## Comparative Review of Three Papers on LLM Layer Usage
Recently, I came across three papers with similar research directions, and reading them side-by-side feels almost like watching episodes of a drama series:
1. **HOW DO LLMS USE THEIR DEPTH?** — *Usage Paper*
[https://arxiv.org/abs/2510.18871](https://arxiv.org/abs/2510.18871)
2. **What Affects the Effective Depth of Large Language Models?** — *Efficiency Paper*
[https://openreview.net/pdf?id=ILuhAig8xo](https://openreview.net/pdf?id=ILuhAig8xo)
3. **DR.LLM: DYNAMIC LAYER ROUTING IN LLMS** — *Dynamic Paper*
[https://arxiv.org/abs/2510.12773](https://arxiv.org/abs/2510.12773)
---
## High-Level Summary
A “one-sentence” summary is **not possible** — their conclusions conflict.
All three conceptually divide LLMs into **three segments**:
- **Input Segment** — close to the input layer
- **Output Segment** — close to the output layer
- **Middle Segment** — far from both input and output
### **Efficiency Paper**
- Measures cosine similarity between Transformer layer hidden states.
- When similarity ≫ 0, directions are not significantly changed—deemed “inefficient.”
- Claims most LLMs, regardless of size, have **similar inefficiency**.
### **Usage Paper**
- Argues that:
1. Input segment makes an **initial guess**.
2. Middle segment acts as **adjustment phase**.
3. Output segment **agonizes and reshuffles predictions**.
- Observes **major reshuffling** of Top-k rankings even in output layers.
### **Dynamic Paper**
- Adds **three-layer modes**: **skip**, **replay**, **normal play**.
- Uses Monte Carlo Tree Search (MCTS) and per-layer MLP routers to select paths.
- Achieves **slight in-domain improvement**, minor **out-of-domain drop**.
---
## 1. Key Observations
### Efficiency Paper — Valid Observation, Weak Conclusion
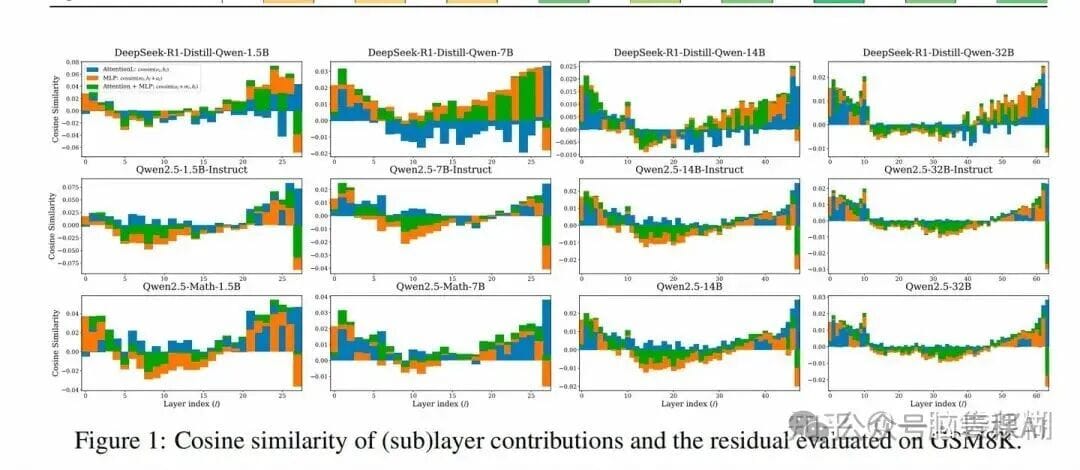
It tracks cosine similarity changes between Transformer layers and uses them to evaluate efficiency.
**Figure Analysis:**
- **Last few layers** have very high similarity across models.
- This trend is already known (*Your Transformer is Secretly Linear* showed similar patterns via regression).
