vivo HDFS EC Large-Scale Implementation Practices
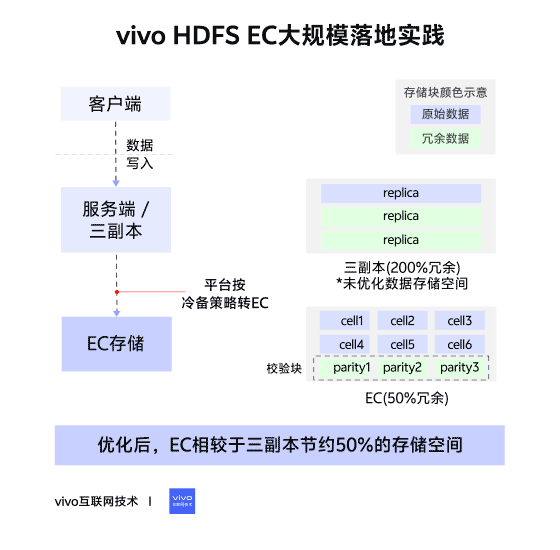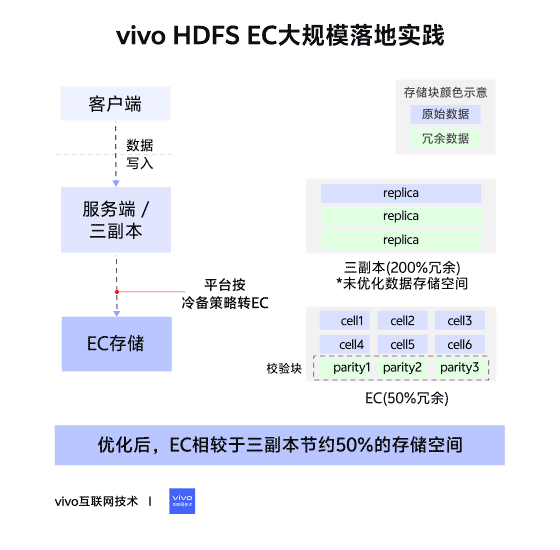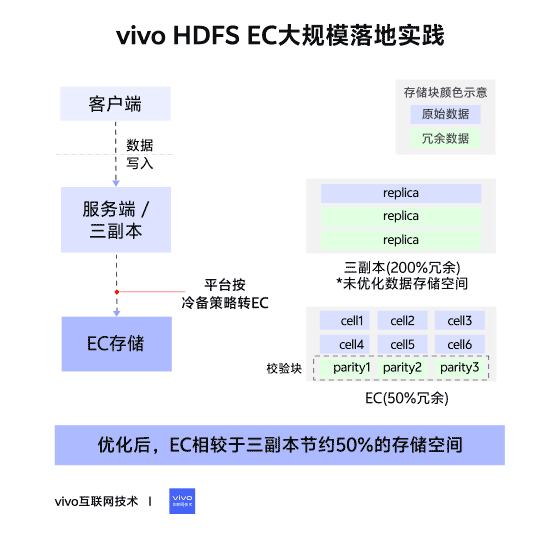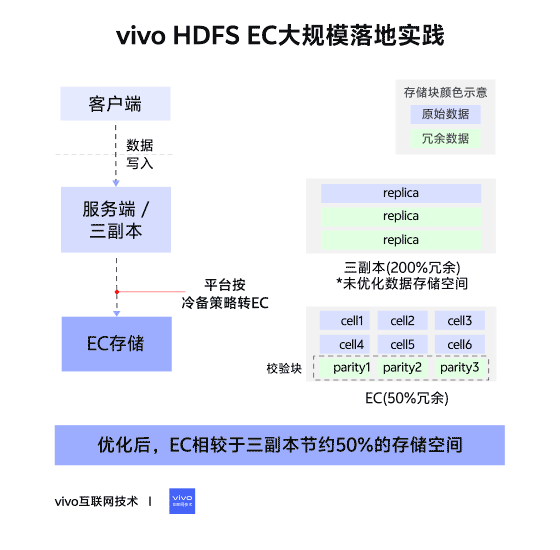
Table of Contents
- 01. Principle of EC Codes
- 02. Changes in Storage Layout
- 03. Practical Application of HDFS EC Codes
- 04. Summary & Outlook
---
Quick Overview – Grasp the Essentials in 1 Minute
Erasure Coding (EC) is a data protection technique that allows recovery from partial data loss. Introduced in Hadoop 3.0 as an alternative to the traditional triple-replication method, EC achieves high reliability with lower storage overhead.
