What Exactly Is the Cambrian Idea by Xie Saining, Fei-Fei Li, and LeCun?
Cambrian — A Breakthrough in AI Spatial Perception
> “Cambrian” is one of the hottest names in the AI world right now.
> Led by Xie Saining, with support from Fei-Fei Li and Yann LeCun, the project has earned widespread acclaim.
---
What Is Cambrian?
Unlike silicon-based chip research, Cambrian-S focuses on enabling artificial intelligence to truly perceive the world.
Its flagship achievement is a multi-modal video large model excelling in:
- Spatial perception
- General video and image understanding
It delivers state-of-the-art results in short-video spatial reasoning.
Critically, the addition of a predictive perception module allows Cambrian-S to handle spatial reasoning in ultra-long videos — a long-standing weakness in mainstream models.
---
Development History
Cambrian-1 (June 2024)
An open exploration of multi-modal image models with breakthroughs in five areas:
- Comprehensive Evaluation
- Tested over 20 vision encoders and combinations (language-supervised, self-supervised, etc.), clarifying strengths and application scenarios.
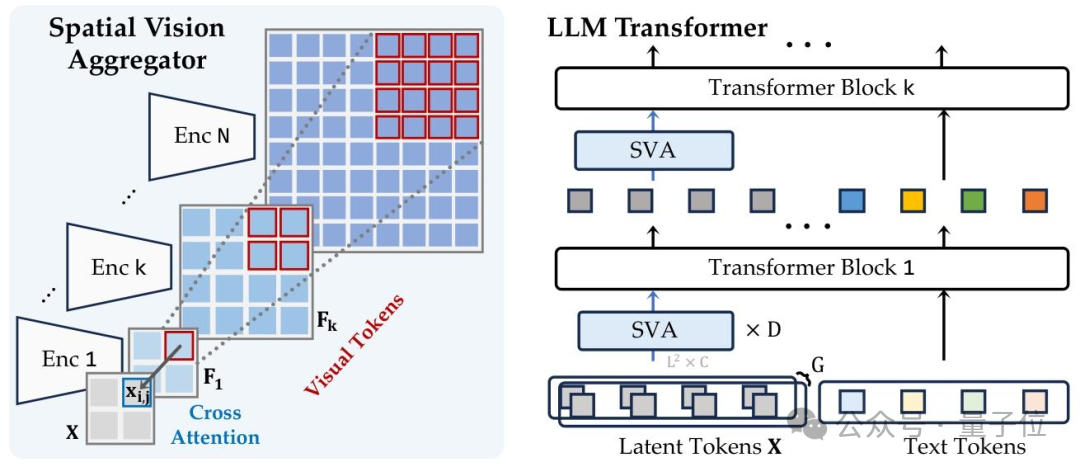
- Spatial Visual Aggregator (SVA)
- Efficiently integrates multi-source visual features with fewer visual tokens, balancing high resolution and computational efficiency.
- Optimized Visual Instruction Dataset
- Selected 7M high-quality samples from 10M raw entries, balanced categories, improved interaction via systematic prompting.
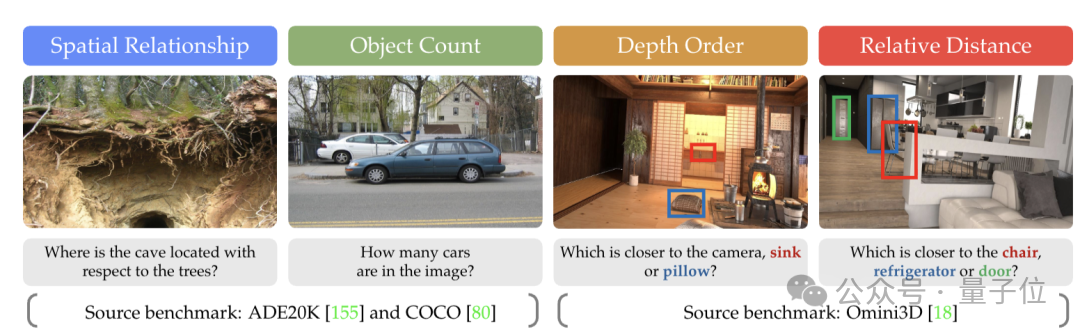
- CV-Bench Benchmark
- Evaluates 2D/3D vision understanding, addressing inadequacies in current visual capability metrics.
- Optimal Training Scheme
- Confirmed that two-stage training and unfreezing vision encoders improve performance.

