World’s Top OCR Model Only 0.9B! Baidu Wenxin Derivative Just Sweeps 4 SOTAs
PaddleOCR-VL: Baidu’s Lightweight Multimodal OCR Model Takes Global #1
Baidu has delivered a major surprise in the global AI multimodal race with the release of PaddleOCR-VL — a lightweight, self-developed document parsing model that has immediately set new industry benchmarks.
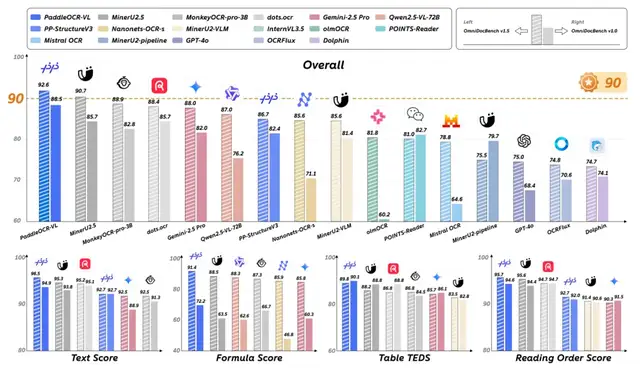
With just 0.9B parameters, PaddleOCR-VL scored 92.6 on the authoritative OmniDocBench V1.5 leaderboard, claiming #1 globally in overall performance while setting SOTA in all four key capabilities:
- Text Recognition
- Formula Recognition
- Table Understanding
- Reading Order
And it’s open source from day one.
Within just 16 hours of release, it shot to the #1 trending position worldwide on Hugging Face.
---
What Makes PaddleOCR-VL Stand Out
Key Achievements:
- First place in all four evaluated dimensions on OmniDocBench V1.5
- Highly efficient — runs comfortably on a personal computer
- Exceptional adaptability — handles complex PDFs and images with messy formatting
- Industry-ready — easy integration into existing workflows
Real-world capabilities:
- Understands logical document structure
- Recognizes mathematical expressions, tables, and multi-column layouts
- Maintains accuracy with distorted, noisy, or partially obscured samples
---
