VAE Hit Again! Tsinghua & Kuaishou Unveil SVG Diffusion Model with 6200% Training Boost and 3500% Generation Speedup
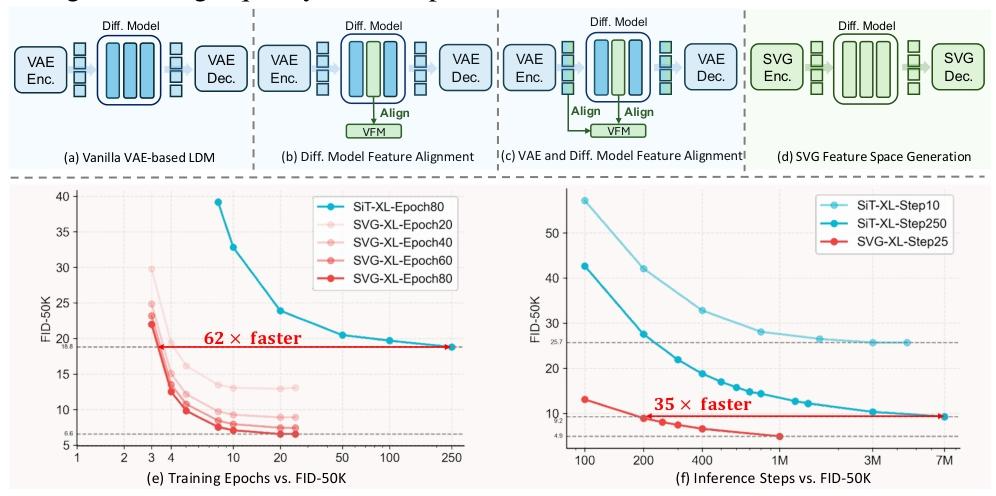
SVG: A Latent Diffusion Model Without VAE
Right after Xie Saining announced the retirement of VAE from the image generation field, Tsinghua University and Kuaishou’s Kolin team introduced SVG — a latent diffusion model that completely avoids using a VAE.
This approach achieves:
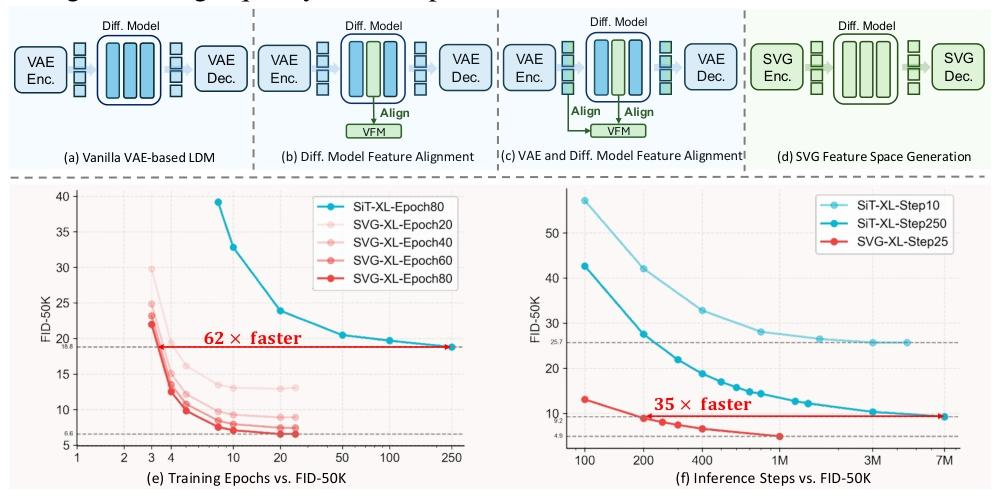
- 62× improvement in training efficiency
- 35× boost in generation speed
---
Why the Shift Away from VAE?
The Problem: Semantic Entanglement
In VAE-based models, all semantic features are stored in the same latent space.
Tweaking one value can unintentionally alter multiple traits.
Example: Changing a cat’s fur color might also change its size or expression.
RAE vs. SVG Approaches
- RAE (by Xie Saining)
- Minimally reuses pretrained encoders (e.g., DINOv2, MAE)
- Modifies only the DiT architecture
- Focuses purely on generation performance
- SVG (by Tsinghua & Kolin)
- Uses dual-branch semantic + detail structure
- Introduces distribution alignment to blend features cleanly
- Aims for multi-task adaptability beyond just image generation

---
Issues with Traditional "VAE + Diffusion" Paradigm
A VAE compresses high-resolution images into low-dimensional latent features, which the diffusion model then reconstructs.