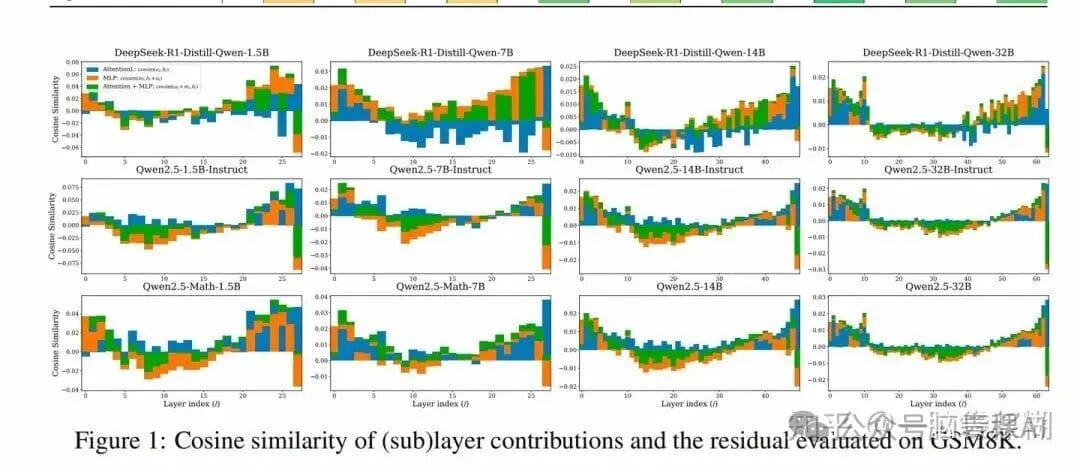
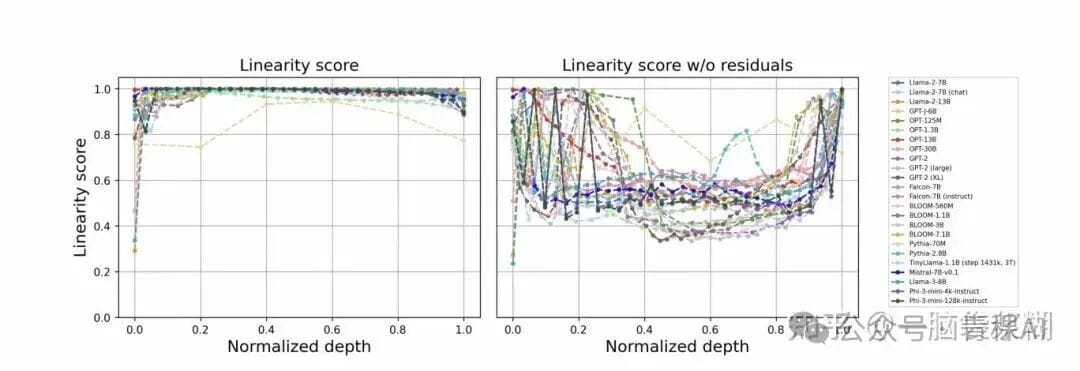
**Critique:**
Authors avoid discussing differences between **efficient** and **useful** layers, a gap in the analysis.
---
### Issue 1: Average Perspective Is Limited
Early-exit studies show task difficulty changes layer usage:
- Tokens needing **more reasoning steps → more layers used**.
### Issue 2: Determine Usefulness Before Efficiency
Layer functions vary:
- Middle layers may be **code-sensitive** and degrade performance if removed.
- Others are tuned for **math tasks**.
- Treating all layers with the same efficiency metric is like judging weightlifters and marathon runners by one test.
---
## 2. Usage Paper — Granularity Reveals Dynamics
This work inspects **Top-k ranking changes per layer**:
1. **Input stage** outputs biased to **high-frequency tokens**.
