What Exactly Are We Talking About When We Discuss FP8 Training?
# Large Model Intelligence|FP8 Training & Optimization Guide
With leading open-source large models such as **DeepSeek-V3**[1], **Ling 2.0**[2], and **MiniMax-M2**[3] adopting **FP8 precision** for pretraining, FP8 training has been validated at scale and recognized by top-tier research labs.
This guide explains **FP8 formats**, **training recipes**, and practical techniques for improving **computation**, **communication**, and **memory efficiency** during FP8 mixed-precision training.
It expands the first half of my talk *"FP8 Mixed Precision Training Schemes and Performance Analysis"*[4] from NVIDIA AI Open Day Beijing (June 2025), with corrections and additional context.
---
## 1. What is FP8?
FP8 is an **8-bit floating-point format**. NVIDIA introduced FP8 support with Tensor Cores in **Ada (SM89)** and **Hopper (SM90)** GPU architectures.
### Supported FP8 Formats in NVIDIA GPUs
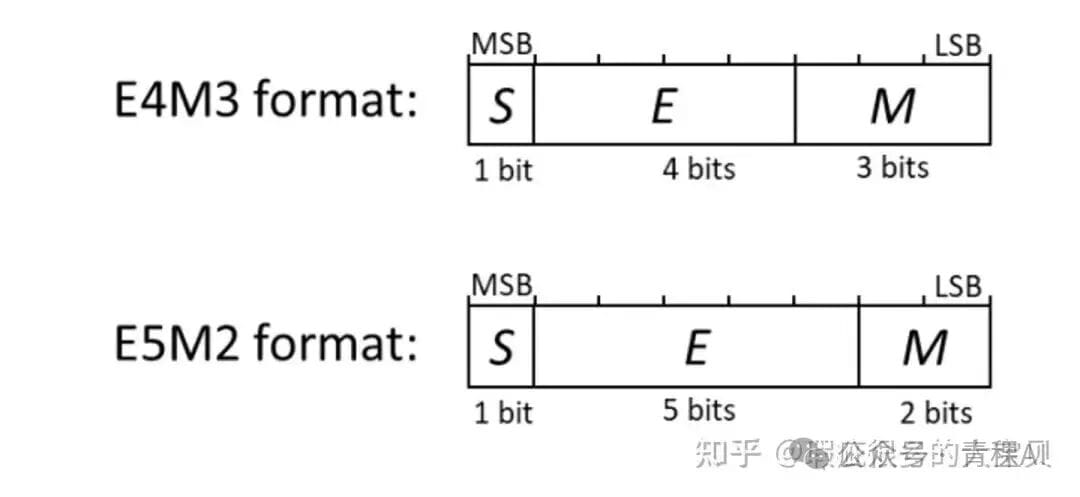
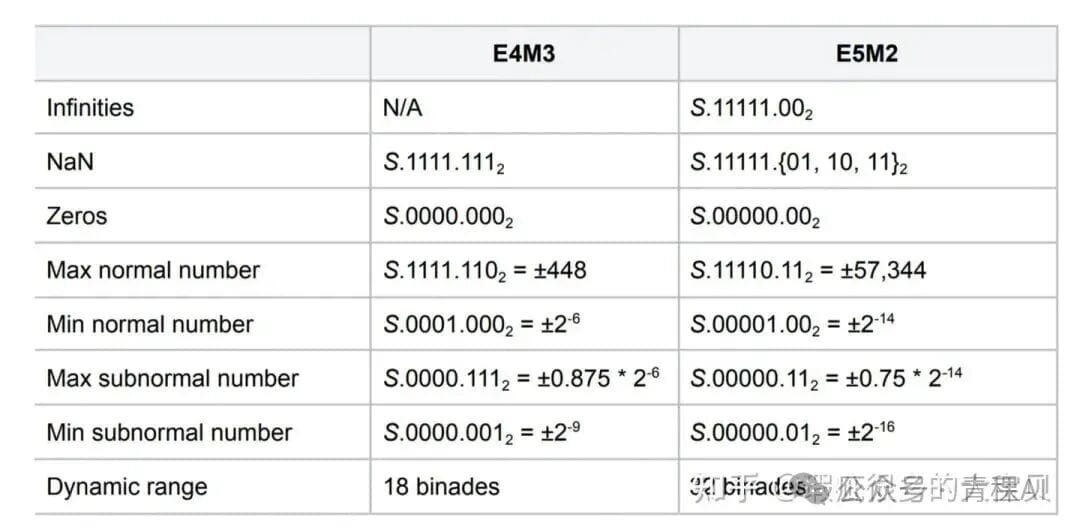
- **E4M3**: 1 sign bit, 4 exponent bits, 3 mantissa bits
→ PyTorch type: `torch.float8_e4m3fn`
- **E5M2**: 1 sign bit, 5 exponent bits, 2 mantissa bits
→ PyTorch type: `torch.float8_e5m2`
> **Why the `fn` suffix?**
> E4M3 does not reserve a code for `inf`. PyTorch appends `fn` (“finite”) to indicate this.
