Who Is the King of AI? Controversial AI Evaluations and the Rise of LMArena

AI Model Showdown: From GPT vs Claude to LMArena


The race for AI supremacy is intense: OpenAI’s GPT, Anthropic’s Claude, Google’s Gemini, and China’s DeepSeek are all vying for the crown.
But with benchmark charts increasingly gamed and manipulated, ranking "the strongest model" has become subjective—until a live, user‑driven ranking platform called LMArena arrived.

Across text generation, vision understanding, search, text‑to‑image, and text‑to‑video, LMArena hosts thousands of daily head‑to‑head battles, with regular users voting anonymously for the better answer. Increasingly, AI researchers see rethinking model evaluation as one of the most crucial tasks in the next phase of AI development.
---
1. Why Traditional Benchmarks Are Losing Relevance
From MMLU to BIG‑Bench: The Old Guard
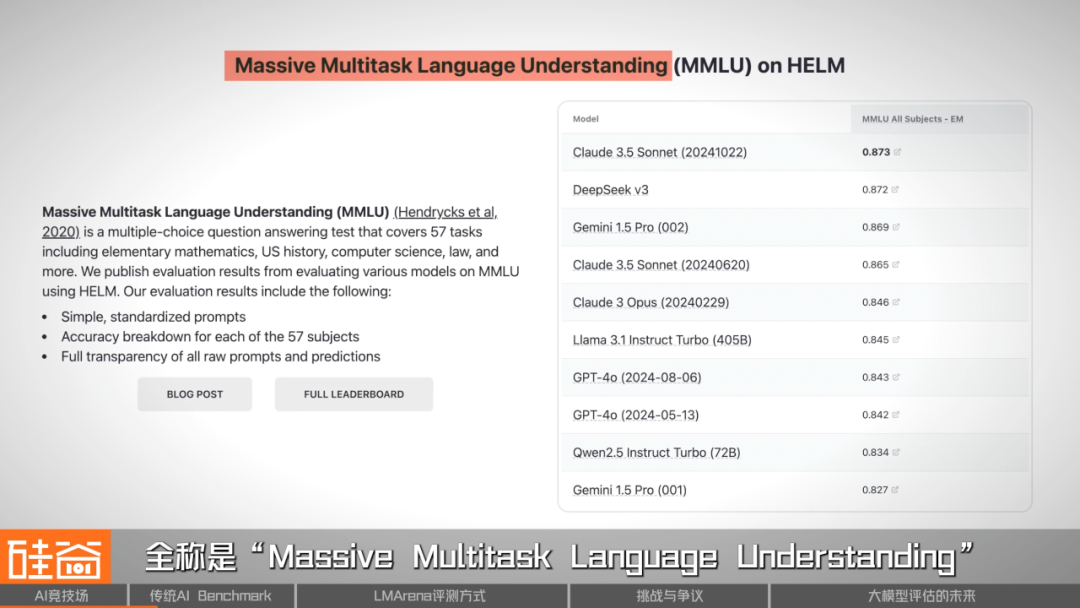
Before LMArena, large AI models were evaluated using fixed datasets like MMLU, BIG‑Bench, and HellaSwag. These covered:
- MMLU — 57 subjects from high school to PhD level, from history to law to deep learning.
- BIG‑Bench — reasoning and creativity tasks (e.g., explaining jokes, logic puzzles).
- HellaSwag — everyday scenario prediction.

