Understanding Specification-Driven Development: Kiro, spec-kit, and Tessl
# Exploring Specification-Driven Development (SDD) and Three Emerging Tools
I’ve been trying to wrap my head around the latest AI programming buzzword: **Specification-Driven Development (SDD)**.
Below is my analysis of what SDD currently means, how it’s defined by different vendors, and a deep dive into **three tools** claiming to implement it.
---
## What is Specification-Driven Development?
### Definition
Like many emerging terms in AI-assisted software development, the idea of SDD is still evolving.
The general principle is:
> **Write a structured specification first** (“documentation-first”),
> then use AI agents to generate code from it.
The specification becomes the **single source of truth** for both humans and AI.
**Vendor perspectives:**
- **GitHub**:
> “Maintaining software means evolving the specification... Code is the last-mile solution.”
- **Tessl**:
> “Specifications—not code—are the primary deliverables. Agents generate code to match them.”
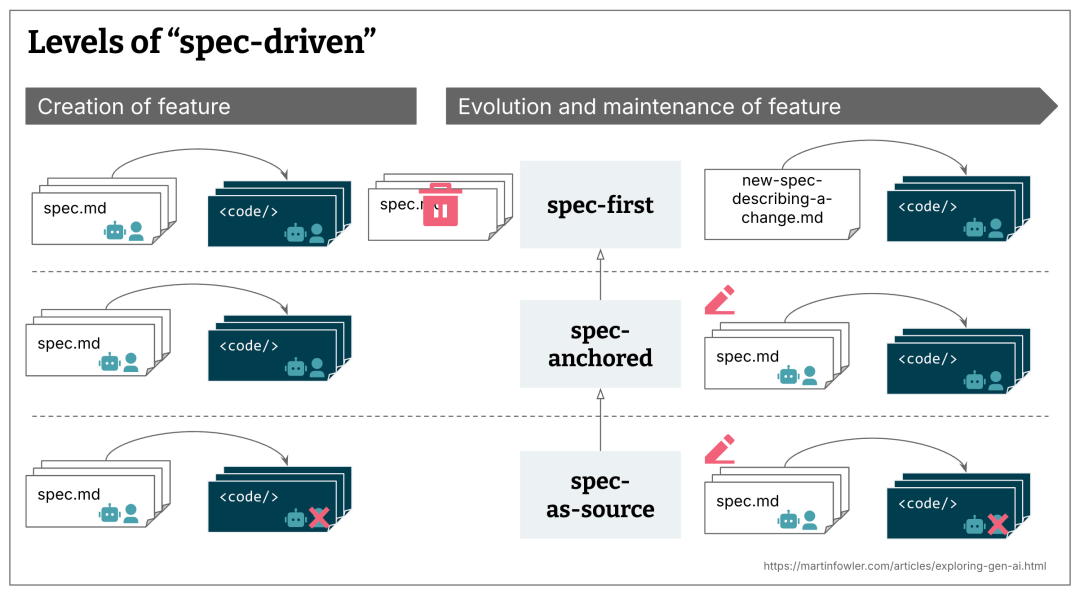
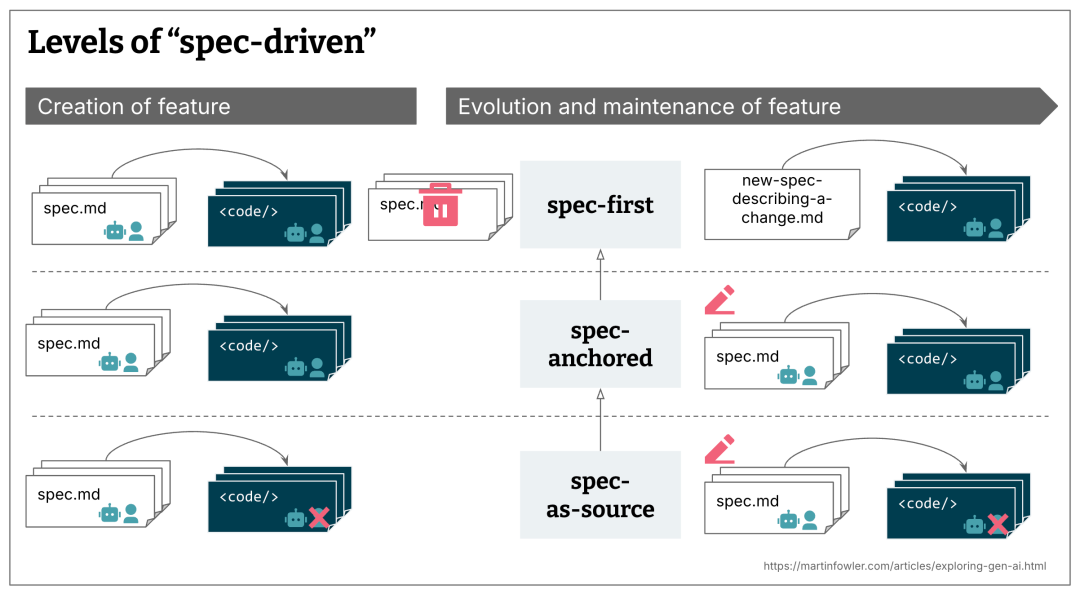
### Levels of Implementation
From my research, SDD can be practiced at several levels:
1. **Specification-First** – Write the specification before starting an AI-assisted development task.