### OCP FP8 & MXFP8 Standards
- **OCP FP8 standard** defines these formats (E4M3, E5M2) — see Figure 2.
- **MXFP8**: Groups of 32 FP8 values share an **E8M0 scaling factor**.
Useful for finer quantization granularity.


### Why Train with FP8?
**Benefits:**
- **2× computation throughput** vs BF16 Tensor Core ops.
- **~50% memory reduction** for weights and activations.
- **Potentially 50% communication savings** if FP8 is used end-to-end.
**Challenges:**
- Narrower numerical range and precision → Requires careful scaling.
---
## 2. FP8 Recipes
### Why a "Recipe"?
FP8 precision demands **scaling algorithms** to map values into the representable range.
- **BF16**: No scaling required.
- **FP16**: Requires a **global scale factor**.
- **FP8**: Scaling typically applied **per tensor** or per **tile** (sub-channel/group/block).
**Scaling rule:**
Scale the **amax** (absolute max) in a block to match FP8's max representable value; scale other values proportionally.
---
### Common FP8 Recipes in NVIDIA Transformer Engine (TE)
#### 2.1 Per-Tensor Scaling (Hybrid Format)
- Activations & weights: **E4M3**
- Gradients: **E5M2**
- Variations:
- **Delayed scaling**: Uses historical amax values for speed; may hurt convergence for very large models (>7B).
- **Current (“live”) scaling**: Uses amax from the current tensor for better accuracy.
Example: Nemotron-H-56B[6]
#### 2.2 Blockwise Scaling (Pure E4M3)
- Input/grad: **1×128 tiles** (1D)
- Weights: **128×128 tiles** (2D)
- Popular in DeepSeek-V3 and other large models.
#### 2.3 MXFP8 Scaling (Pure E4M3 + E8M0)
- Input/grad/weights: **1×32 tiles**, scale in **E8M0** format
- **Finer** than Blockwise scaling; preferred on Blackwell GPUs.
---
## 3. FP8 Computation Workflows
FP8 accelerates **fprop**, **dgrad**, and **wgrad** GEMMs by quantizing inputs. Outputs (BF16/FP32) usually **stay unquantized**.
### Hardware-Specific GEMM Details
- **Hopper (SM90)**: FP8 GEMM supports only **TN layout**; requires transposition ops for dgrad/wgrad.
- **Blackwell (SM100)**: FP8 GEMM supports **all layouts**; eliminates explicit transpose step.