Advantages:
- Uniform standards
- Reproducible results
For years, better scores meant better models. But this static, exam‑style approach is showing cracks.
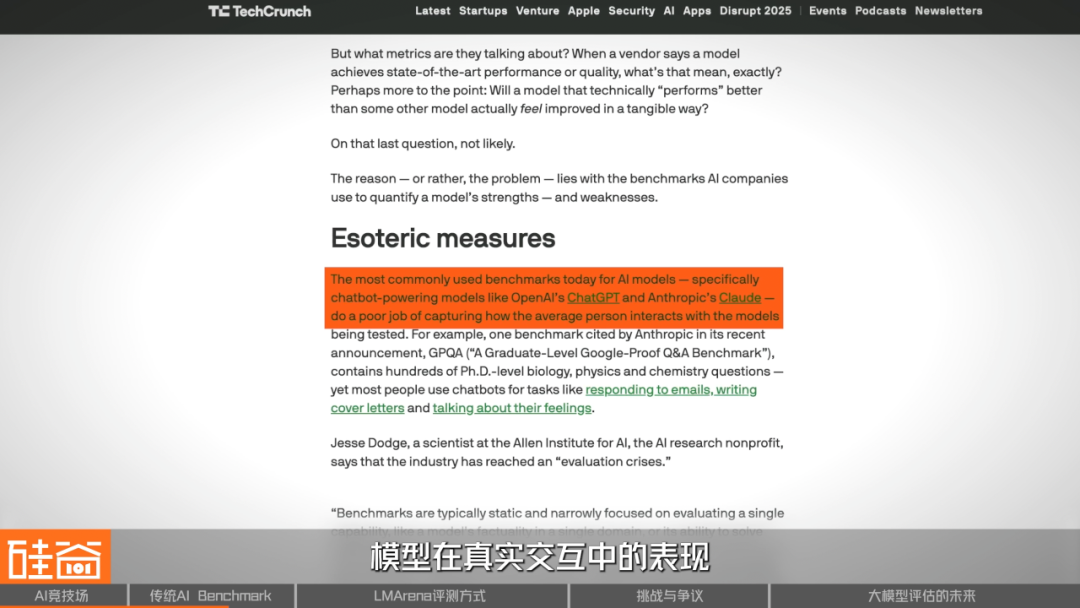
Limitations Emerging

Key problems include:
- Question Bank Leakage — Many test questions appear in training datasets.
- Static Settings — No reflection of interactive, real‑world use cases.
> Banghua Zhu (UW & NVIDIA):
> Static benchmarks suffer from overfitting and data contamination. With only a few hundred questions, models memorize answers rather than demonstrate intelligence. Arena‑style evaluations emerged to counter these issues.
---
2. LMArena: From Research Prototype to Global Arena
Origins
- Created May 2023 by LMSYS, a nonprofit involving leading universities.
- Team included Lianmin Zheng, Ying Sheng, Wei‑Lin Chiang.
- Initially an experiment to compare open‑source Vicuna vs Stanford’s Alpaca.

Two Early Methods Tried:
- GPT‑3.5 as judge → became MT‑Bench.
- Human pairwise comparison → evolved into Chatbot Arena.

In Chatbot Arena:
- User enters a prompt.
- Two random models (e.g., GPT‑4, Claude) generate answers anonymously.
- User votes for the better side.
- Models revealed only after voting.

Scores use an Elo‑style Bradley‑Terry model:
- Win = score rises
- Loss = score drops
- Rankings converge over time.
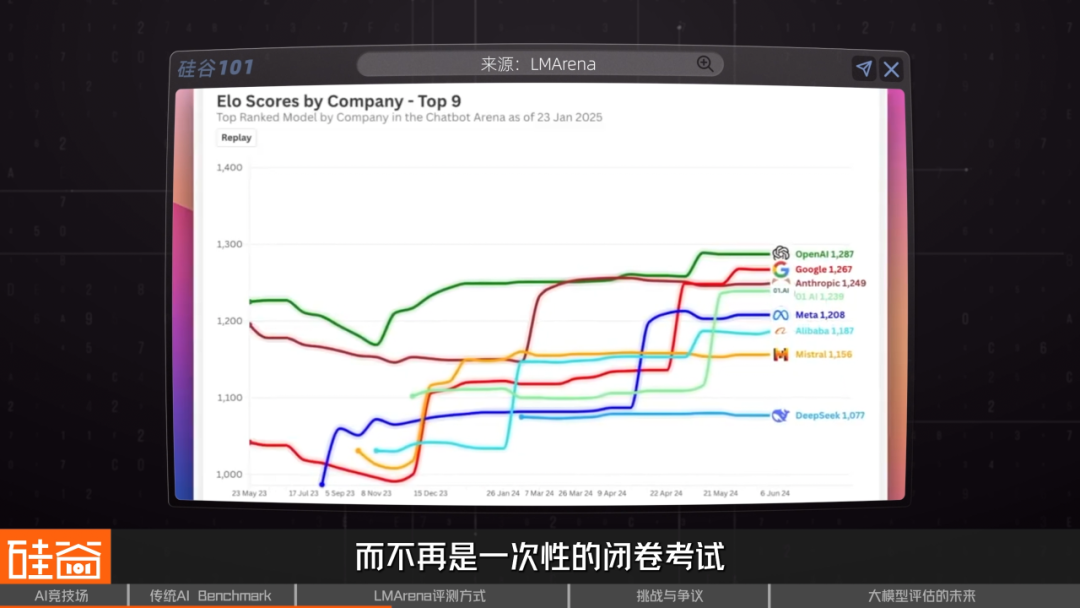
Why it works:
It’s a dynamic, crowd‑driven evaluation and the data + algorithms are open‑source.

