# 🚀 Keye-VL-671B-A37B Official Release
**Kwai's next-generation flagship multimodal LLM** — **Keye-VL-671B-A37B** — marks a significant leap in **visual perception**, **cross-modal alignment**, and **complex reasoning chains**, while retaining the robust general capabilities of its base model.
It **sees better**, **thinks deeper**, and **answers more accurately**, ensuring **precise, reliable responses** across everyday and challenging scenarios.
---
## 📸 Example 1 — More Reliable Image Semantic Understanding
**Question:** *How many movie tickets are shown below?*

A quick glance might suggest **three** tickets.
Upon closer inspection, there are **only two** movie tickets — the rightmost one is a popcorn coupon.
**Why Keye-VL gets it right:**
- Reads and understands **text, logos, and layout differences**.
- Identifies that **left** and **center** items are movie tickets (with seating & screening info).
- Recognizes **right** item as a **food coupon** lacking ticket details.
**Conclusion:** **Two movie tickets.**
Key takeaway: The model combines **fine visual detail analysis** with **logical reasoning**, sometimes exceeding human reliability.
---
## 🎥 Example 2 — More Accurate Video Detail Grasp
**Question:** *How does the camera angle change in the video?*

**Keye-VL output:**
1. Identifies scene elements: "Blue double-decker tram", brands like *Louis Vuitton* & *Tiffany & Co.*
2. Detects **camera movement**:
> “Starts from a high, fixed vantage point, slowly pans right at constant height, revealing more of Central’s night scene — capturing vehicles, architecture, and pedestrian activity.”
**Insight:**
Accurately captures **objects** *and* **temporal dynamics** — even in dense visual contexts.
---
## 📂 Open Source Access
Try **Keye-VL-671B-A37B** via:
- **GitHub:** [https://github.com/Kwai-Keye/Keye](https://github.com/Kwai-Keye/Keye)
- **HuggingFace:** [https://huggingface.co/Kwai-Keye/Keye-VL-671B-A37B](https://huggingface.co/Kwai-Keye/Keye-VL-671B-A37B)
---
## 🏗 Technical Architecture Overview
**Core components:**
- **DeepSeek-V3-Terminus** → Enhanced text reasoning.
- **KeyeViT** (Keye-VL 1.5) → Vision encoder.
- Bridged with **MLP layers**.
**Pretraining (3 stages):**
1. **Alignment:** Freeze ViT & LLM, train projector.
2. **Full training:** Unfreeze all parameters.
3. **Anneal:** Fine-tune with high-quality data for refined perception.
**Data:**
- ~300B filtered multimodal tokens.
- Covers OCR, charts, tables, complex VQA.
**Extra note:**
During annealing, **DeepSeek-V3-Terminus** synthesizes **Chain-of-Thought** reasoning to improve depth without losing LLM logic strength.
---
## 💡 Post-Training Process
**Three stages:**
1. **Supervised Fine-Tuning (SFT)**
- Uses multimodal + text **Long CoT** data to boost reasoning and multimodal abilities.
2. **Cold Start**
- Uses inference data to sharpen logical reasoning.
3. **Reinforcement Learning (RL)**
- Focuses on `think` & `no_think` reasoning modes.
- Adds video data to improve **video understanding**.
---
### ⚙️ Instruction + Long-CoT Hybrid Strategy
**Finding:** Hybrid of **Instruction** + **Long-CoT** data:
- **Outperforms** instruction-only datasets.
- **Stabilizes** subsequent training.
- **Loss curves** confirm reduced cold start loss with CoT data.
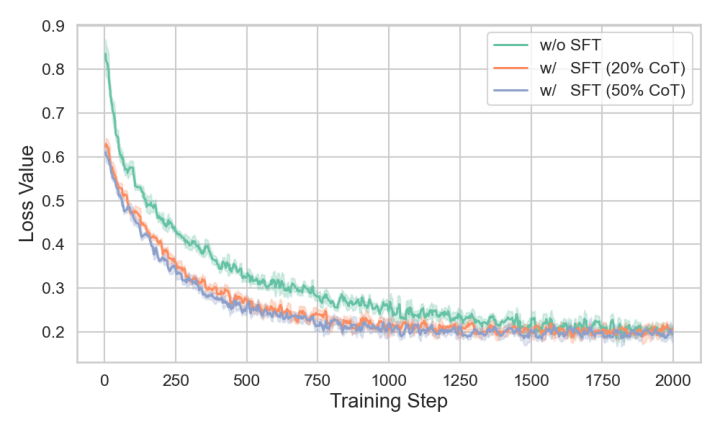
---
### 🧹 CoT Data Quality in Cold Start
**Challenge:** Pure-text models can be verbose & repetitive.
**Solution:**
- Strict filtering removes **redundant reflection behaviors**.