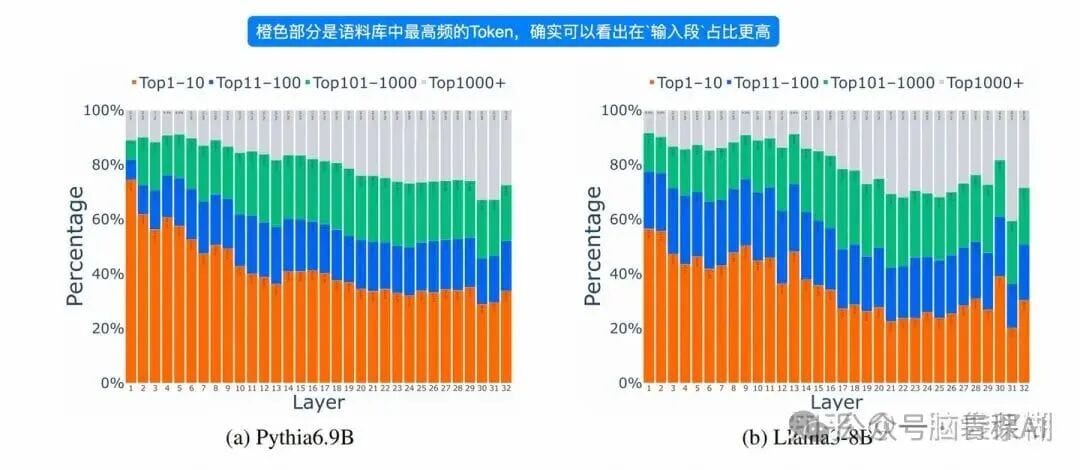
2. **Token overturn rate**: 80%+ outputs in the input stage change later.
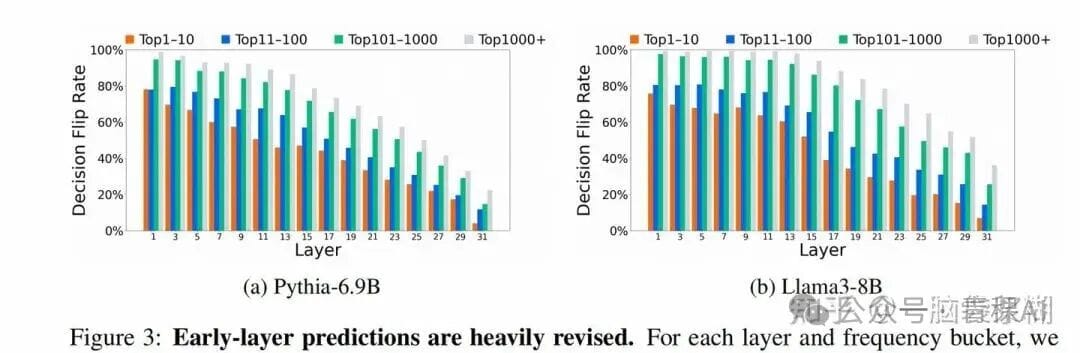
3. **Persistent reshuffling** even in output layers:
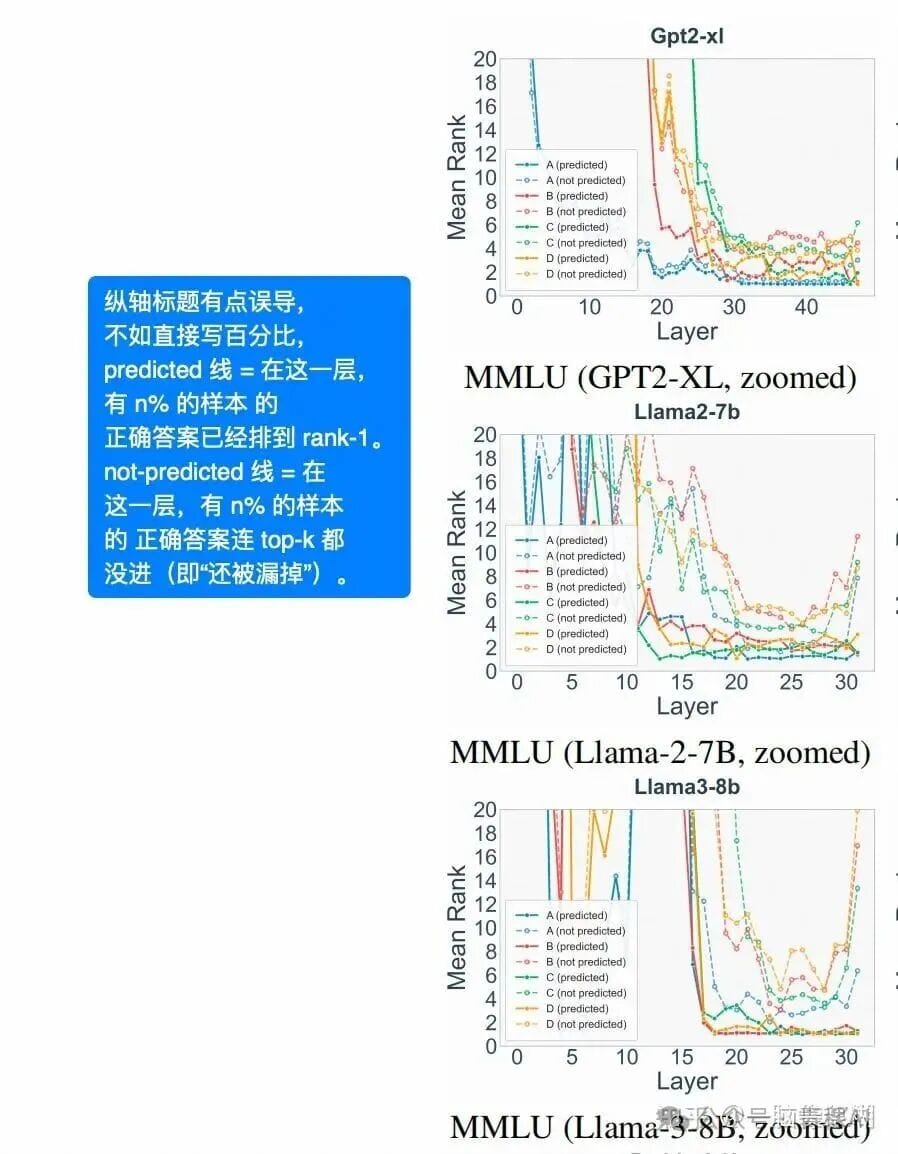
**Method:**
For each LLM layer, train a mapping matrix \(W\) to the vocabulary—predict token distribution **if output occurred at that layer**.
---