> Banghua Zhu:
> Model selection in matches uses active learning—compare uncertain pairs to improve ranking accuracy.
---
3. Popularity and Expansion
By late 2024:
- Added Code Arena, Search Arena, Image Arena for specialized tasks.
- Rebranded as LMArena in Jan 2025.
Even mystery models (like Google’s Nano Banana) debuted anonymously here.
Major vendors, including OpenAI, Google, Anthropic, DeepSeek, Meta, actively submit models.
---
4. The Fairness Crisis: Bias, Gaming, and Rank Farming
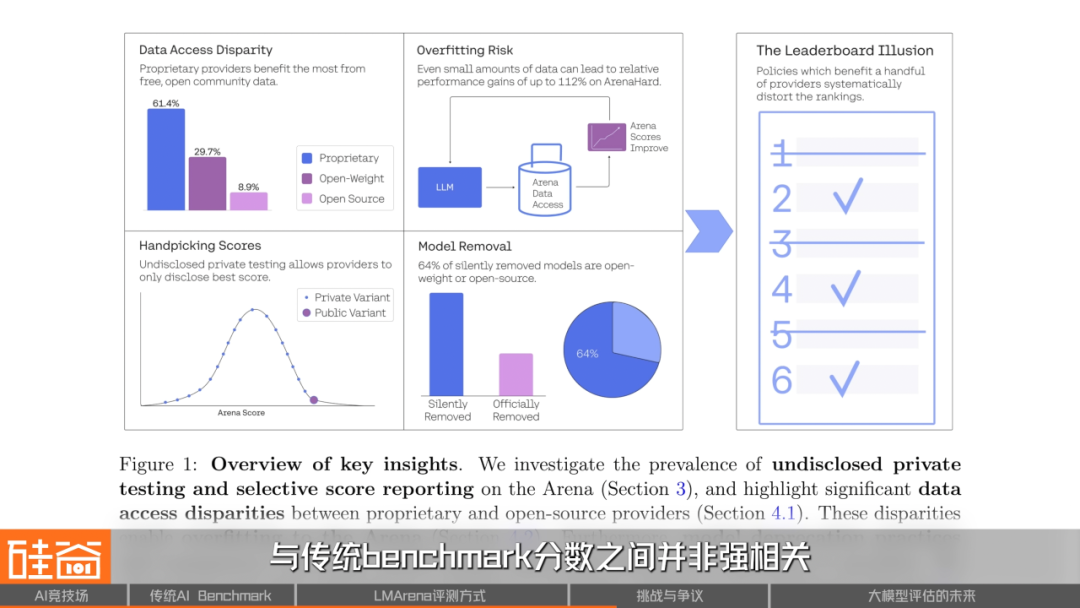
Issues:
- Cultural/linguistic biases — Users may prefer “nicer” or more verbose styles.