The Four Core Capabilities & SOTA Scores
1. Text Recognition — Score: 96.5
- Supports 109 languages, including Chinese, English, French, Arabic, and more
- Handles handwriting, vertical text, and artistic fonts
- Overcomes traditional OCR limitations of “print-only” recognition
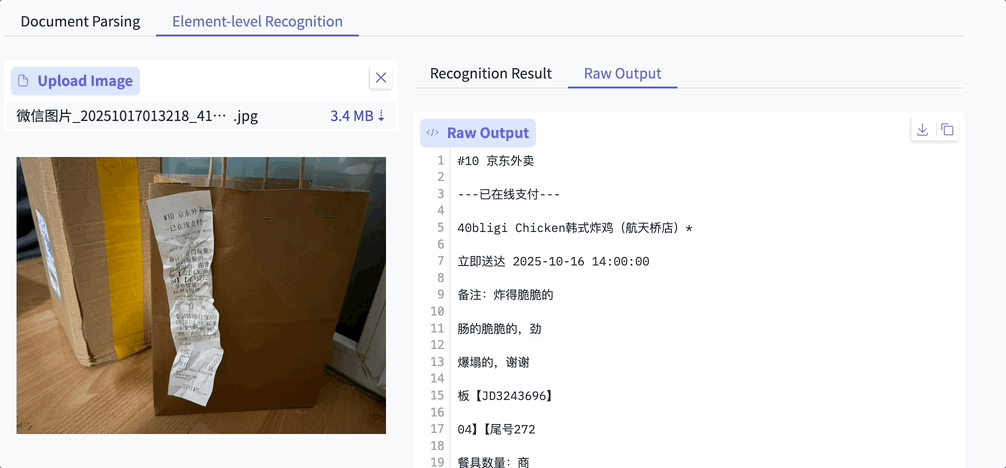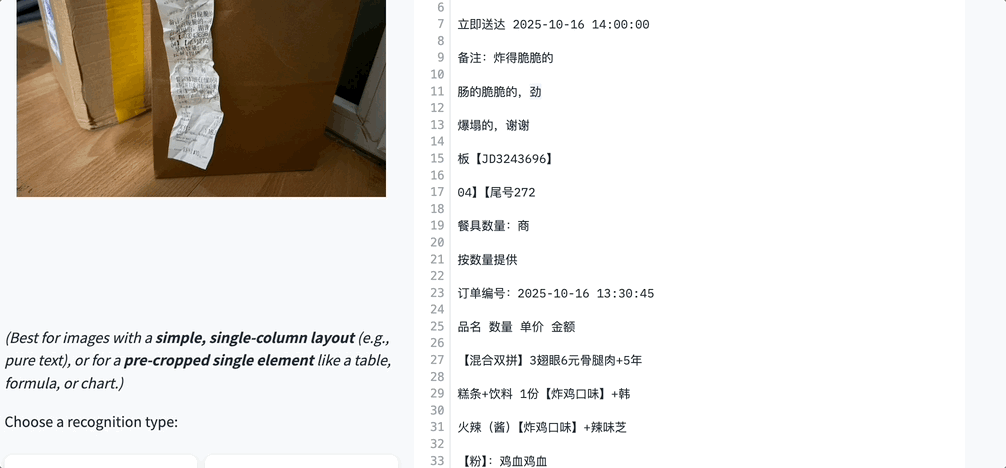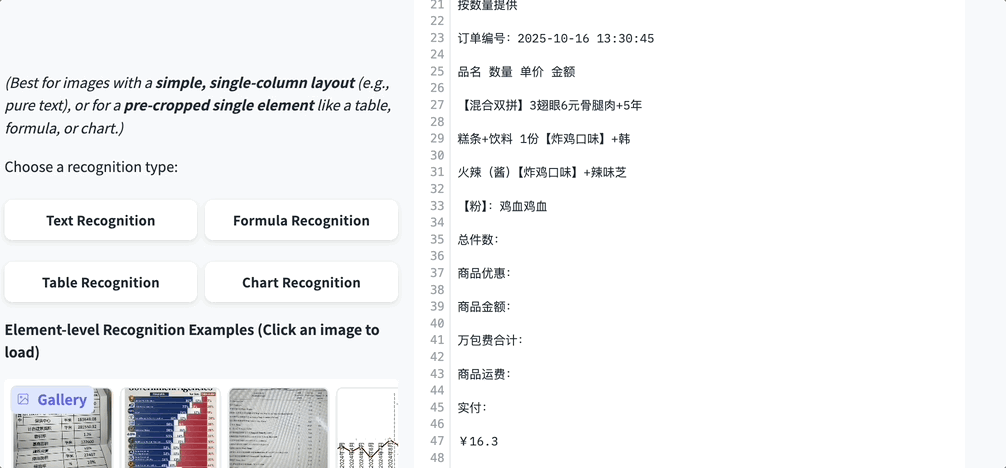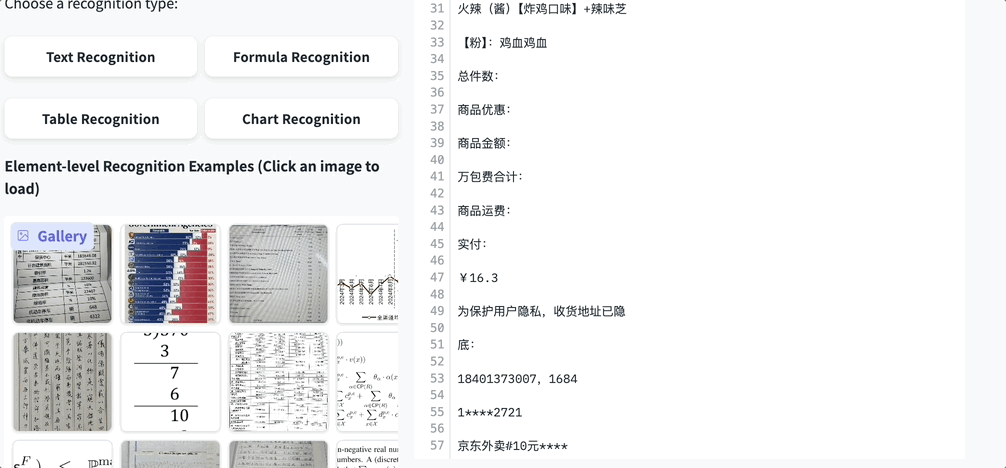
Example: Even a crumpled receipt in poor lighting with folded text is handled perfectly:
---
2. Formula Recognition — Score: 91.4
- Achieved CDM score: 0.9453
- Precise LaTeX generation for complex formulas in papers, textbooks, and tests
- Outperformed community favorites like MinerU and MonkeyOCR-pro-3B
- Only model scoring above 90 in formula recognition capability

---
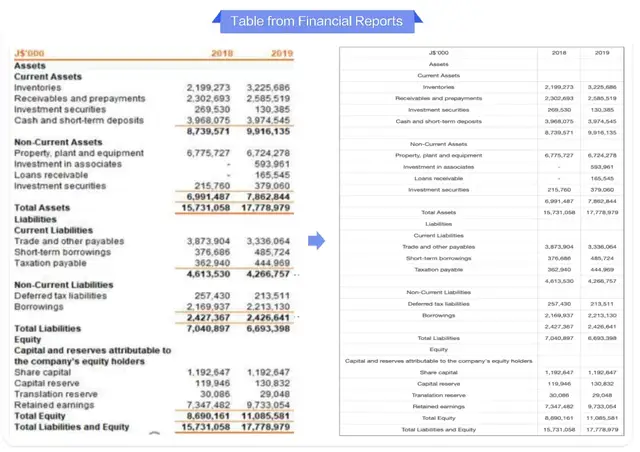
3. Table Understanding — Score: 89.8
- Accurately parses nested tables and merged cells
- Converts unstructured image data into analyzable structured formats
---
4. Reading Order — Error Rate: 0.043 (Lowest)
- Reads like a human by reconstructing logical reading flow
- Predicts order for titles, body text, images, and captions
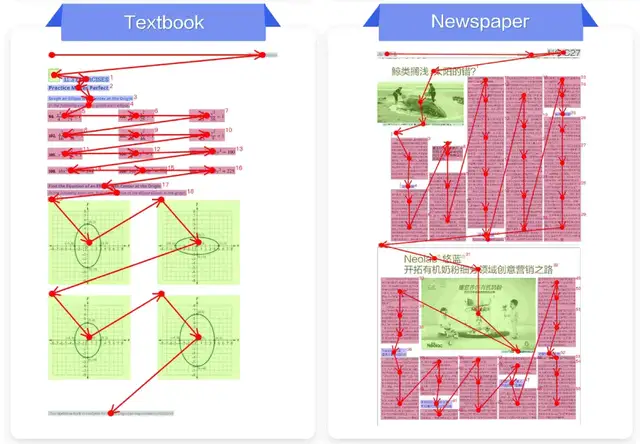
---
More Than Just OCR — Broad Competence
Beyond its four core strengths, PaddleOCR-VL excels in:
- Chart extraction