But this compression leads to:
- Loss of category distinction (e.g., cat vs. dog features mix together)
- Low training efficiency — millions of steps required to disentangle semantics
- Complex generation process — dozens/hundreds of sampling steps for clarity
- Single-purpose latent space — unsuitable for other vision tasks (recognition, segmentation)
---
RAE’s Pure Generation Strategy
RAE tackles VAE’s limitations by:
- Reusing mature pretrained encoders without structural changes
- Optimizing only the decoder to restore details
- Making targeted adjustments to diffusion architecture
Result:
Fast, high-quality image generation focused solely on speed and clarity.
---
SVG’s Broad Multi-Task Strategy
SVG differs by actively building a fused semantic + detail feature space.
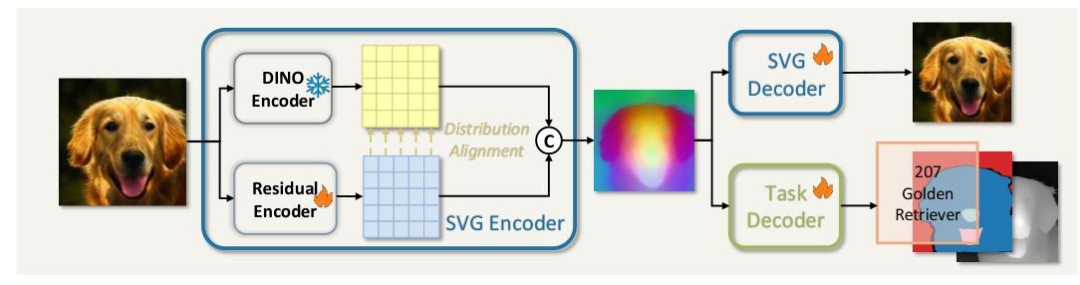
How SVG Works:
- Semantic Features: DINOv3 Extractor
- Pretrained with large-scale self-supervision
- Captures clear boundaries between categories (e.g., cats vs. dogs)
- Eliminates root cause of semantic entanglement
- Detail Features: Residual Encoder
- Recovers high-frequency details lost in DINOv3 (color, texture)
- Distribution Alignment
- Aligns detail feature distributions with semantic features
- Prevents detail noise from distorting semantic structure
Experimental Evidence:
Without distribution alignment, FID worsens dramatically (6.12 → 9.03).

---
SVG Results
Training Efficiency
- ImageNet (256×256):
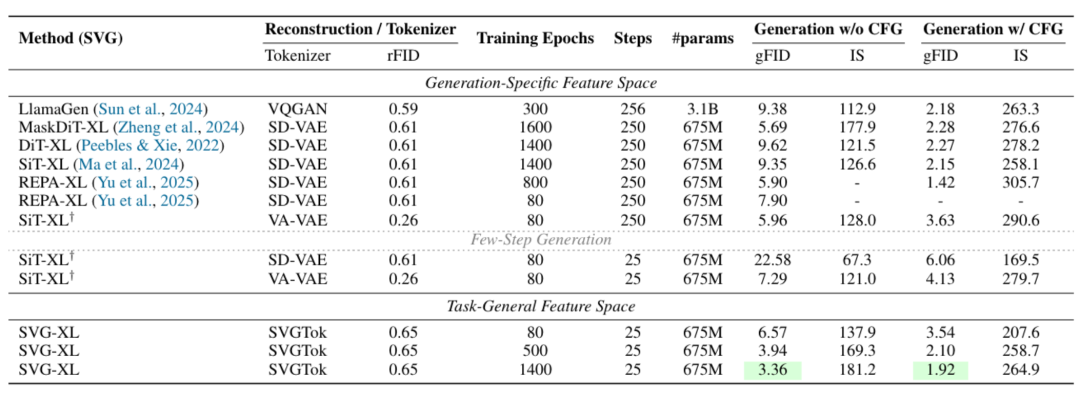
- SVG-XL: FID 6.57 after 80 epochs (no classifier guidance)
- vs. VAE-based SiT-XL: FID 22.58
- Extended training to 1400 epochs → FID 1.92
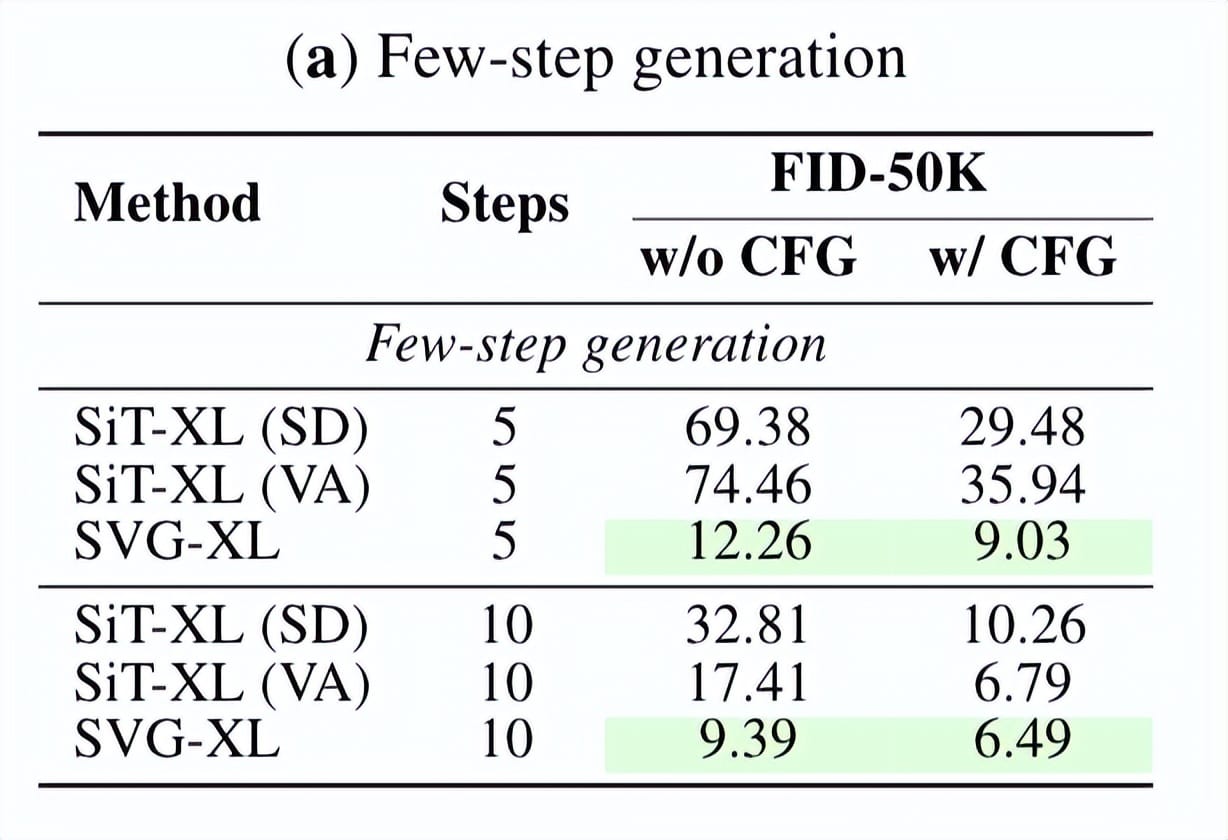
Inference Efficiency
- With 5 sampling steps:
- SVG-XL: gFID 12.26
- SiT-XL (SD-VAE): 69.38
- SiT-XL (VA-VAE): 74.46
---
Broader Industry Shift