In trade-off, read performance decreases — making EC best suited for infrequently accessed (cold) data.
> vivo's HDFS cluster now comprises tens of thousands of nodes and approaches exabyte scale. EC is deployed alongside compression algorithms, forming a strategic cost-reduction approach.
Visual Summary:

---
01 – Background: Reed–Solomon in EC
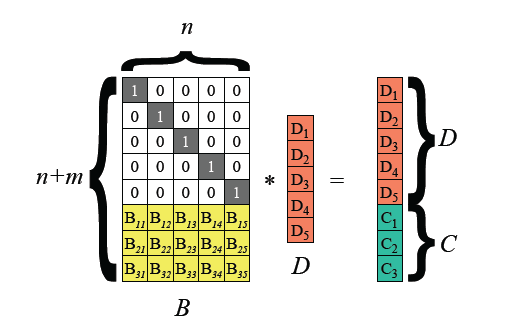
Reed–Solomon (RS) code is a cornerstone algorithm in EC.
- Encoding Process:
- Input vector `D1 ... D5` → Matrix multiplication with `B` → Outputs Data Blocks (D) and Parity Blocks (C).
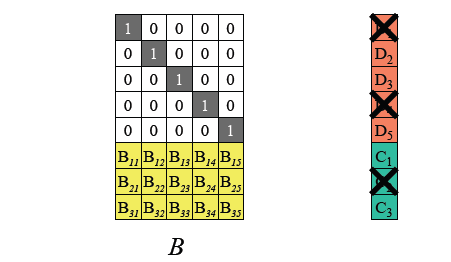
- Recovery Process:
- Lost blocks (e.g., `D1`, `D4`, `C2`) → Compute recovery matrix → Multiply with remaining blocks → Restore missing data and parity.