- Multi-column layout reconstruction
- Multi-page structured analysis
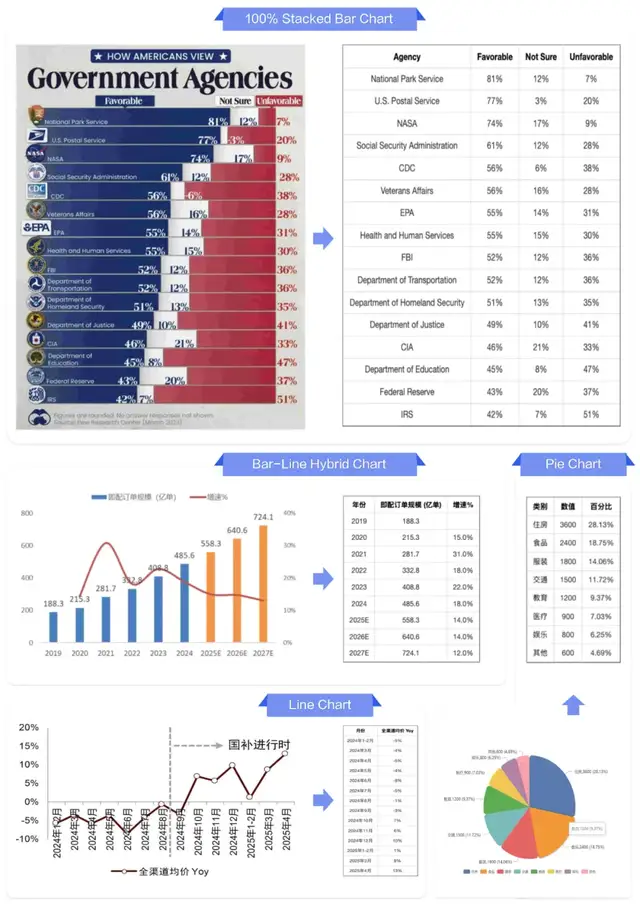
---
Under the Hood — Why It’s So Effective
Architectural Innovation
- Two-stage design:
- PP-DocLayoutV2: Layout analysis, semantic region detection, reading order prediction
- PaddleOCR-VL-0.9B: Fine-grained recognition of text, formulas, tables, charts
- Reduces hallucinations and misalignment common in multimodal models
Training Strategy
- Over 30 million samples covering text, tables, formulas, charts
- Data sourced from public datasets, synthetic generation, web sampling, and proprietary Baidu sets
- Difficult-case mining ensures robustness
Performance Metrics
- 1881 tokens/s on a single A100 GPU
- Text edit distance: 0.035
- Formula CDM: 91.43
- Table TEDS: 89.76
- Reading order error: 0.043
---
Real-World Testing: Wang Xingxing’s MS Thesis
Tested on Unitree Robotics founder Wang Xingxing’s thesis — a challenging mix of:
- Inline and standalone formulas
- Charts and illustrations
- Complex layouts
PaddleOCR-VL handled:
- Page logic reconstruction
- Diagram extraction
- Mixed content pages

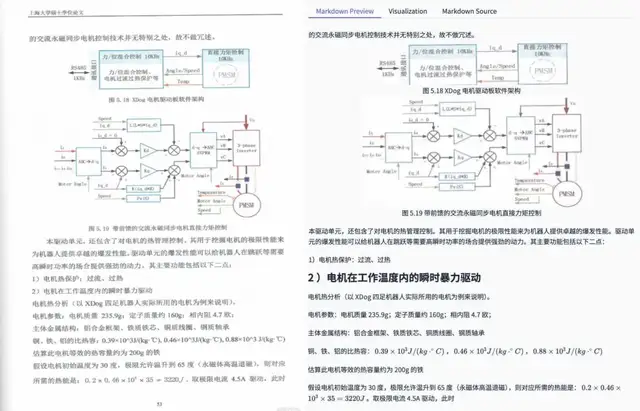

---
Industry Impact
Key insights:
- Breaks the myth: “Big models are always better” — shows small, specialized models can lead in accuracy and efficiency
- Ideal for document-heavy industries: finance, education, government, research
- Integrates well into RAG systems for high-quality, controllable knowledge inputs
OCR has shifted from being a “text recognition tool” to a strategic entry point for AI to understand real-world unstructured data. Precision in OCR directly impacts the reliability of downstream AI tasks in search, Q&A, and analytics.
---
Open Source & Resources
- GitHub: https://github.com/PaddlePaddle/PaddleOCR
- Technical Report: https://arxiv.org/pdf/2510.14528
- Demo: https://aistudio.baidu.com/application/detail/98365
---
PaddleOCR-VL in AI Content Ecosystem
Platforms like AiToEarn enable creators to integrate PaddleOCR-VL into AI-powered workflows:
- Multi-platform content publishing (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X)
- Analytics and monetization
- Open-source toolkits: AiToEarn GitHub
- Model ranking insights: AI模型排名
By combining high-precision OCR parsing with publishing and analytics frameworks, content creators can streamline workflows from document analysis to cross-platform monetization.
---
Bottom Line
PaddleOCR-VL stands out as:
- Lightweight yet powerful
- Industry adaptable
- Global benchmark setter
It is not only advancing the OCR field but also showing how targeted design and smart engineering can challenge — and outperform — much larger multimodal models.



