn/models/iic/Tongyi-DeepResearch-30B-A3B)
- [ArXiv Papers](https://arxiv.org/pdf/2509.13309)
Additional related works: *WebSailor*, *WebExplorer*, *GSPO* methodology, and toolset data (*WebShaper*).
---




