Wall Street’s Awkward Hype Over TPUs Leaves Academia Confused: Kaiming He Was a TPU Programming Expert 5 Years Ago

Wall Street’s Sudden TPU Hype
Academic and industry voices are calling out a recent market shift: Wall Street is awkwardly hyping Google’s TPU.
---
The Trigger Event
- A report claimed Meta would sign a multi-billion-dollar TPU order with Google.
- Impact on stocks:
- NVIDIA: Shares dropped up to 7% intraday, wiping out over $300B in market value.
- Google: Shares rose as much as 4%, adding ~$150B in market cap (≈ ¥1T RMB).
The Wall Street Journal framed this as Google challenging NVIDIA’s dominance.
---
Why the Surprise Is Misplaced
Industry insiders note: TPUs have long been used by major companies and researchers — including Meta, xAI, and OpenAI.
Question: If TPUs aren’t new to these players, why is the market suddenly calling them “the savior of compute”?
---
Longstanding TPU Usage

Clive Chan (OpenAI engineer) emphasized:
- Google Gemini has always been trained on TPUs.
- Claude, MidJourney, and Ilya’s SSI also ran on TPUs.
- For Meta, signing a TPU deal isn’t unusual — not using TPUs would be surprising.
---
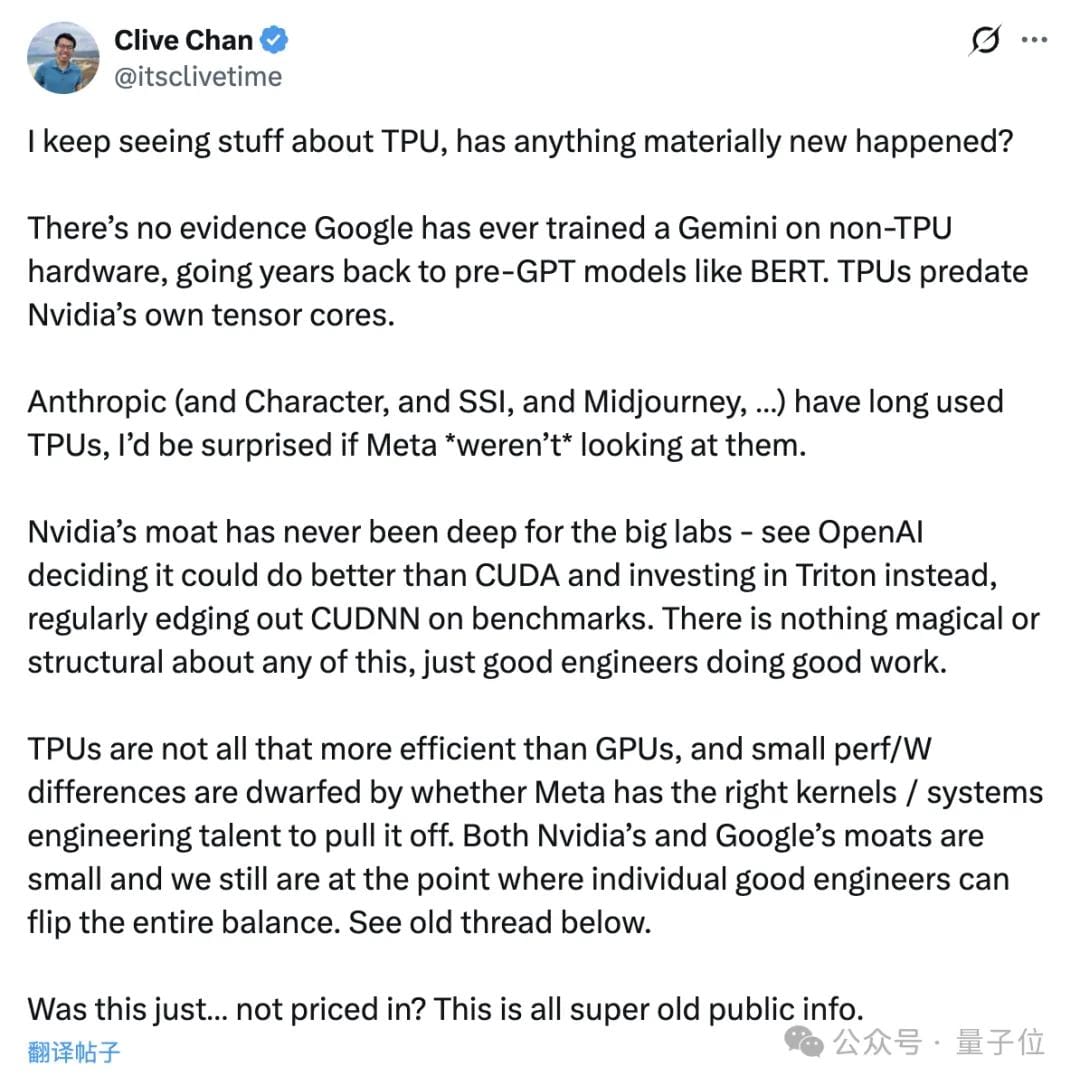
Meta’s TPU history confirmed by Xie Saining:
- TPU adoption began as early as 2020.