Illustrations:
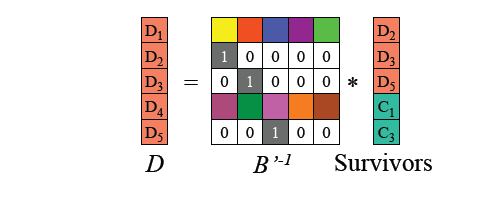
---
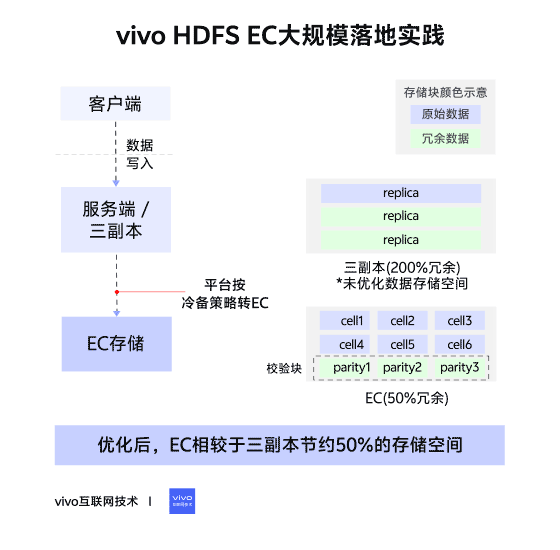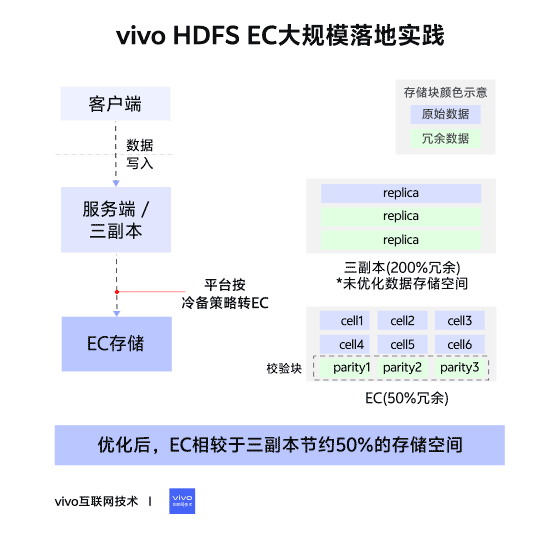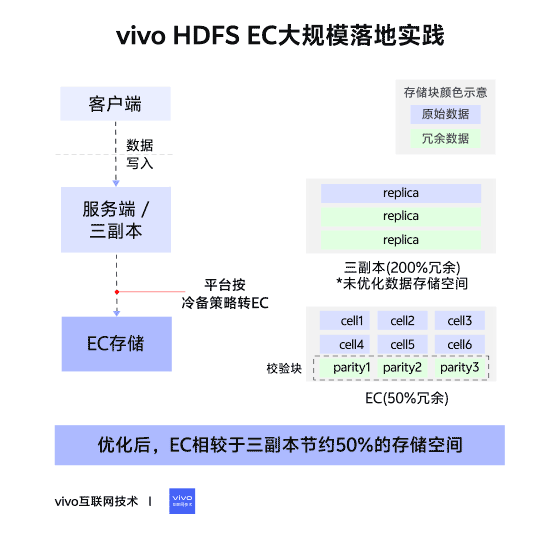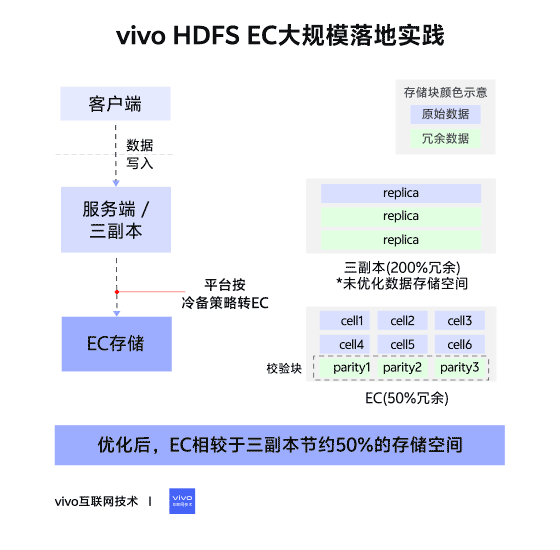
02 – Changes in Storage Layout
Triple Replication (Contiguous Block Layout)
- File → Blocks → 3 identical replicas per block.
- Continuous data storage.
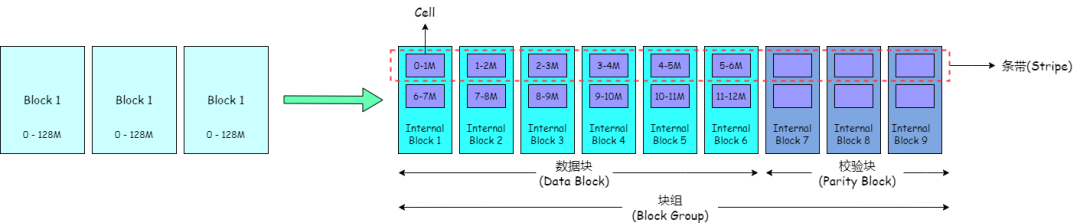
Erasure Coding (Striped Block Layout)
- File → Block Groups → Internal Blocks:
- Data Blocks (file data)
- Parity Blocks (computed parity data)
- Data split into cells, distributed across internal blocks, forming stripes.