2. **Specification-Anchored** – Keep the spec for future evolution and maintenance of the feature.
3. **Specification-as-Source** – Edit only the spec; the code is always regenerated from it.
Most current tools focus on **specification-first**, with *maintainability over time* remaining vague.
---
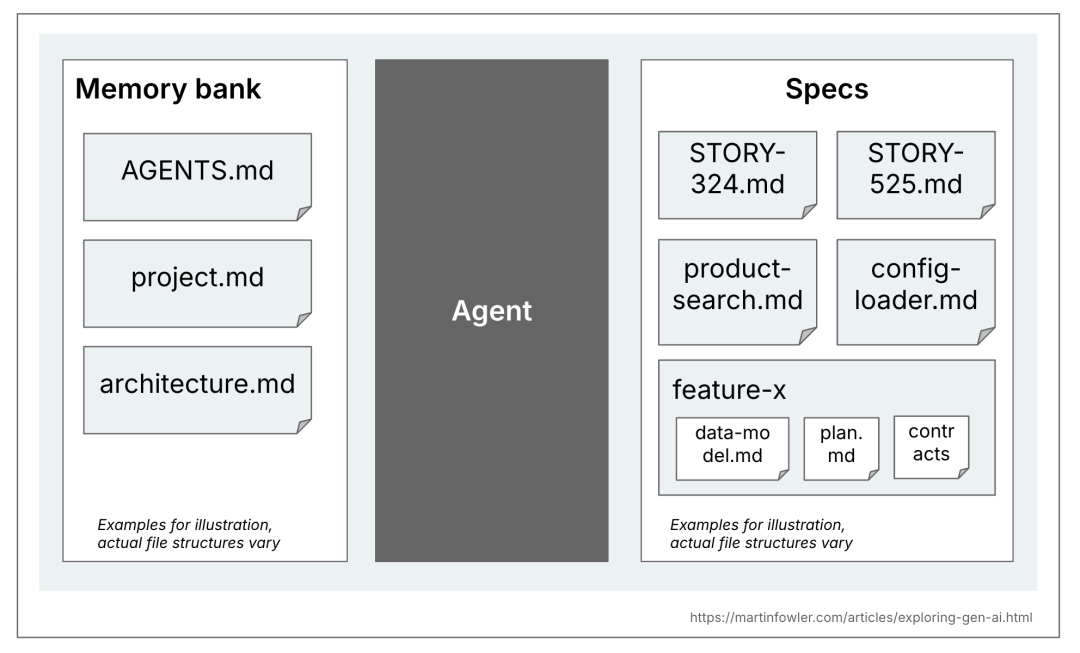
## What Counts as a “Specification”?
The term “specification” varies between tools. The most common comparison is with a **Product Requirements Document (PRD)** — but more behavior-focused.
**My working definition:**
> A specification is a **structured, behavior-oriented artifact** (or set of artifacts),
> written in natural language, describing desired software functionality, and guiding AI programming agents.
It differs from general codebase context docs (sometimes called a “memory base”), which include rules, architecture overviews, or shared product goals.
---
## Evaluating SDD Tools in Practice
Realistic evaluation of SDD tools is **time-intensive**:
You must try them on varying problem sizes, review intermediate artifacts, and see their behavior in greenfield *and* brownfield contexts.
GitHub’s Spec-Kit blog emphasizes:
> “Your role is not just to guide, but to verify… reflect and refine at each stage.”
For two of the three tools I tried, integrating into an existing codebase was **non-trivial**, raising questions on their brownfield suitability.
---
# Tool-by-Tool Breakdown
## 1. Kiro
**Type:** Light-weight, **Specification-First** tool.
**Workflow Stages:**
1. **Requirements** – List user stories (“As a…”) and acceptance criteria (“Given… When… Then…”).