- Under He Kaiming’s leadership, Meta built TF/JAX codebases with projects MAE, MoCo v3, ConvNeXt v2, and DiT fully on TPUs.
- NYU research teams also relied on TPUs.
---
NVIDIA’s Reaction
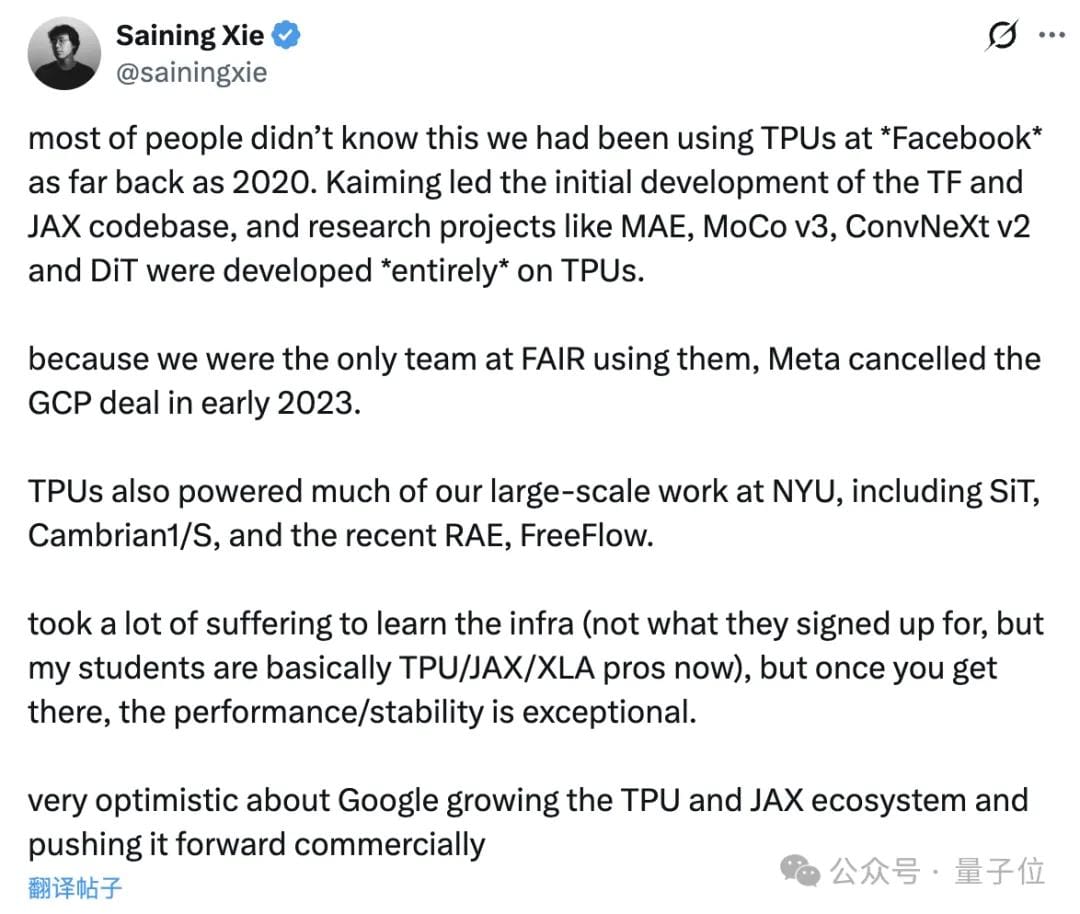
Post-announcement, NVIDIA publicly congratulated Google – then clarified:
> Its products remain far ahead, being the only platform for all AI models and all computing scenarios.