---
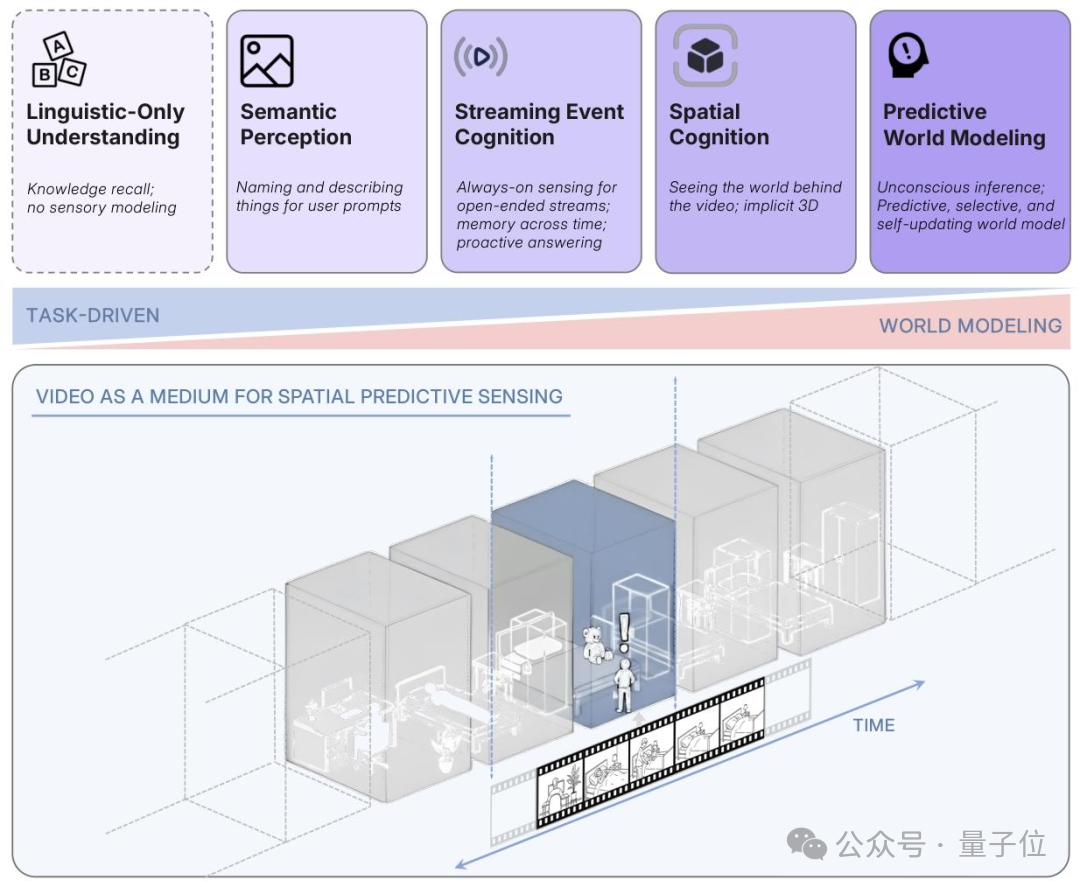
Rethinking Multi-Modal Intelligence
Instead of scaling to Cambrian-2 or Cambrian-3, the team asked:
> “What is true multi-modal intelligence?”
They observed that many models “describe” images by converting visual input into text — similar to understanding a caption without truly seeing.
Hyper-Perception
A new concept proposed by the team:
> How digital life can truly experience the world — taking in input streams and learning from them.

Key capabilities:
- Remembering object positions
- Understanding spatial relationships
- Predicting future movements
Xie’s view:
Before hyper-perception, superintelligence is impossible.
---
Why Focus on Video?
Human perception relies on continuous sequences, not isolated frames.
The team’s aim became video spatial hyper-perception — reading spatial relationships from video, e.g.:
> “A person walks from the doorway to the sofa, picks up a book from the table.”
---
Building the Benchmark: VSI-SUPER
To train and test spatial perception, Cambrian created VSI-SUPER, with tasks such as:
- Long-Term Spatial Memory (VSR): AI recalls unusual object locations after watching hours of roaming video.
- Continuous Counting (VSC): AI counts total instances of certain objects in a long video.


Current Models’ Performance:
Commercial solutions like Gemini-Live and GPT-Realtime score <15% accuracy on 10-min videos, failing completely on 120-min clips.