## 3. Dynamic Paper — Layer Control with Skip/Replay
This work explores **layer path optimization**:
**Mechanism:**
- Each layer gets an MLP-based router deciding **Skip / Replay / Continue**.
- Paths are sampled using **MCTS**, then routers trained.
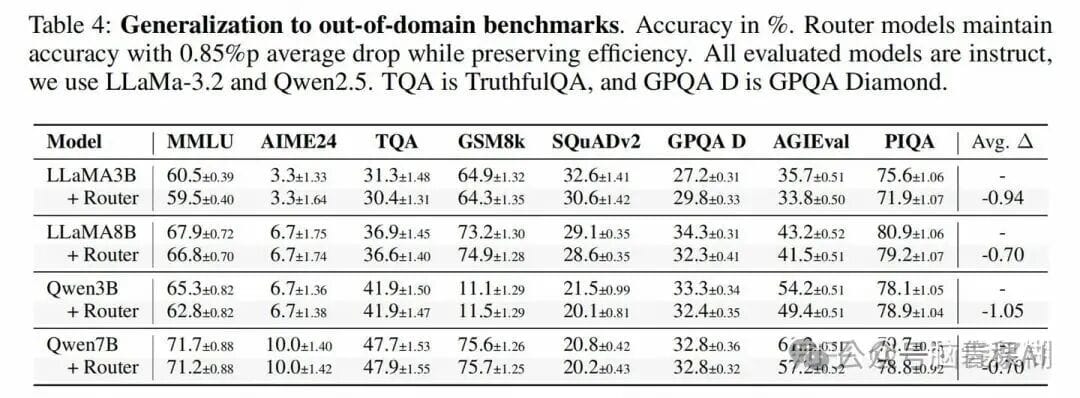
**Result:**
- In-Domain: ~+1% accuracy
- Out-of-Domain: ~–1% accuracy
- “Replay” is rare, “Skip” minor except in ARC dataset.