Models like SVG and RAE signal a move away from VAE’s semantic entanglement toward:
- Efficient, high-quality generation
- Multi-task adaptability
This opens new possibilities for integrated ecosystems connecting model innovation with content production.
---
Example Ecosystem: AiToEarn
AiToEarn is an open-source, global AI content monetization platform enabling:
- AI content creation tools
- Cross-platform publishing
- Analytics
- Model ranking (AI模型排名)
Supports simultaneous distribution across:
- Douyin, Kwai, WeChat, Bilibili, Xiaohongshu
- Facebook, Instagram, LinkedIn, Threads
- YouTube, Pinterest, X (Twitter)
---
SVG’s Encoder Reusability Across Tasks
SVG inherits DINOv3’s capability for direct application in vision tasks without fine-tuning:
- Image Classification: Top-1 accuracy 81.8% on ImageNet-1K (close to DINOv3)
- Semantic Segmentation: 46.51% mIoU on ADE20K (near specialized models)

---
Research Team
- Wenzhao Zheng — Postdoctoral researcher, UC Berkeley; PhD in Automation, Tsinghua University
- Minglei Shi — Doctoral researcher, Tsinghua; founding an AI applications startup
- Haolin Wang — Doctoral researcher, Tsinghua; focuses on multimodal generative models
- Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan — Kuaishou’s Kolin team
- Pengfei Wan — Lead for video generation models
---
Key Takeaway
From RAE to SVG, different technical paths reach toward a common goal:
Pretrained visual model feature spaces may already be capable of replacing VAEs.
---
Final Note
Platforms like AiToEarn官网 can complement technical advancements by helping researchers and creators:
- Deploy AI models (like SVG) in production workflows
- Publish across multiple channels
- Track analytics & monetize outputs
Such infrastructure could streamline dissemination, collaboration, and monetization of high-performance AI-generated content.