- Tolerates up to parity block count in lost blocks.
Illustration:
---
vivo's EC Deployment Policy
- RS6-3-1024k:
- 6 = Data blocks per group
- 3 = Parity blocks per group
- 1024k = Cell size
Pros & Cons
| Policy | Storage Redundancy | Max DN Failures Tolerated |
|------------------|------------------------|--------------------------------|
| Three Replicas | 200% | 2 |
| RS-3-2-1024k | 66.6% | 2 |
| RS-6-3-1024k | 50% | 3 |
| RS-10-4-1024k | 40% | 4 |
---
03 – HDFS EC Coding Application Practice
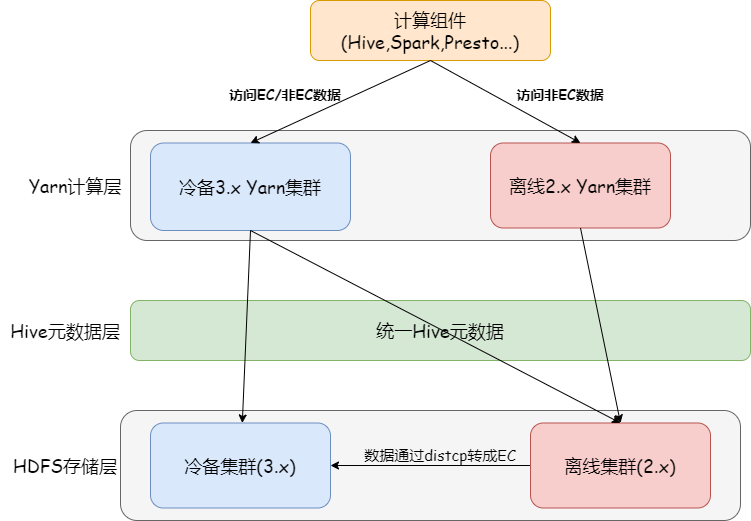
3.1 Compatibility Issues
Server Side
- EC in Hadoop requires version 3.0+ both server- and client-side.
- Transitional architecture: Cold-backup cluster running HDFS 3.1, storing EC-encoded cold data.
- By 2021: Offline cluster upgraded from HDFS 2.6 → 3.1, EC fully supported.
- By 2022: Migrated cold-backup data to offline cluster.
---
Client Side
- No backward compatibility for Client 2.x
- Encouraged migration to Spark3 for EC file access, reducing server-side dev cost and aligning with future roadmap.
---
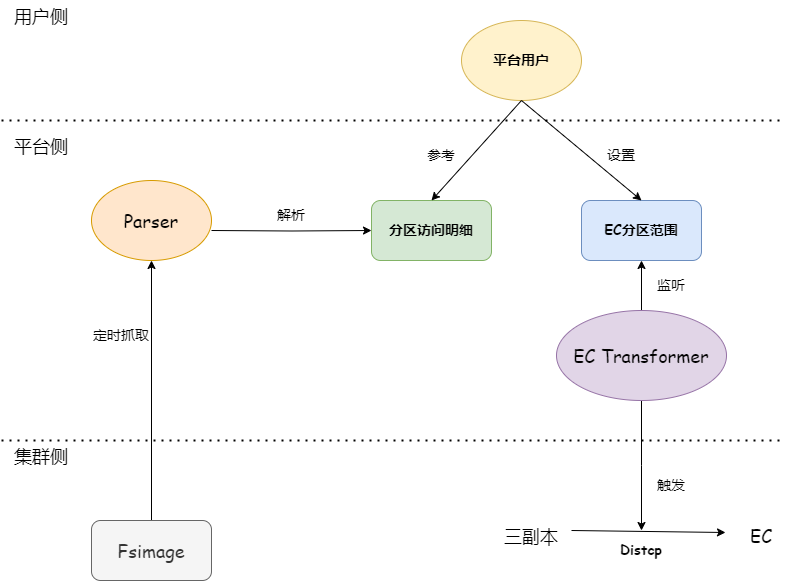
3.2 EC Asynchronous Conversion
- EC best for cold data → Conversion done via background distcp jobs from 3-replica → EC directory.