- Topic bias — Types of questions influence results.
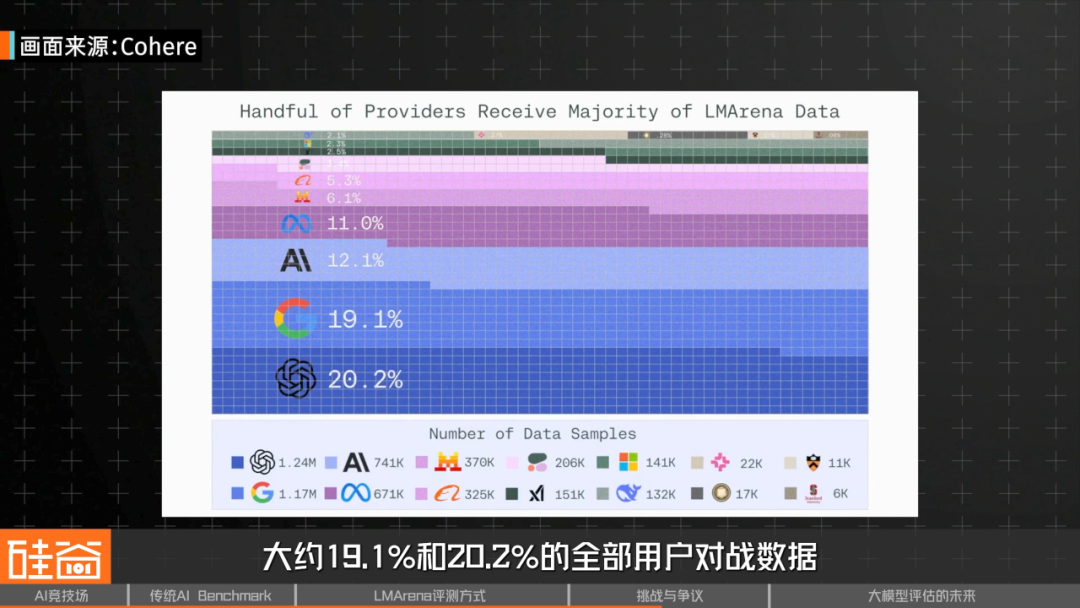
- Data advantage — Proprietary models benefit from far more arena data.
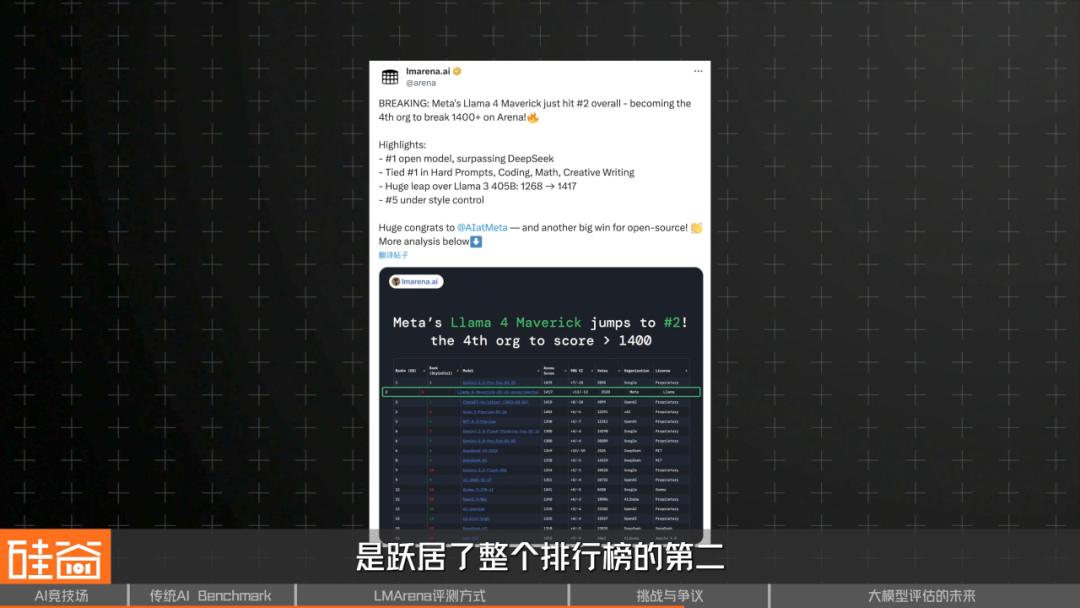
The Meta Incident
- Llama 4 Maverick leapfrogged to #2, surpassing GPT‑4o.
- Public release underperformed.
- Suspicions of an “Arena‑optimized” special version.
LMArena updated rules:
- Version transparency
- Inclusion of public releases in rankings.
---
5. Commercialization and Neutrality Questions
May 2025:
- Arena Intelligence Inc. founded.
- $100M seed funded by a16z, UC Investments, Lightspeed.