---
Spatial Perception Training
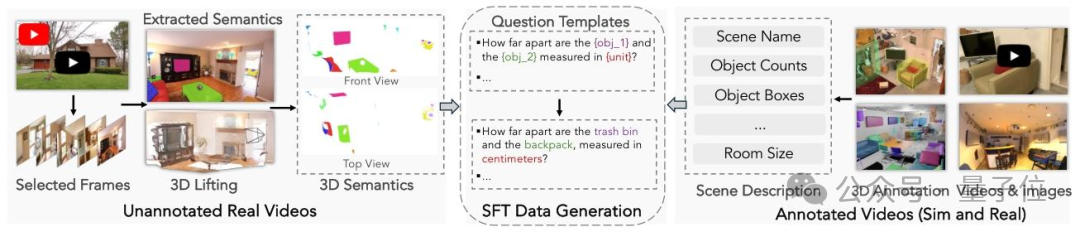
VSI-590K Dataset
Contains 590K training samples — real and simulated spatial scenes, annotated with positions and dynamic changes.
---
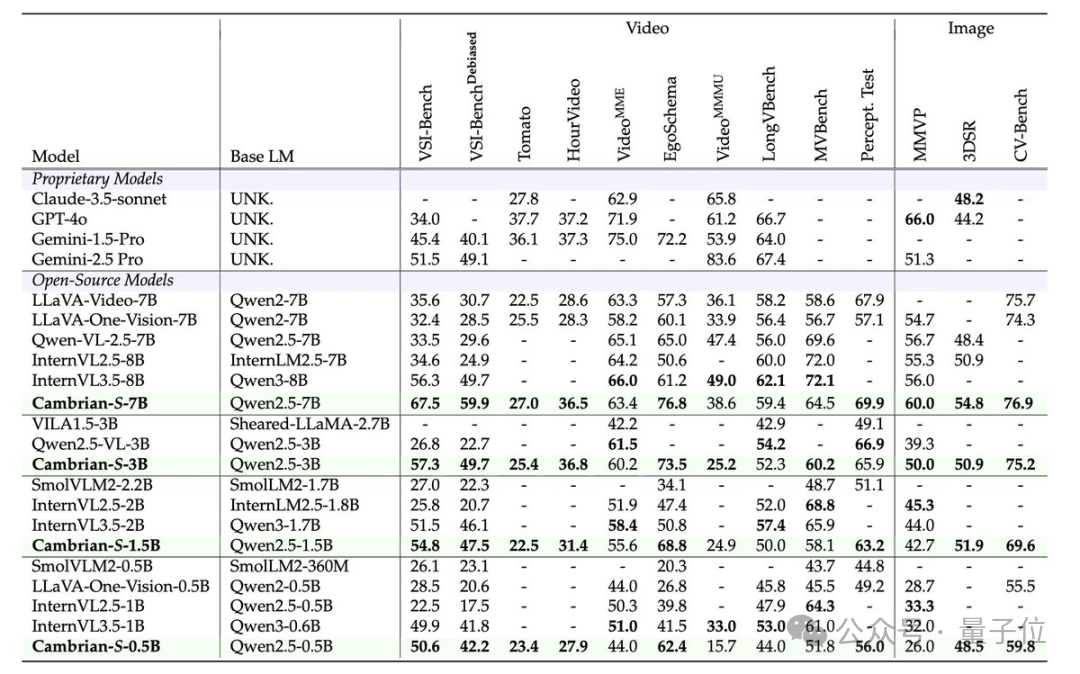
Cambrian-S Model Family
- Size Range: 0.5B to 7B parameters
- Targeted Design: Not oversized, but highly specialized.