---
### 3.1 Per-Tensor Current Scaling
#### TE Usage:with fp8_autocast(fp8_recipe=Float8CurrentScaling()):
model()
#### MCore CLI:--fp8-format hybrid
--fp8-recipe tensorwise
**Hopper Flow:** Quantize with a fused cast + cast_transpose; cache weights after first micro-batch.
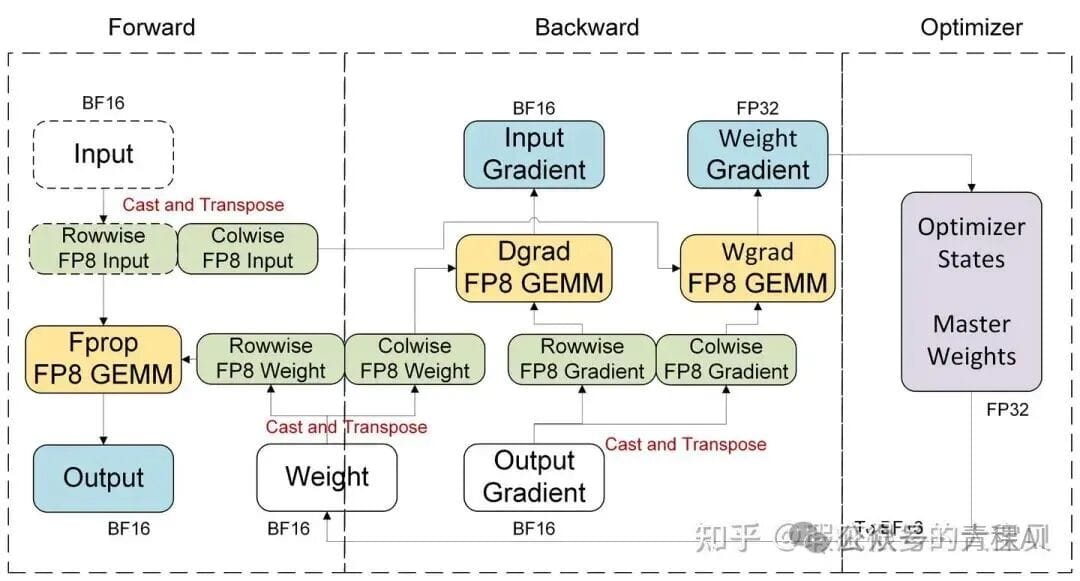
**Blackwell Flow:** Single FP8 quantization per tensor — no transpose copy needed.
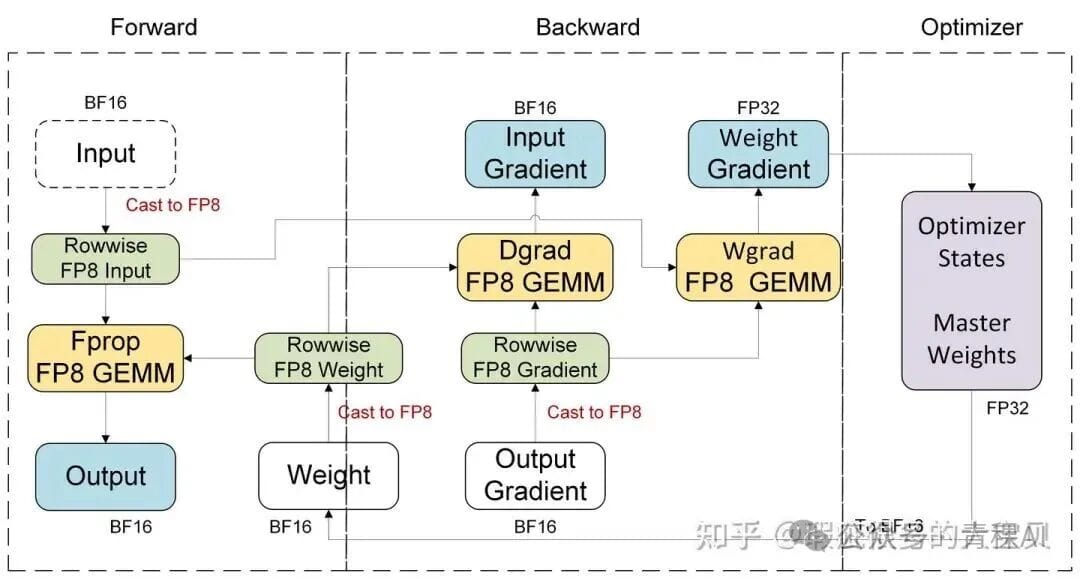
---
### 3.2 Blockwise Scaling
TE:with fp8_autocast(fp8_recipe=Float8BlockScaling()):
model()
CLI:--fp8-format e4m3
--fp8-recipe blockwise
- Hopper: Native support for **128×128 @ 1×128** and **1×128 @ 1×128** blockwise GEMMs from CUDA 12.9.