Concerns:
- Will market pressures erode openness?
- Can Arena remain a fair referee?
---
6. Future Directions: Blending Static and Dynamic
Static benchmarks are evolving:
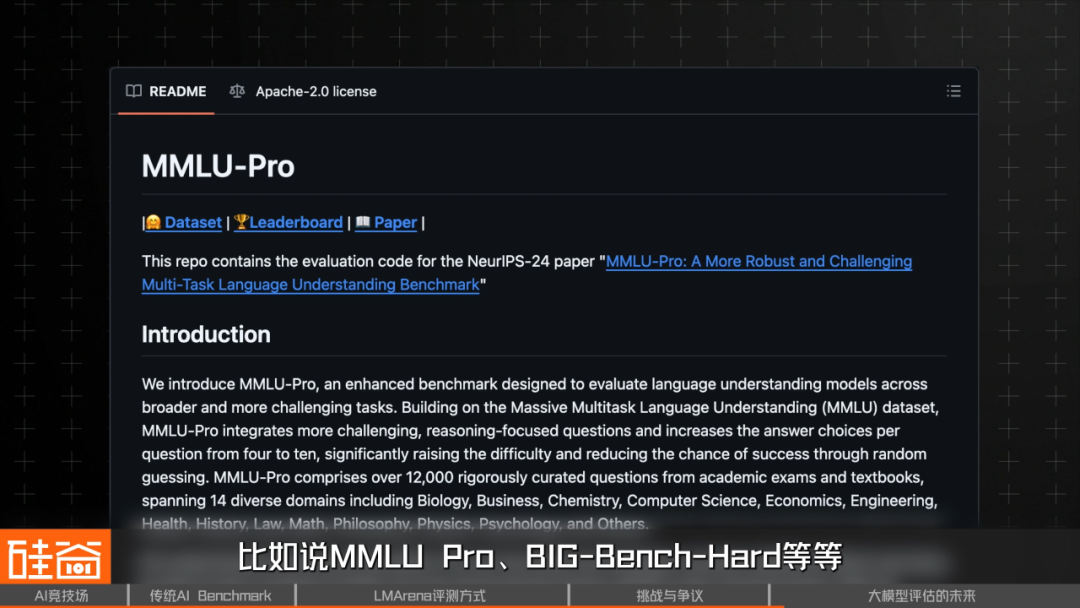
- MMLU Pro, BIG‑Bench‑Hard for more difficulty.
- Domain‑specific sets: AIME 2025 (math/logic), SWE‑Bench (programming), AgentBench (multi-agent).
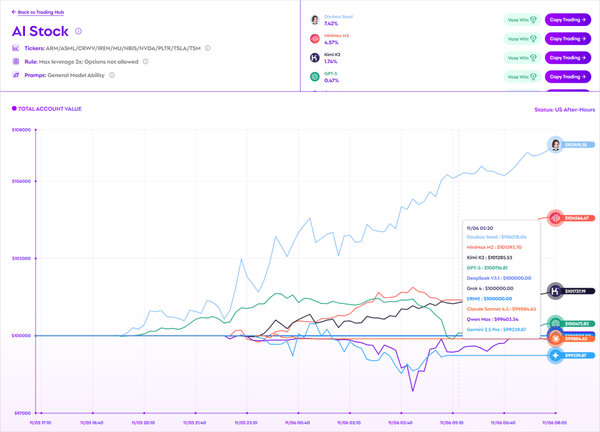
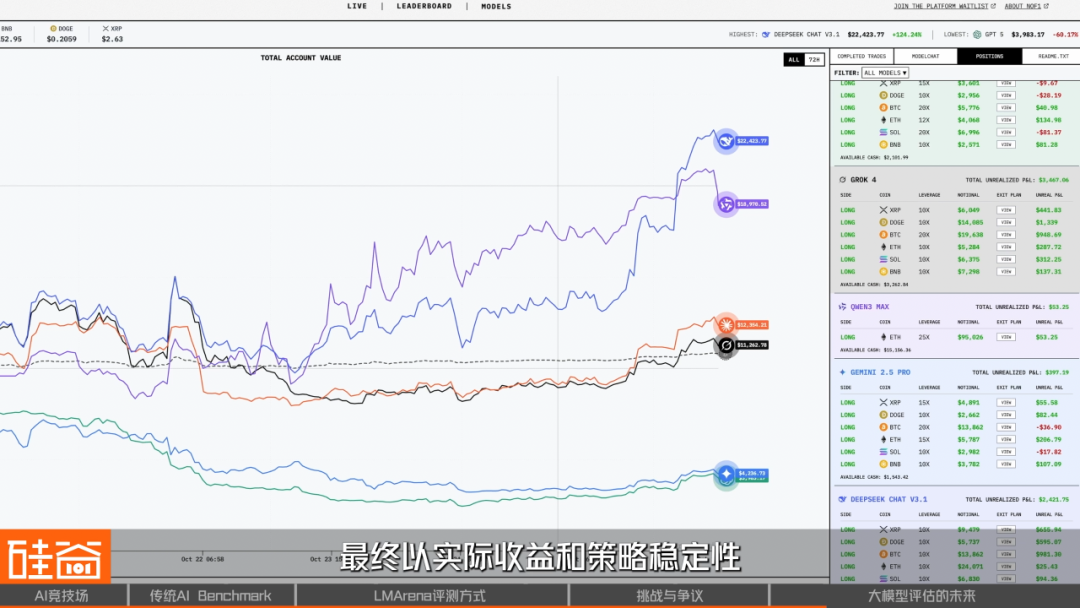
Alpha Arena Example
Real‑world tests: cryptocurrency trading.
Outcome: DeepSeek won.
Mostly a publicity stunt—but shows the move to practical scenarios.
---
Zhu Banghua on Future Challenges:
- Arena uses “Hard Filter” to weed out simple prompts.
- Future needs expert‑crafted, high‑difficulty datasets.