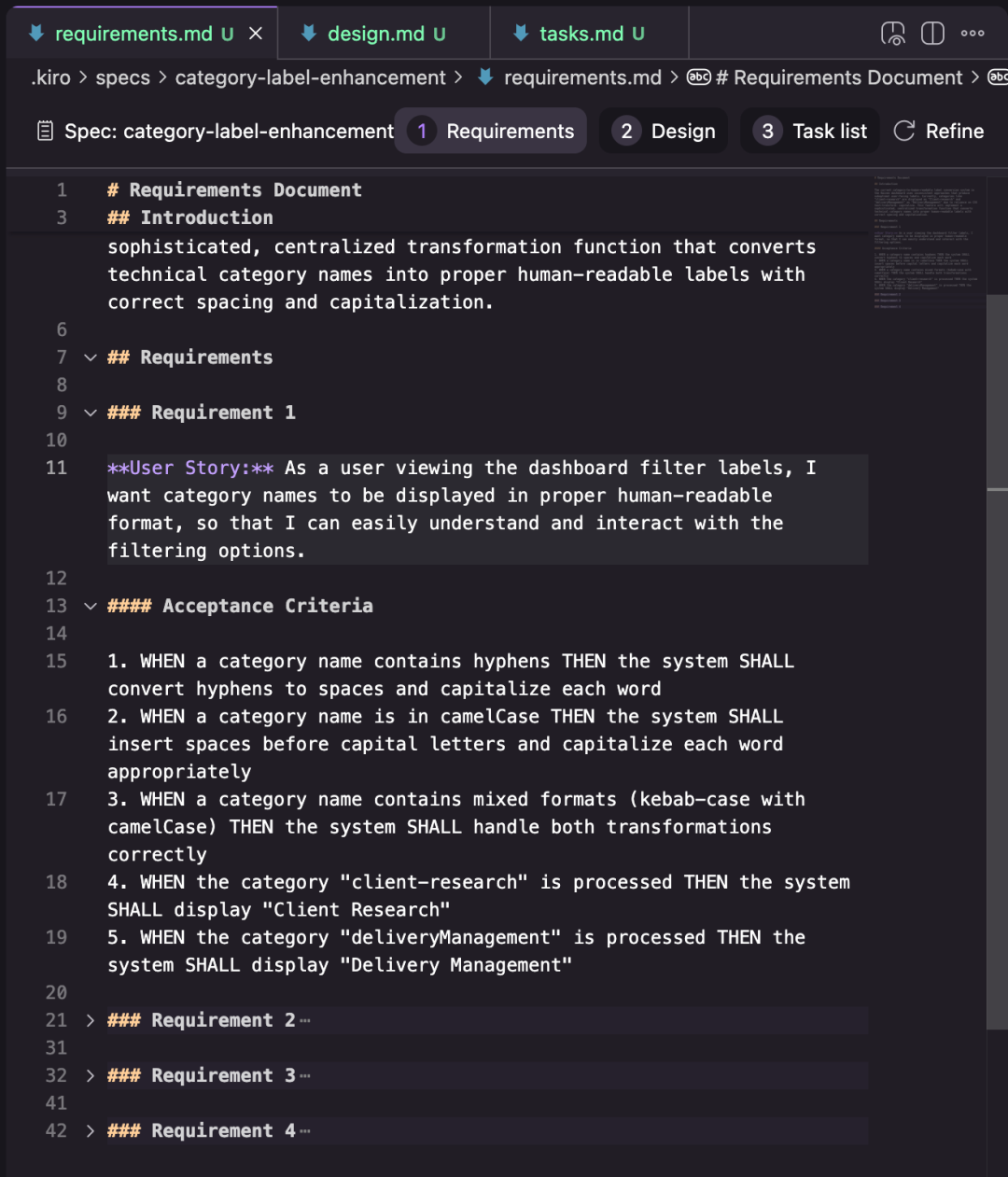
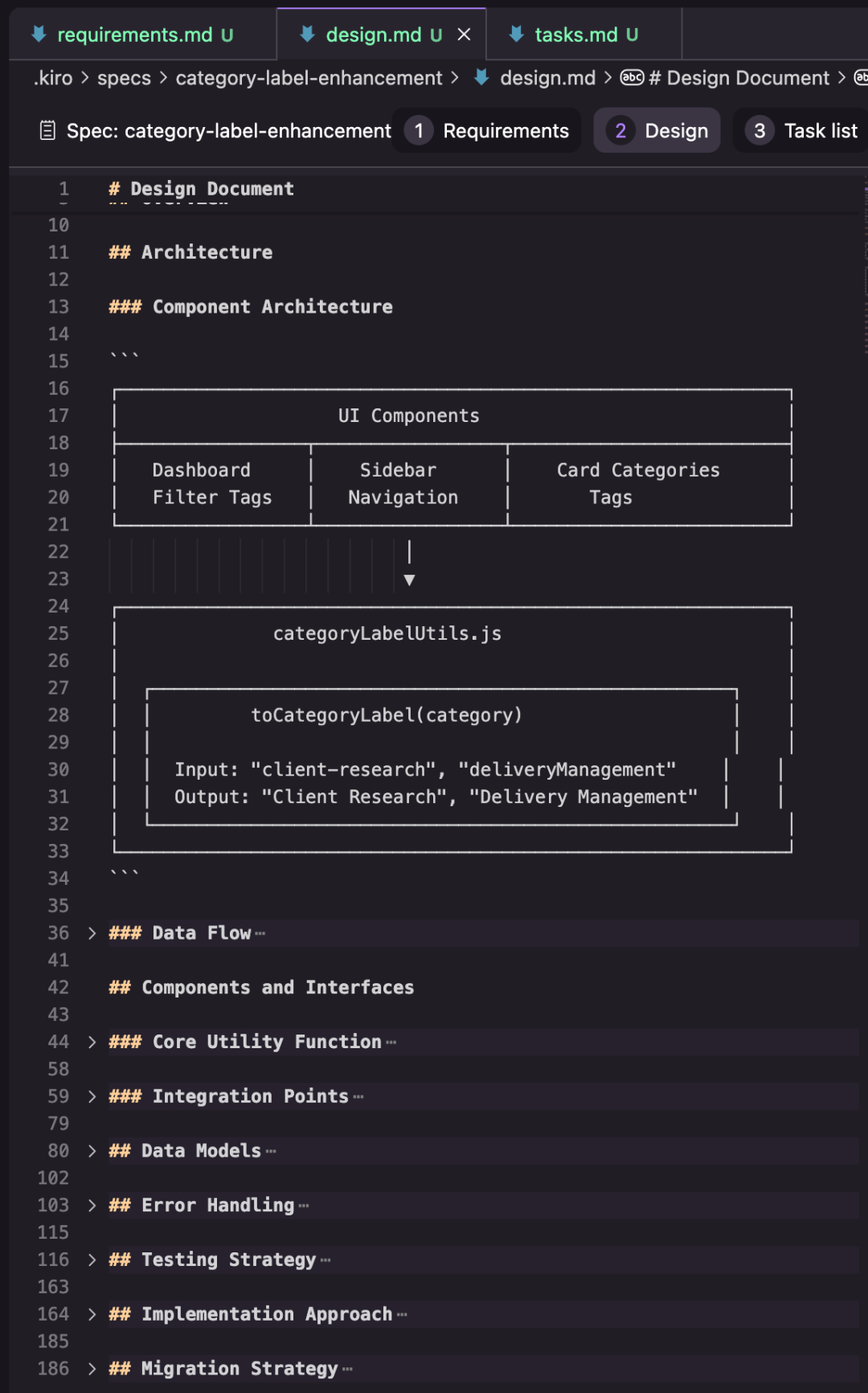
2. **Design** – Structured design document (varies per task).