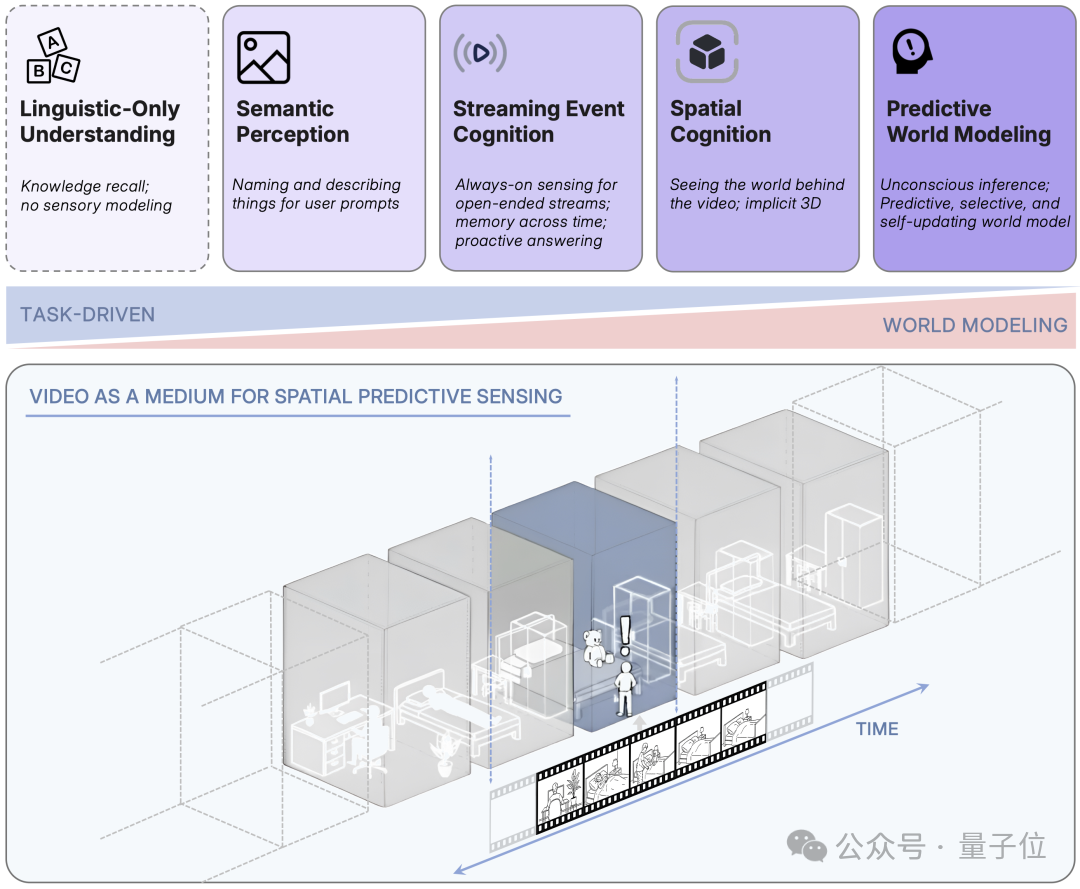
Core Training Strategy:
Predict-the-next-frame mechanism using “surprise” metrics to enhance spatial reasoning in ultra-long videos.
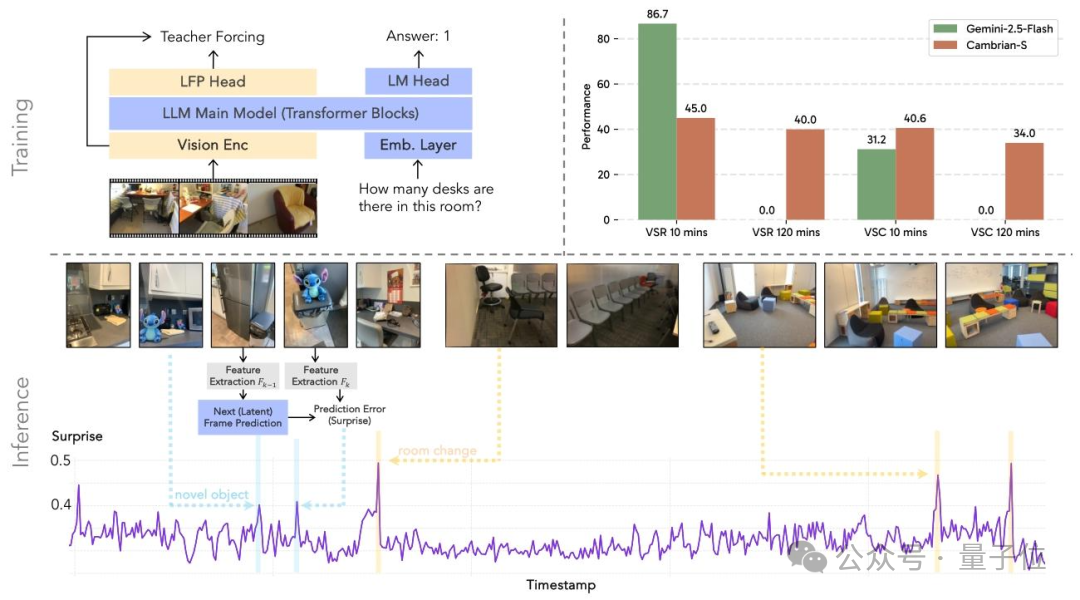
---
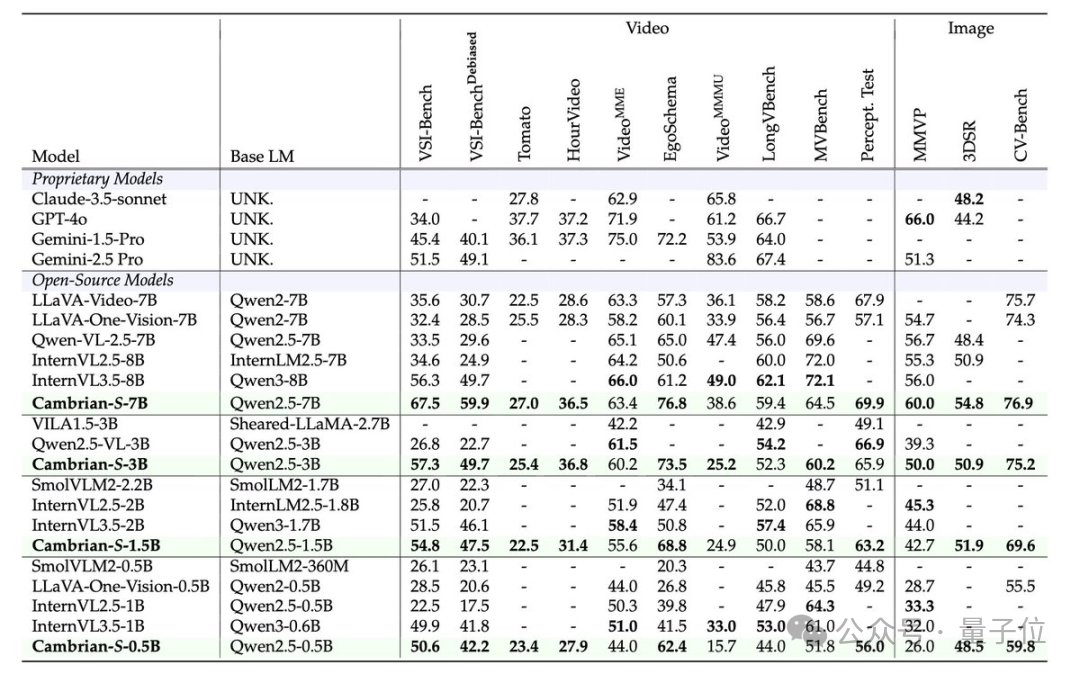
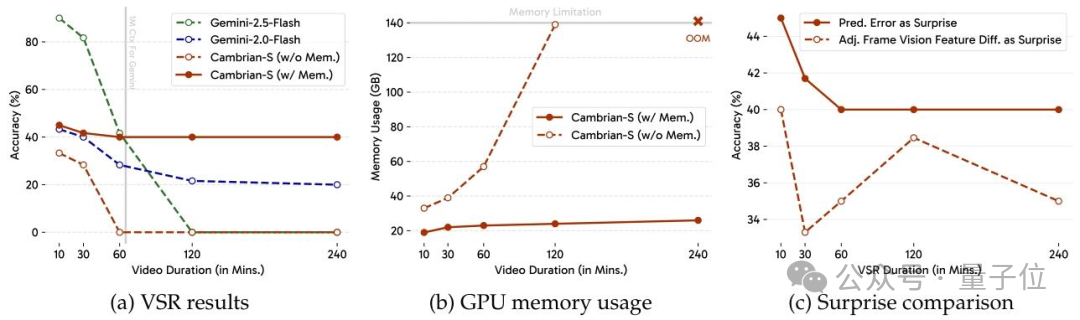
Results
- SOTA in short-video spatial reasoning
- 30%+ accuracy gain over open-source models on VSI-SUPER
- Outperforms some commercial solutions
- Efficient GPU memory use without brute-force scaling
---
Key Contributors
- Xie Saining — Project lead, backed by Fei-Fei Li and Yann LeCun
- Shusheng Yang — NYU PhD candidate, Qwen contributor, ex-Tencent intern
- Jihan Yang — Postdoc at NYU Courant Institute
- Pinzhi Huang — NYU undergrad, ex-Google Gemini intern
- Ellis Brown — PhD student at NYU Courant, CMU master’s graduate




---
References
- https://cambrian-mllm.github.io/
- https://x.com/sainingxie/status/1986685063367434557
---
AI Content Ecosystem Synergy
In the broader AI creator landscape, breakthroughs like Cambrian-S align with open-source monetization frameworks like AiToEarn官网.
Benefits for Researchers & Creators:
- AI-generated content creation
- Cross-platform publishing
- Analytics & model ranking
Supported Platforms:
Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter
This bridge from AI research to scalable monetization helps ensure innovations in perception reach wider audiences.