- Users set age-based EC conversion policies (e.g., data older than x days).
- Metadata preserved via directory swap method — no code change needed.
---
3.3 Distcp Data Verification
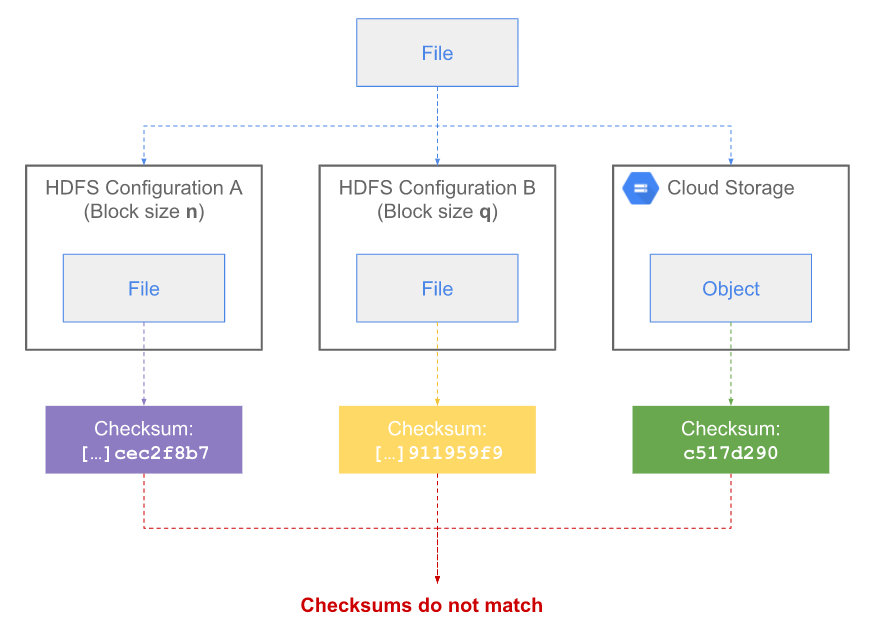
3.3.1 MD5MD5CRC (Default)
- Block-level checksum = MD5(concat chunk CRCs)
- File-level checksum = MD5(concat block checksums)
- Sensitive to block size changes.
---
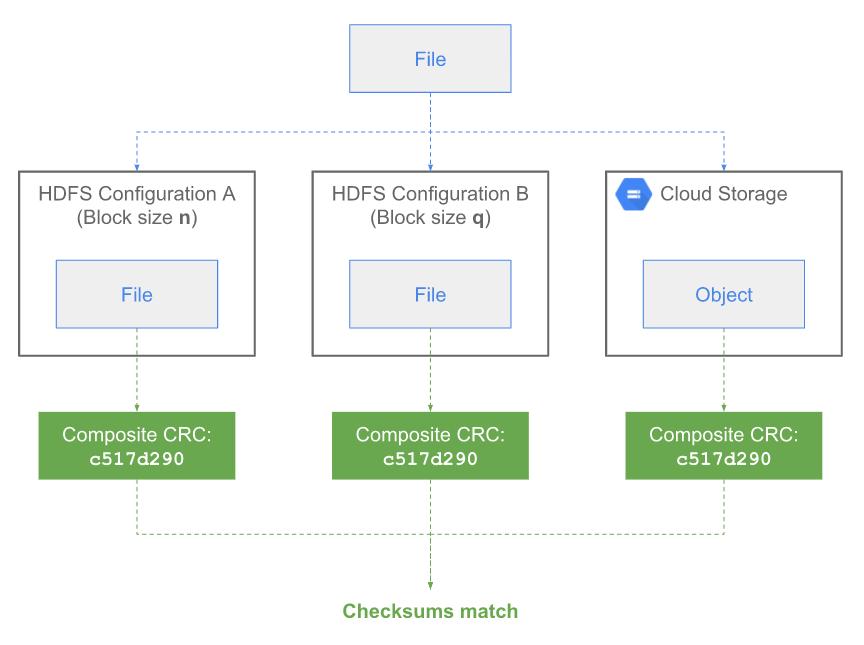
3.3.2 Composite CRC
- Mathematical combination of chunk CRCs, independent of chunk size.