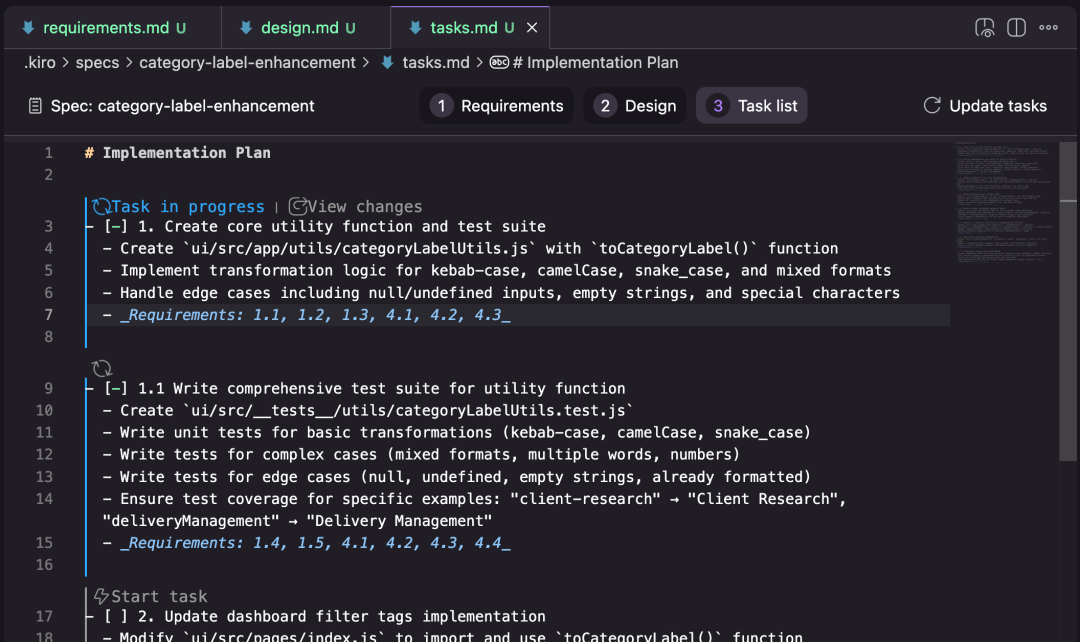
3. **Tasks** – List of tasks linked to requirement IDs; UI to run tasks sequentially and review changes.
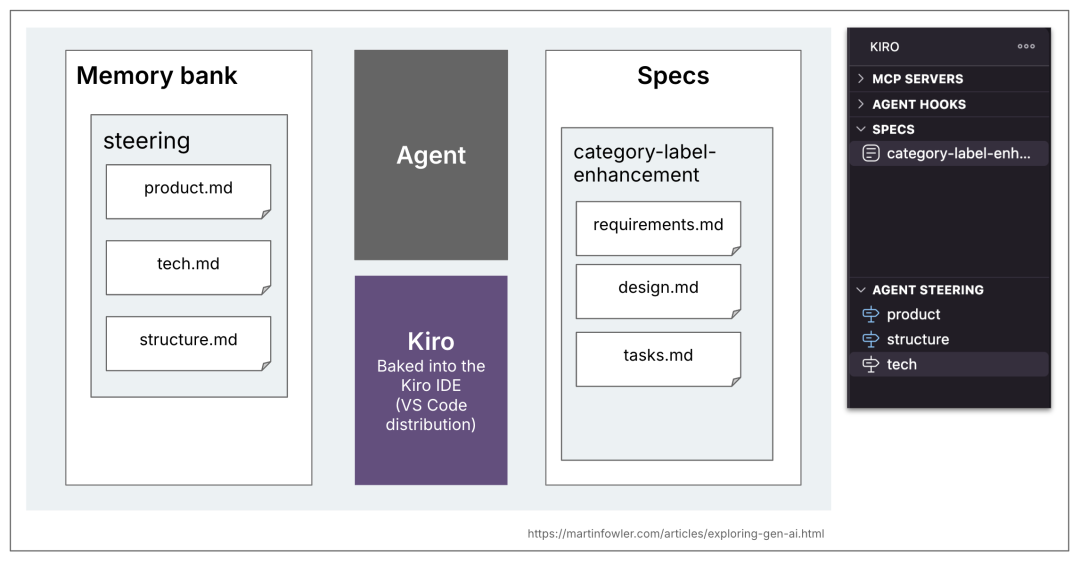
**Memory Repository (“Guidance”):**
- Flexible content, not required for workflow.
- Default: `product.md`, `structure.md`, `tech.md`.
---
## 2. Spec-Kit (GitHub)
**Type:** CLI tool, **Highly Customizable** but heavier workflow.
**Workflow Stages:**
*Constitution → Specification → Plan → Tasks*
- **Constitution** – Immutable high-level principles (“rule file”).
- Each step uses templates, bash scripts, and checklists (AI-interpreted).