- Blackwell: Simulate blockwise via MXFP8 tiles if needed.
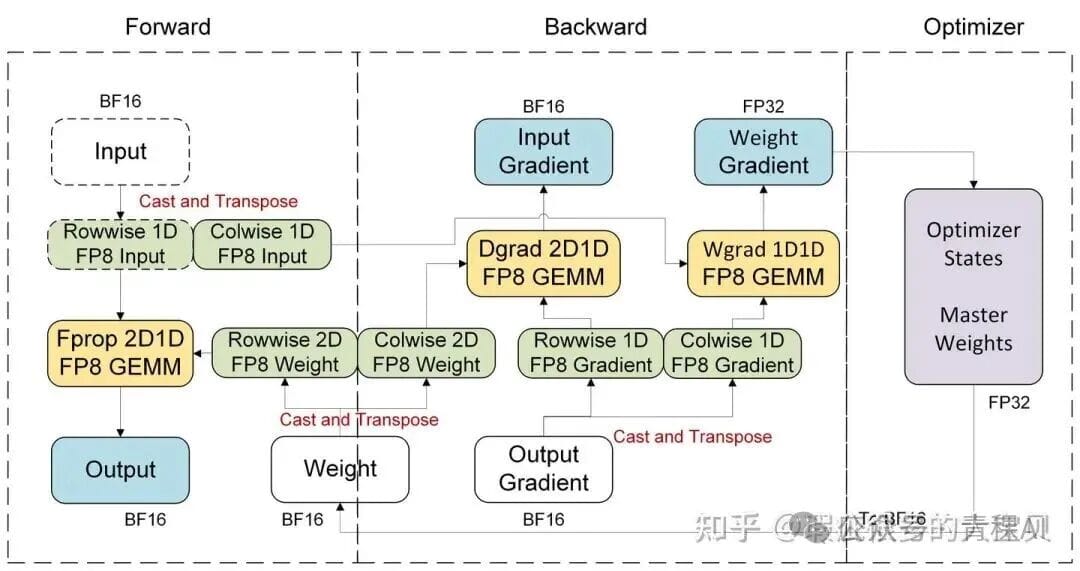
---
### 3.3 MXFP8 Scaling (Blackwell only)
TE:with fp8_autocast(fp8_recipe=MXFP8BlockScaling()):
model()
CLI:--fp8-format e4m3
--fp8-recipe mxfp8
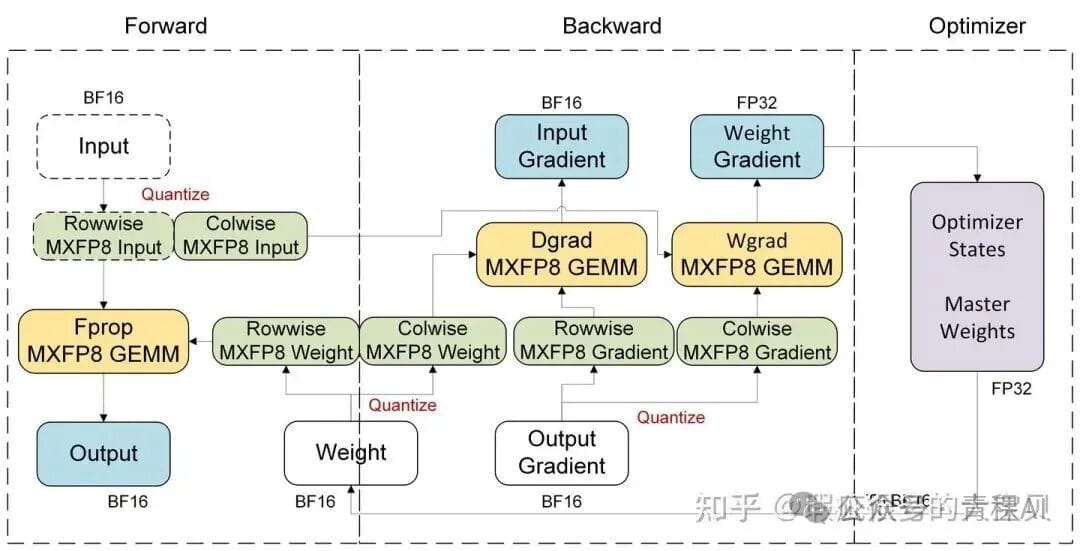
> **Note:** 1D quantization for weights requires **two copies** (rowwise + colwise).