- Recommended for EC-distcp verification (`dfs.checksum.combine.mode=COMPOSITE_CRC`).
- Adds partition-level checksum validation before and after transfer.
---
3.4 File Corruption & Repair
Avoiding Corruption
Patches applied:
| Patch | Purpose |
|---------------|-------------|
| HDFS-14768 | Fix EC bug in DN decommission (zero checksums). |
| HDFS-15240 | Fix buffer contamination in reconstruction. |
| HDFS-16182 | Fix heterogenous storage mismatch issues. |
| HDFS-16420 | Stability improvements in EC repair. |
---
Block Reconstruction Verification
- HDFS-15759 adds post-reconstruction validation.
- Retries on failure.
---
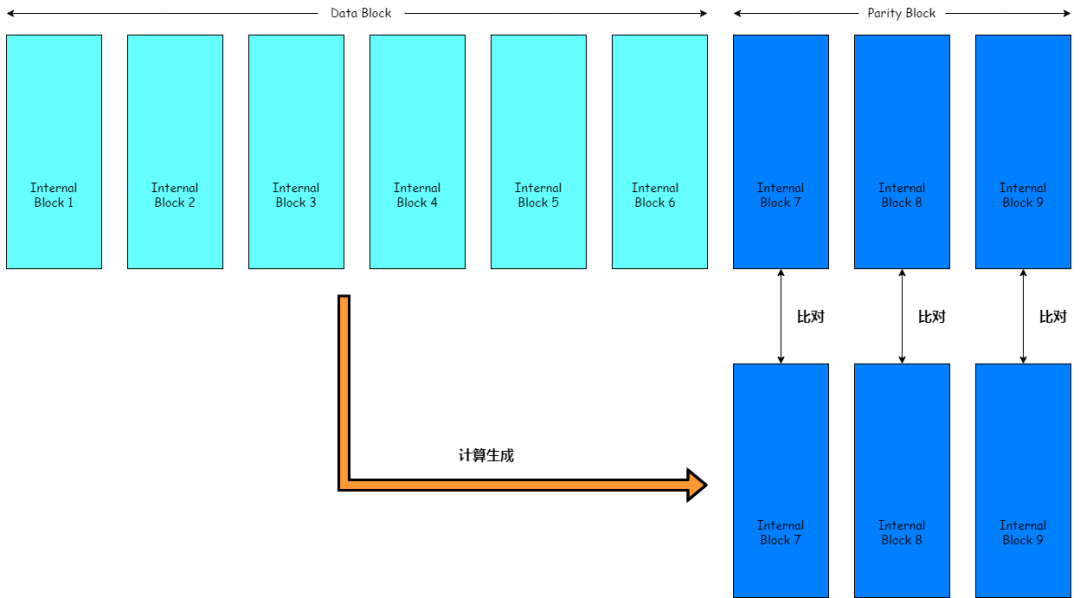
EC Batch Verification Tool
- Compares regenerated parity to original parity.
- Supports MapReduce for scale.
