Universal dLLM Development Framework: Enabling BERT to Master Diffusion-Based Dialogue

Discrete Diffusion + Lightweight Instruction Fine-tuning: Unlocking BERT's Generative Power

Key Insight: "Discrete Diffusion + Lightweight Instruction Fine-tuning" can enable classic BERT to perform strong generative tasks.

Research Team:
- Zhou Zhanhui — Ph.D. candidate, Computer Science, University of California, Berkeley
- Chen Lingjie — Ph.D. candidate, Computer Science, University of Illinois Urbana-Champaign
---
Background
Diffusion Language Models (DLMs) have attracted significant interest. However, development is hindered by:
- Limited accessible frameworks
- High training costs
Most DLMs are hard to reproduce inexpensively, and newcomers often lack understanding of their training and generation processes.
Experiment Overview
Using their custom dLLM toolkit, the team taught BERT to chat via discrete diffusion.
- No generative pretraining required
- Around 50 GPU·hours of supervised fine-tuning on ModernBERT-large (0.4B parameters)
- Result: ModernBERT-large-chat-v0 reached performance near Qwen1.5-0.5B.
Conclusion: Discrete Diffusion + Lightweight Instruction Fine-tuning can effectively give classic BERT generative abilities — with low cost and high efficiency.
---
Full Open Source Workflow
The team has:
- Released the entire training, inference, and evaluation pipeline as a runnable Hello World example
- Open-sourced the dLLM framework — compatible with mainstream diffusion models, scalable, and research-friendly

Links:
---
dLLM Framework Highlights
dLLM: A unified development framework for Diffusion Language Models — powering all training, evaluation, and visualization in the BERT Chat project.
Design Principles
- Ease of use & reproducibility: Clear structure, complete scripts — reproducible on a single GPU or laptop, beginner-friendly
- Compatibility: Supports models like Dream, LLaDA, RND, multiple base architectures
Unique advantage: Implements algorithms missing from public repos (e.g., Edit Flows), allowing practical execution of methods previously only described in papers.
---
Why ModernBERT as Base Model?
ModernBERT offers:
- Extended context window (8,192 tokens)
- Stronger benchmark performance compared to original BERT
- Architecture well-suited for discrete diffusion fine-tuning
---
> Tip for Creators & Researchers: For efficient model training and broad publishing of AI content, platforms like AiToEarn官网 offer open-source tools for multi-platform distribution (Douyin, Kwai, WeChat, Bilibili, etc.), analytics, and model ranking.
---
Model Selection: ModernBERT Performance
Pretraining tests on Wikitext-103-v1 showed ModernBERT achieving the lowest training loss, reinforcing its suitability for generative tasks with diffusion methods.
---
Is Diffusion Pretraining Necessary?
Key Finding
Supervised Fine-tuning (SFT) alone can activate generative capability in ModernBERT:
- Extra MDLM pretraining yields minimal gains if MLM pretraining is already strong.
Instruction Tuning Trials: Three checkpoints—no GPT-style pretraining, MDLM on Wikitext, MDLM on OpenWebText—all converged to similar loss values.
---
Scaling SFT — Final Training
Data:
- allenai/tulu-3-sft-mixture
- HuggingFaceTB/smoltalk
Models:
- ModernBERT-base-chat-v0 (0.1B)
- ModernBERT-large-chat-v0 (0.4B)
Result: Stable multi-turn conversation capability — diffusion SFT alone is enough.
---
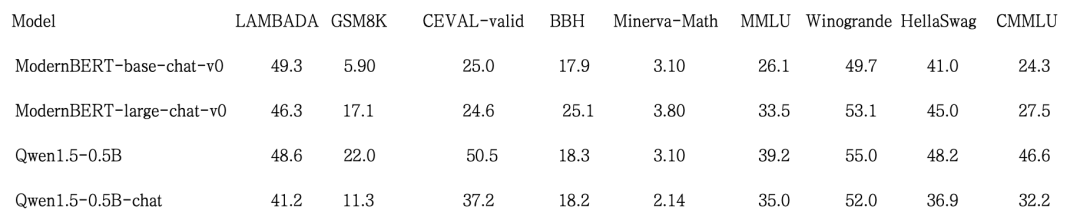
Benchmark Results: Small Models — Strong Performance
Tested on:
- LAMBADA (language comprehension)
- GSM8K (math reasoning)
- CEVAL-valid (Chinese knowledge)
Findings:
- Large model approaches Qwen1.5-0.5B
- Base model (0.1B) creates fluent language despite its small size
---
Educational Value & Practical Tips
Purpose: Educational and research — not commercial
Benefit: Understand full DLM pipeline without massive compute
Speed Tip: Halving diffusion steps (T) noticeably speeds up generation by parallelizing multiple tokens per step.
---
Practical Takeaway
With strong MLM pretraining:
- Diffusion-based instruction tuning unlocks generative capacity — no large-scale autoregressive pretraining needed
- Small teams can achieve practical conversational models on modest budgets
---
Full Transparency Practice
All:
- Training scripts
- Loss curves
- Ablation studies
- Parameter settings
- Execution commands
… are open via the W&B report — promoting reproducibility.
---
Summary: Re-activating BERT
This research shows:
- Diffusion SFT + small instruction data → functional conversational BERT
- No need for terabyte-scale pretraining
- dLLM offers beginners a full start-to-end tutorial on DLMs
For creators wanting widespread distribution and monetization of such AI projects, AiToEarn官网 supports multi-platform publishing, content analytics, and AI model rankings.
---