---
## 4. FP8 Storage Implications
### 4.1 FP8 Weights
FP8 weights are usually quantized from BF16 weights → Requires **both formats in memory**, sometimes increasing usage.
To use **FP8 as primary weights**:
- Quantize **directly** from FP32 master weights.
- Requires a **QuantizedTensor** type to hold scale + multiple layouts.
- Must adapt to **Distributed Optimizer (ZeRO-1)** sharding patterns.
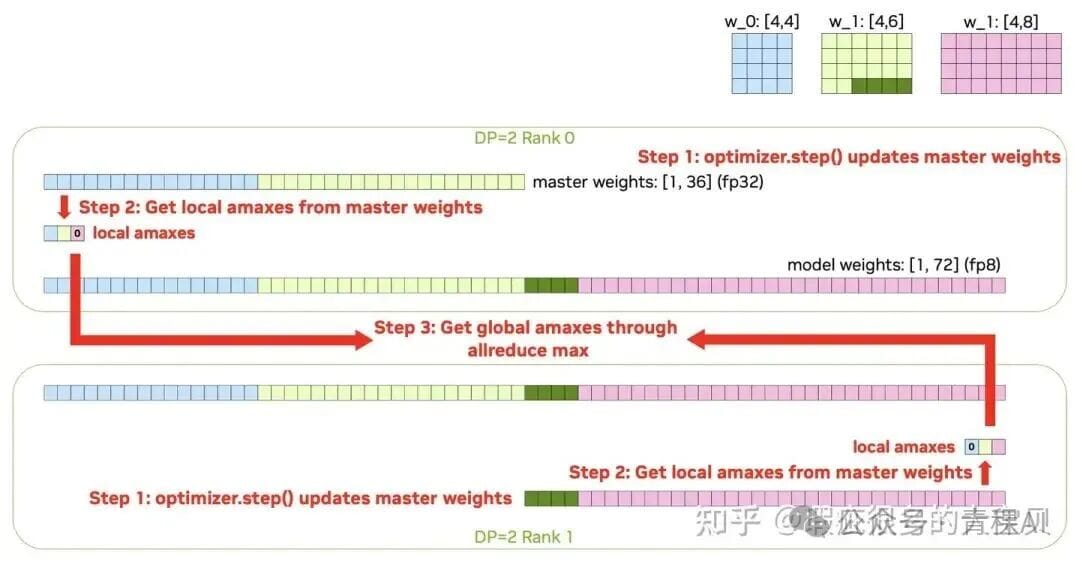
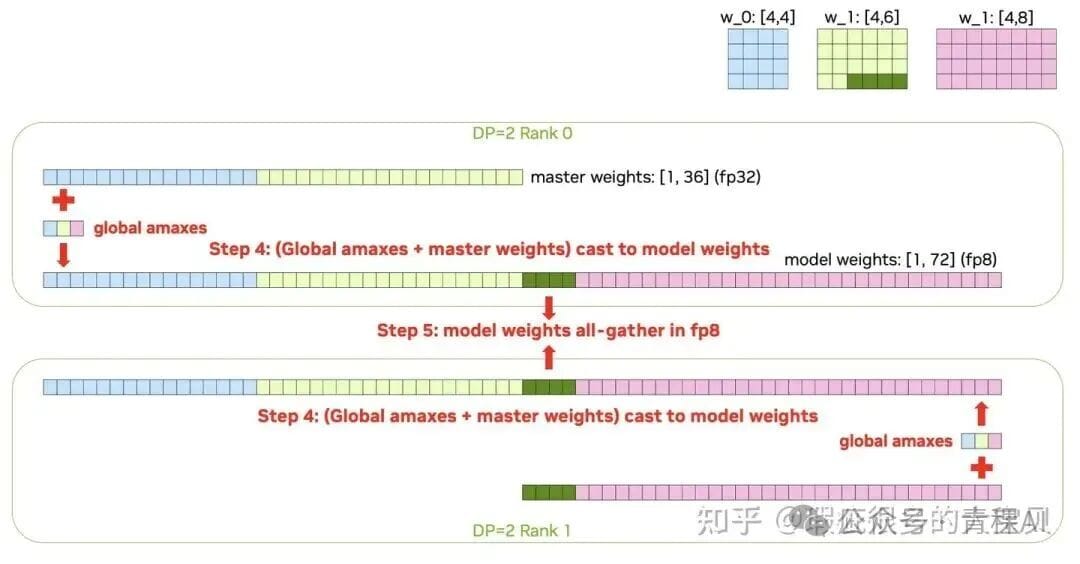
**FP8 Primary Weights Process:**
1. Compute local amax per parameter shard.
2. Allreduce to get global amax.
3. Quantize shards to FP8.
4. AllGather FP8 weights.
---
### 4.2 FP8 Activations
- Store **only colwise FP8 input** for backward pass → Saves ~50% vs BF16.
- **Special cases**: SDPA outputs + Projection Linear inputs → May double buffer & consume 1.5× memory.
---
## 5. FP8 Communication
### Where FP8 Helps:
- **Data Parallel (DP)**: Parameter allgather in FP8.
- **Tensor Parallel (TP)**: AllGather input shards in FP8; must match non-TP quantization results.
- **Expert Parallel (EP)**: Possible if activations use matching 1D quantization (token dimension).
#### Example: TP FP8 AllGather
1. Compute local amax per shard.
2. Allreduce in TP group to get global amax.
3. Quantize locality-preserving FP8 rowwise & colwise.
4. AllGather FP8 for forward/backward GEMM.
---