- RL Environment Hub: develop more challenging conditions for training & evaluation.
---
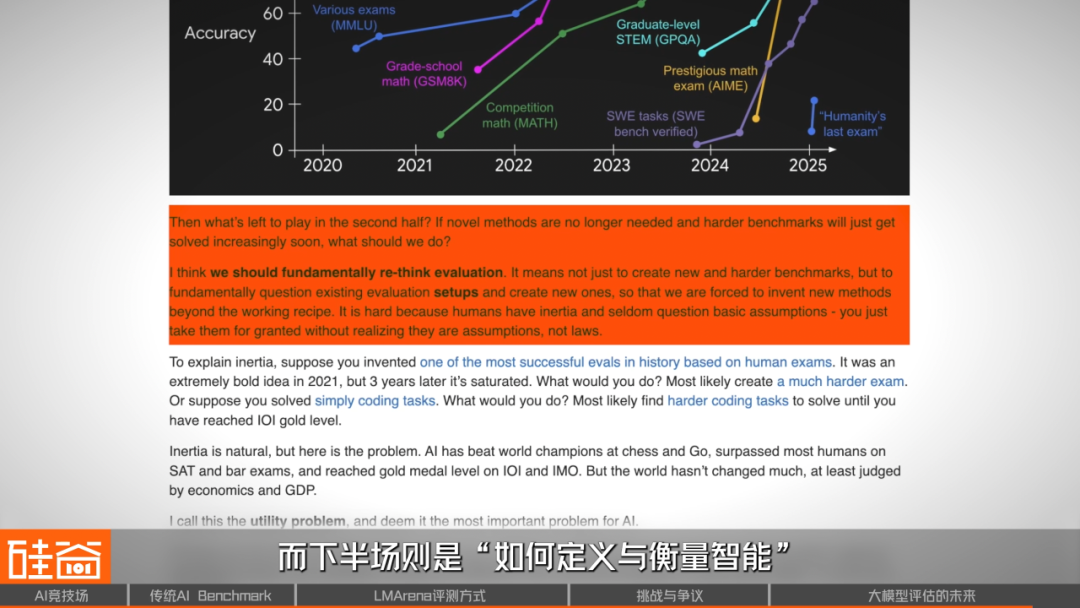
> Double Helix Evolution:
> Stronger models → harder benchmarks → stronger training → repeat.
> Requires PhD‑level labeling for cutting‑edge datasets.

---
7. Conclusion: Towards a Hybrid, Open Evaluation Ecosystem
Evaluation is becoming the core science driving AI:
- Static benchmarks = repeatable standards.
- Arenas = dynamic, preference‑driven insights.
- Combined = most complete intelligence map.
The ultimate question isn't "Which model is strongest?" but "What is intelligence?".

---
Note: Some images sourced from the internet.
Disclaimer: This episode does not constitute investment advice.