---

Fun fact: NVIDIA’s congratulatory post contained two em dashes in three sentences — prompting speculation it was AI-written.
---
Why NVIDIA’s “Moat” May Be Thin
Clive Chan’s view:
- Google, Meta, OpenAI can bypass NVIDIA easily.
- Example: OpenAI’s Triton achieved cuBLAS-level performance with ~25 lines of Python — circumventing CUDA.
---
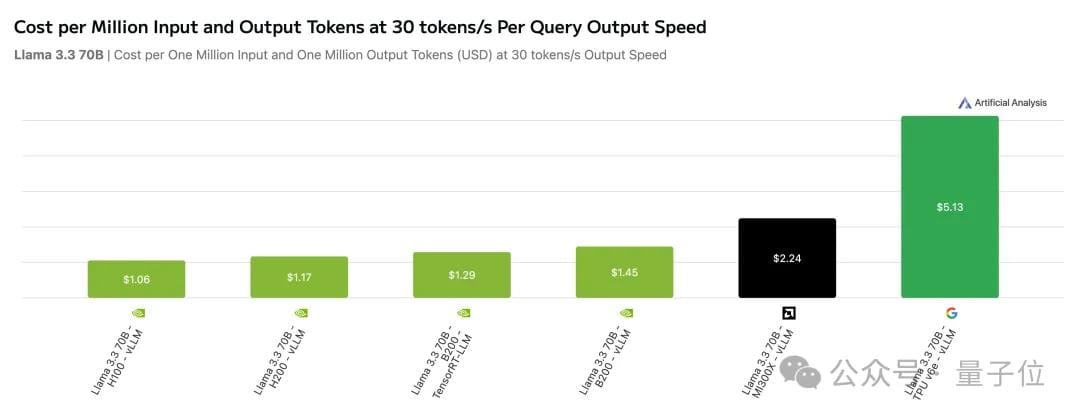
Cost Considerations
- Artificial Analysis benchmarked NVIDIA, AMD MI300X, and TPUv6e with Llama 3.3:
- H100: $1.06 per run (30 tokens/sec, 1M input+output tokens).
- TPUv6e: $5.13 — five times higher cost.
---
- TPUv7: Cost on par with B200.
- TPUv7: FP8 compute at 4.6 PFLOP/s, ~1000W power.
- GB200: FP8 compute at 5 PFLOP/s, ~1200W power.
Bottom line: Neither NVIDIA nor Google has an unbreachable moat.
---
Strategic Motivations Beyond Profit
Carlos E. Perez (Artificial Intuition):
> Most see Meta–Google TPU deal as hedging against NVIDIA. In reality, Google uses Meta to secure production slots & pricing — hedging against foundry risks.
---
Foundry Leverage Scenario
Perez’s imagined pitch:
> “I’ve signed six-year cloud contracts with Meta & Apple.
> They’ll consume 200k TPUs/year.
> Give me 25% of your N2 capacity at cost price.”
Foundry agrees — capacity gets locked up.
- Small chip firms (Groq, Cerebras, Tenstorrent) request wafers ⇒ told capacity sold out for 24 months.
- Effect: Google uses Meta/Apple’s commitments to pre-purchase cutting-edge chips — echoing Apple’s past iPhone display tactic.
Result:
- Google gains foundry-level dominance.
- Only NVIDIA can counterbalance at this scale.
---
Creator & Analyst Tools for Tracking Industry Shifts
For professionals tracking AI infra trends:
- Tools that enable multi-platform publishing & monetization help avoid reliance on single “gatekeepers” — whether in chips or content.
- Open-source global AI monetization platform.
- Publish AI-generated content across Douyin, Kwai, WeChat, Bilibili, Rednote, FB, IG, LinkedIn, Threads, YouTube, Pinterest, X.
- Offers analytics + AI模型排名.
- Helps connect TPU–GPU market insights to worldwide audiences in real time.
---
Reference Links
---
Key takeaway:
Google’s TPU sales strategy — backed by big client contracts — secures foundry capacity, reshaping competitive dynamics with NVIDIA and leaving smaller chipmakers squeezed.
In both semiconductors and content distribution, locking in future resources can be the ultimate power move.