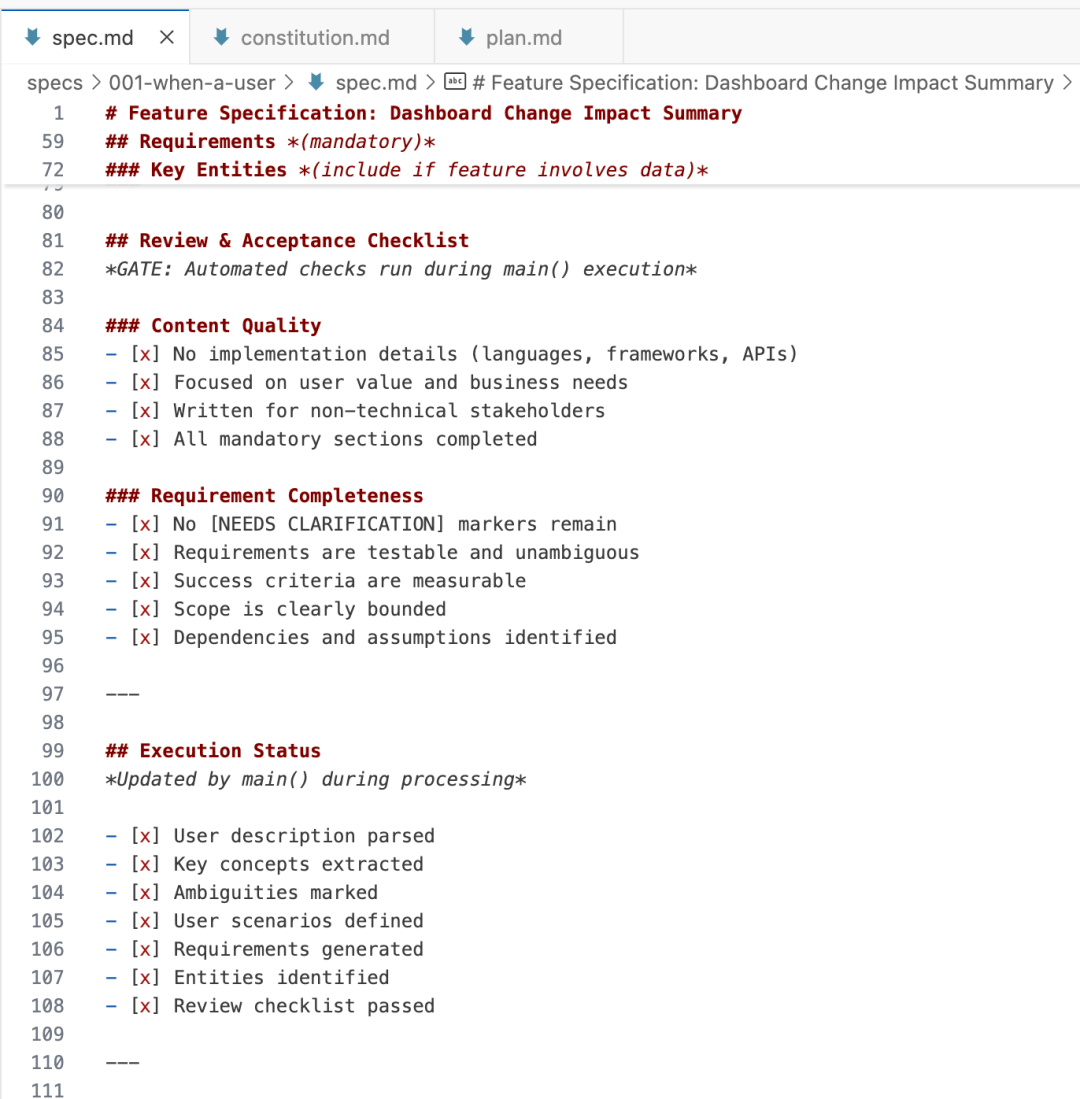
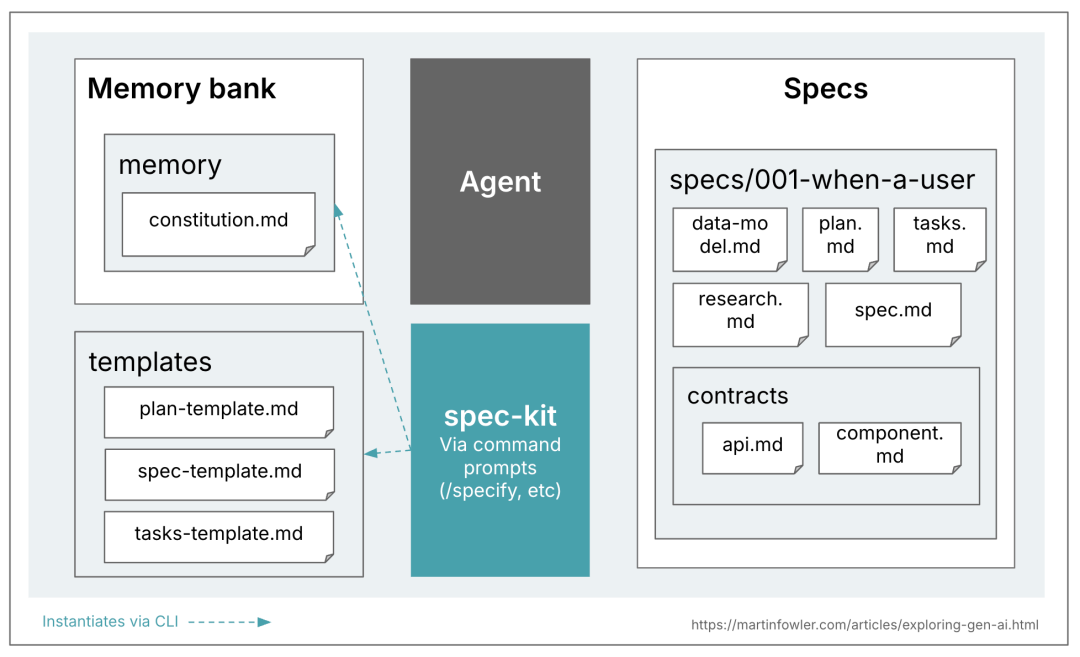
**Observation:**
- GitHub positions Spec-Kit as *specification-anchored*.