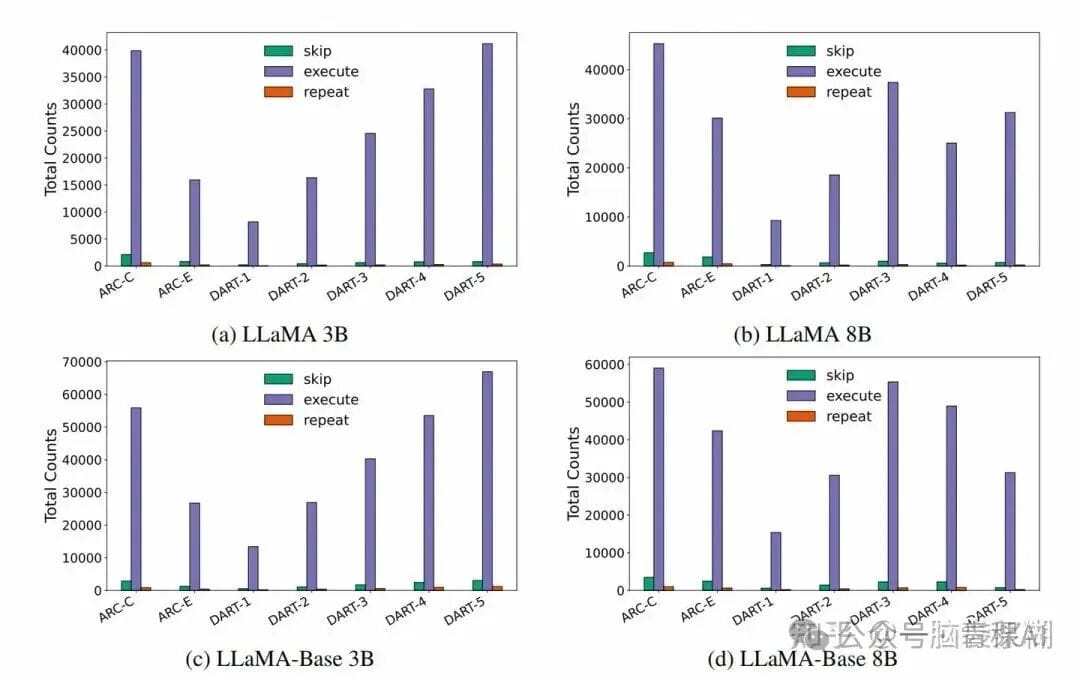
**Limitations:**
- Most MCTS-discovered paths are close to **normal forward order**.
- Not applied to **Loop Transformers**, which may limit effectiveness.
- Modified **existing models** without retraining — raising doubts about scalability.
---
## 4. Overall Evaluation
Studying Transformer layer efficiency and function is **classic yet evolving**.
With *Test-time Scaling*, finding better inference paths or **effectively deepening Transformers** is trending.
**Angles:**
- Discrete CoT acts as an **external reasoning brace**; removing it and moving deep reasoning inside layers motivates latent space reasoning.
- However, **goals remain undefined** — properties to improve, issues to fix are unclear.
**Verdict:**
1. **Efficiency Paper** — Broad measurements but low novelty.
2. **Usage Paper** — Valuable insight into per-layer prediction evolution.
3. **Dynamic Paper** — Interesting idea, constrained by non-loop application and fixed pretraining.
---
## 5. Closing & Next Steps
Seed’s *Ouro* caught my eye; its abstract frustrated me at first, but there are notable differences from existing Loop Transformers — to be covered next.
---
## AI Content Creation Context
In broader contexts, such research can intersect with **multi-platform AI publication and monetization**.
Platforms like [AiToEarn官网](https://aitoearn.ai/) offer:
- Open-source workflows for AI generation.
- Cross-platform publishing.
- Analytics and [AI模型排名](https://rank.aitoearn.ai).
These tools bridge **technical research** with **real-world impact**, making experimental Transformer strategies deployable and observable across **Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter)**.
---