## 6. Key Takeaways
- **Best balance**: 1D quantization for activations (token dimension) + 2D quantization for weights.
- **MxFP8** offers finer granularity but can require more copies for weights depending on layout.
- **Primary FP8 weights** approach matches BF16 persistent memory, saving activations footprint.
- Communication FP8 acceleration must avoid precision drift → only safe when mathematically equivalent to FP8-internal conversion.
---
## References
[1] DeepSeek-V3 – [https://arxiv.org/abs/2412.19437](https://arxiv.org/abs/2412.19437)
[2] Ling 2.0 – [https://arxiv.org/abs/2510.22115](https://arxiv.org/abs/2510.22115)
[3] MiniMax-M2 – [https://huggingface.co/MiniMaxAI/MiniMax-M2](https://huggingface.co/MiniMaxAI/MiniMax-M2)
[4] FP8 Mixed Precision Training Scheme & Performance Analysis – [https://www.bilibili.com/video/BV1mpMwz9Ey5](https://www.bilibili.com/video/BV1mpMwz9Ey5)
[5] OCP FP8 Spec – [https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf](https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf)
[6] Nemotron-H-56B – [https://arxiv.org/abs/2504.03624](https://arxiv.org/abs/2504.03624)
[7] Row vs Column Major – [https://www.adityaagrawal.net/blog/deep_learning/row_column_major](https://www.adityaagrawal.net/blog/deep_learning/row_column_major)
[8] NVFP4 Recipe – [https://arxiv.org/abs/2509.25149](https://arxiv.org/abs/2509.25149)
---