- In practice, specifications seem tied to a **change request lifecycle**, not the entire feature lifecycle — raising doubts about true long-term anchoring.
---
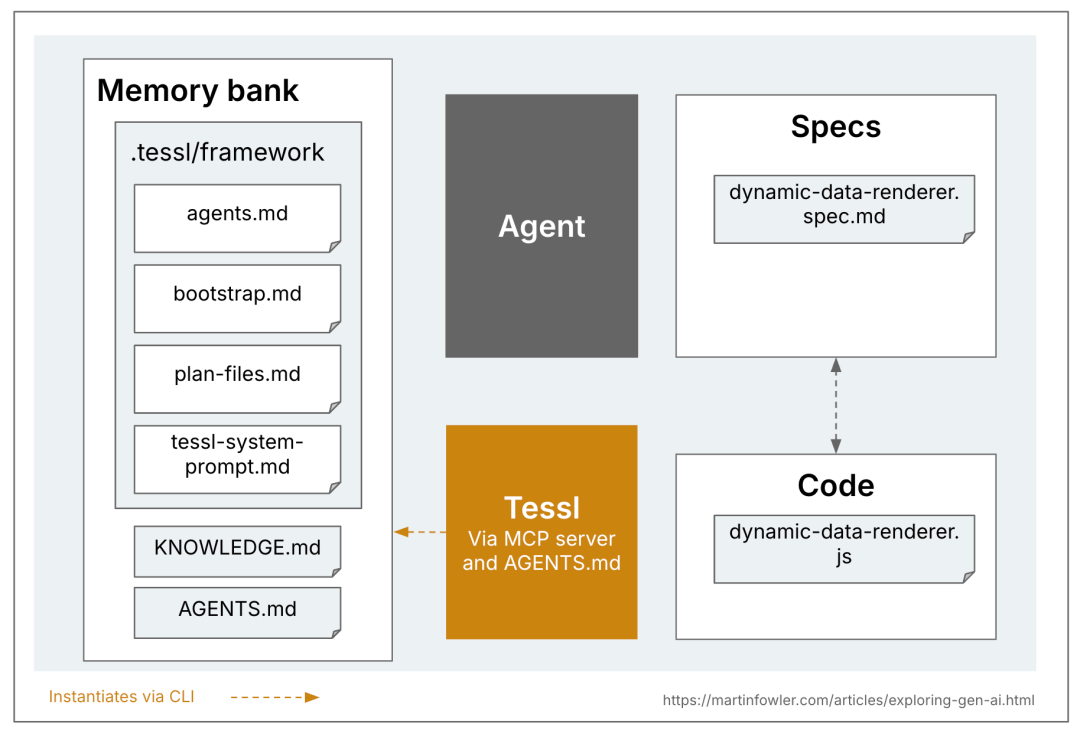
## 3. Tessl Framework
**Type:** CLI + MCP server, **Specification-Anchored**, experimenting with **Specification-as-Source**.
- Generated code contains `// generated from spec – do not edit`.
- Current mapping: **1 spec = 1 code file**, but could extend to multi-file components.
- Team’s vision is more futuristic than current closed-beta CLI.