- Tool: hdfs-ec-validator GitHub
---
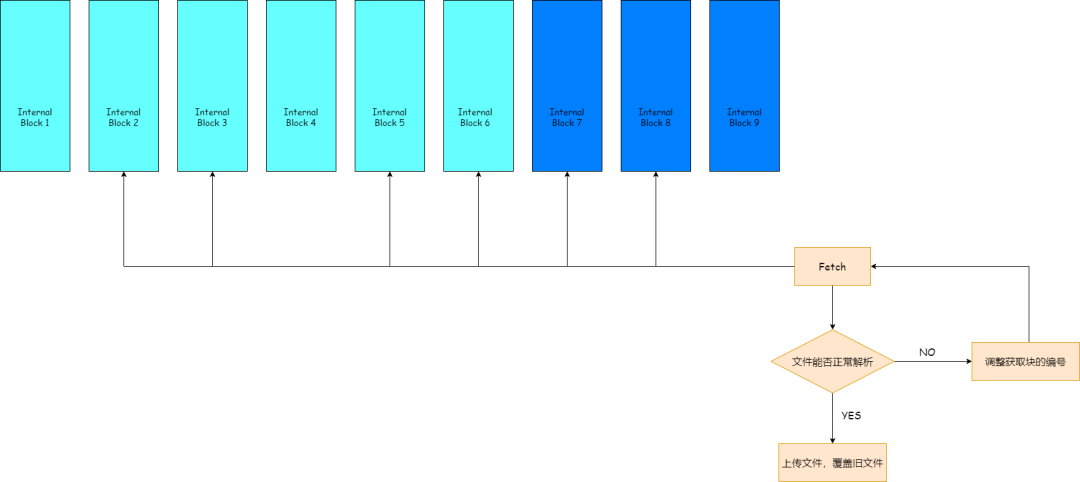
Repairing Damaged Files (ORC)
- ORC damage typically affects metadata.
- Adjusted HDFS client to read specific block combinations to rebuild parseable files.
- Overwrite damaged files with reconstructed healthy files.
---
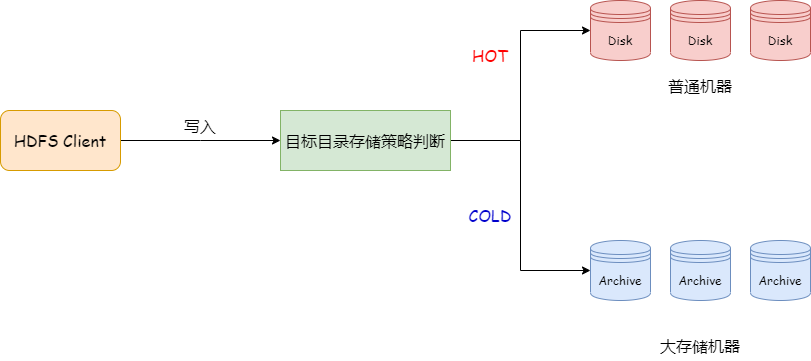
3.5 Machine Heterogeneity & Storage Strategy
- EC data stored on large-capacity archive disks via HDFS cold policy.
- Reduces TCO, aligns storage with data temperature.
---
04 – Conclusion & Outlook
Current Benefits
- RS6-3-1024k → ~50% storage savings vs triple replication.
- Hundreds of PB saved, significant cost benefits.
Challenges
- EC read performance drop for hot data.
- Need to refine tiering and optimize block reconstruction.
Future Directions
- Integrate AI-driven analytics for proactive anomaly detection and dynamic data placement.
- Explore open-source AI orchestration platforms like AiToEarn官网 for cross-platform publishing, ranking, and analytics — leveraging similar orchestration principles for EC operational optimization.
---
Would you like me to add a comparative workload performance table between Three-Replica and RS6-3-1024k, so the decision-making process on EC adoption becomes more data-driven?