Result: Improved **reasoning** *and* **perception**.
---
## 🧮 Reinforcement Learning Advances
### GSPO > GRPO
- GRPO works at **token level**, unstable for MoE models.
- GSPO works at **sequence level** → **More stable RLVR** training.
---
### Verifier Reward Signals
**Verifier’s Law:** Training difficulty ∝ task verifiability.
**Verifier duties:**
1. Check reasoning process is logically sound.
2. Ensure answer correctness.
**Verifier Training:**
- **SFT:** Binary classification + complex think–answer analysis.
- **RL:** Preference learning + annealing with human-annotated examples.
**Accuracy Test:**
Compared with **Qwen-2.5-VL 72B**, Keye’s Verifier proved correct **128/150 disagreements**.
**Impact:**
+1.45% average accuracy across multimodal benchmarks.
+1.33% in multimodal math datasets.
---
### 🎯 Difficult Sample Filtering
- Uses **Keye-VL-1.5-8B** accuracy as filter.
- Keeps samples with 25–75% correctness.
- Adds more video data for RL stage → **better temporal reasoning**.
---
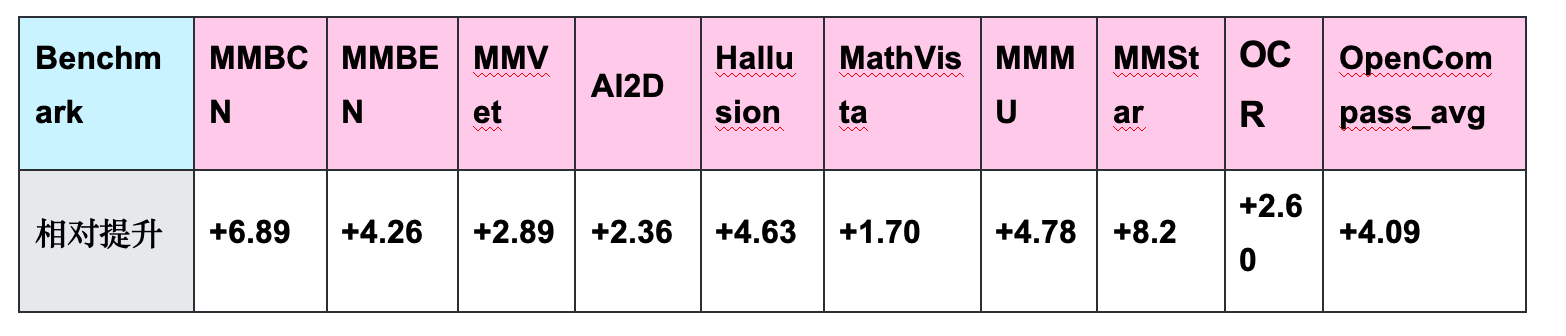
## 📊 Benchmark Summary
**1. General Visual Understanding & Reasoning:**
- Leads in **MMBench**, **MMMU**, **MMStar**, **RealWorldQA**.
- Excels in math & logic benchmarks (MathVista, VisuLogic, OlympiadBench).
**2. Video Understanding:**
- Tops **MMVU**, **LongVideoBench**, **VideoMME**.
- Strength in event tracking, storyline synthesis, cause-effect chains.
**3. Comprehensive Comparisons:**
- Beats competitors in STEM, reasoning, OCR, video understanding, pure text tasks.
---
## 🌐 Ecosystem Connection & AiToEarn Integration
Platforms like **[AiToEarn官网](https://aitoearn.ai/)** empower creators to turn **AI-generated content** into revenue:
- **Cross-platform publishing**: Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, YouTube, Pinterest, X (Twitter) and more.
- **Analytics & rankings** for model outputs.
- **Open-source tools** for monetization workflows.
Explore resources:
- Blog: [AiToEarn博客](https://blog.aitoearn.ai)
- Source Code: [AiToEarn开源地址](https://github.com/yikart/AiToEarn)
---
### ✅ Summary
Keye-VL-671B-A37B is a **state-of-the-art multimodal LLM** that:
- **Sees clearly**, **thinks deeply**, **calculates accurately**.
- Excels in **image**, **video**, **math**, and **complex reasoning tasks**.
- Is **open-source** and ready for integration into creative and practical AI workflows.
---