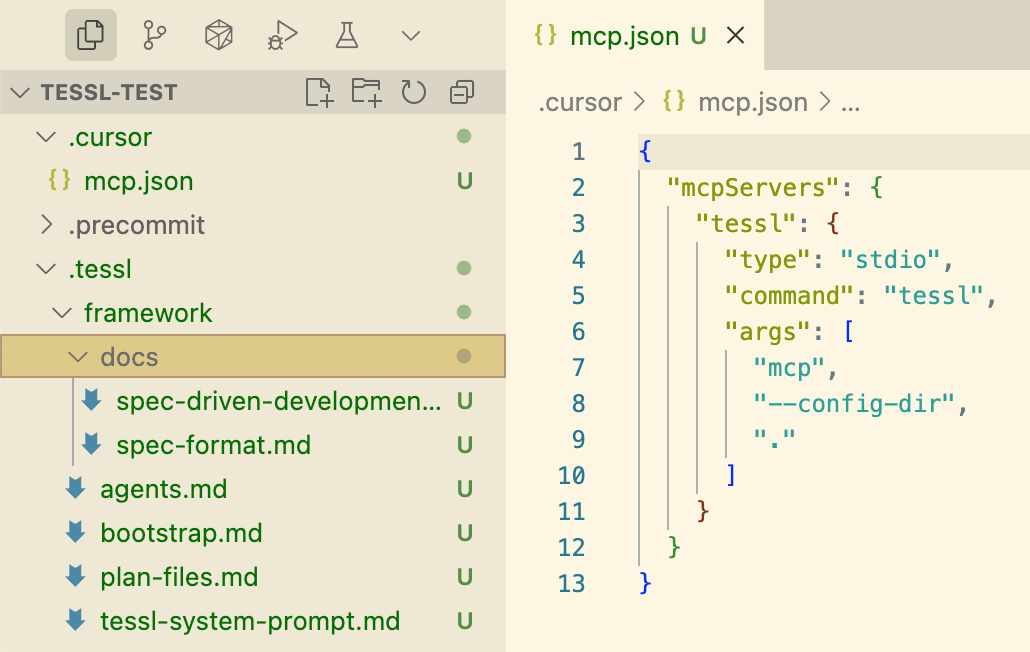
**Reverse-Engineering Example:**
- Run `tessl docs --code file.js` to generate spec from existing code.
- Specs use tags like `@generate` and `@test` to define generation logic.

**Build Process:**
- `tessl build` regenerates code from specs.
- Low-level abstraction may reduce LLM misinterpretation, but non-determinism still occurs. Iterating specs for repeatable output is essential.
---
# Key Observations and Open Questions
## 1. Suitability for Different Problem Sizes
Both **Kiro** and **Spec-Kit** feel **over-engineered** for small fixes, e.g.,:Tiny bug → 4 user stories → 16 acceptance criteria
An effective SDD tool must offer **flexible workflows**.
---
## 2. Markdown Review vs. Code Review
**Spec-Kit** often generates verbose, redundant Markdown for review.
**Kiro** is lighter but still rigid.
Preference: Review **code** wherever possible.
---
## 3. Illusion of Control
Large context windows don’t guarantee compliance with all instructions.
Agents may ignore or over-apply rules — creating duplicates or unnecessary complexity.
---
## 4. Functional vs. Technical Specs
Clear separation is difficult in practice.
Tutorials are inconsistent about staying “purely functional”, and industry track record here is weak.
---
## 5. Target Audience Ambiguity
Are these tools for developers, product managers, or both?
Workflows assume **developers** handle deep requirements analysis — potentially mismatched for vague, large features requiring more product-side engagement.
---
## 6. Specification Anchoring & MDD Lessons
**Model-Driven Development (MDD)** parallels:
- Structured models [= specifications] generating code.
- MDD failed commercially due to **abstraction overhead** and **inflexibility**.
- LLMs remove strict parsing but introduce **non-determinism**.
We should learn from MDD’s limitations when designing SDD workflows.
---
# Conclusion
**Spec-First** thinking is valuable — I already do it when crafting AI-friendly inputs.
But **SDD** is still loosely defined and risks becoming simply “detailed prompting”.
**Future direction:**
Platforms like [AiToEarn官网](https://aitoearn.ai/) — though focused on creative publishing — illustrate a viable **spec → AI → multi-platform execution** pipeline.
Adapting this principle to engineering could connect specification authoring directly with sustainable, iterative delivery.
---
## Final Thought
Some of these tools may be **“Verschlimmbesserung”** — making things worse while trying to improve.
Effective AI integration must **reduce**, not amplify, workflow friction.
**Original article:**
[https://martinfowler.com/articles/exploring-gen-ai/sdd-3-tools.html](https://martinfowler.com/articles/exploring-gen-ai/sdd-3-tools.html)