Xiaomi Integrates Smart Driving with Embodied AI Models and Then Open Sources It
World's First Unified Base Model for Autonomous Driving & Robotics Now Open Source
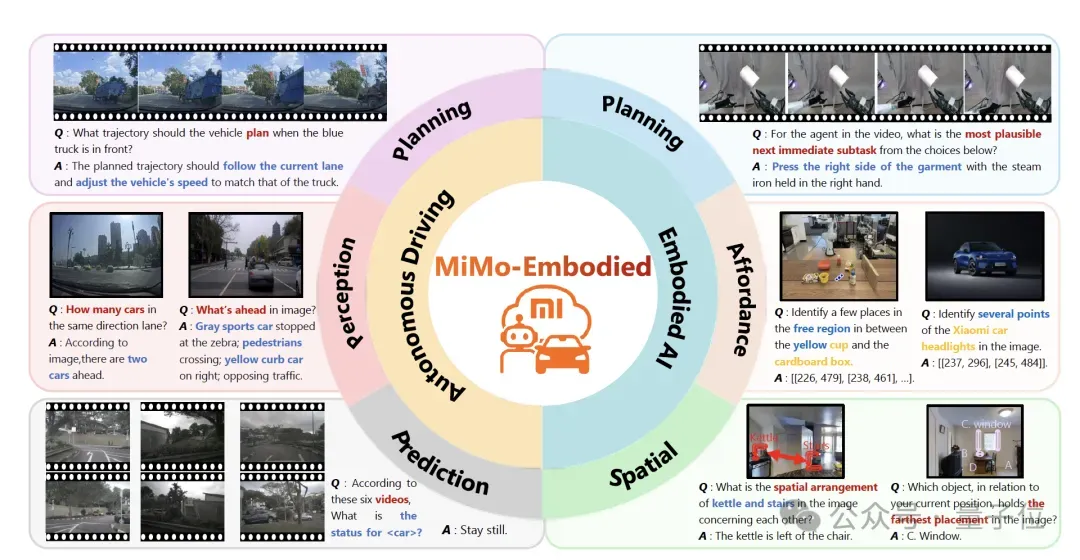
Xiaomi Auto's Chen Long team has introduced and open-sourced the world's first cross-embodied (X–Embodied) base model — MiMo-Embodied — designed to bridge autonomous driving and embodied manipulation domains.
Built on the MiMo-VL architecture, MiMo-Embodied features:
- High-quality, diverse datasets spanning general vision, embodied tasks, and driving scenarios.
- A progressive four-stage training strategy incorporating Chain of Thought (CoT) reasoning and Reinforcement Learning (RL).
- Breakthroughs in cross-domain performance, outperforming specialized and general models across 29 benchmarks in autonomous driving and embodied intelligence.
Goal: From environment perception and driving planning to robotic manipulation and navigation — master it all.
---
Key Challenges in Embodied & Autonomous Driving VLMs
Historically, Vision-Language Models (VLMs) faced three main barriers:
- No Unified Embodied VLM
- Single-domain focus (indoor OR outdoor) limited interaction with dynamic physical environments.
- Domain Gap & Transfer Difficulties
- Large differences between indoor robotic tasks vs. outdoor driving hinder skill transfer.
- No Cross-Domain Evaluation Framework
- Lacking a robust method to measure integrated performance across both domains.
MiMo-Embodied’s mission: Merge autonomous driving and embodied intelligence capabilities into a unified, cross-domain VLM.
---
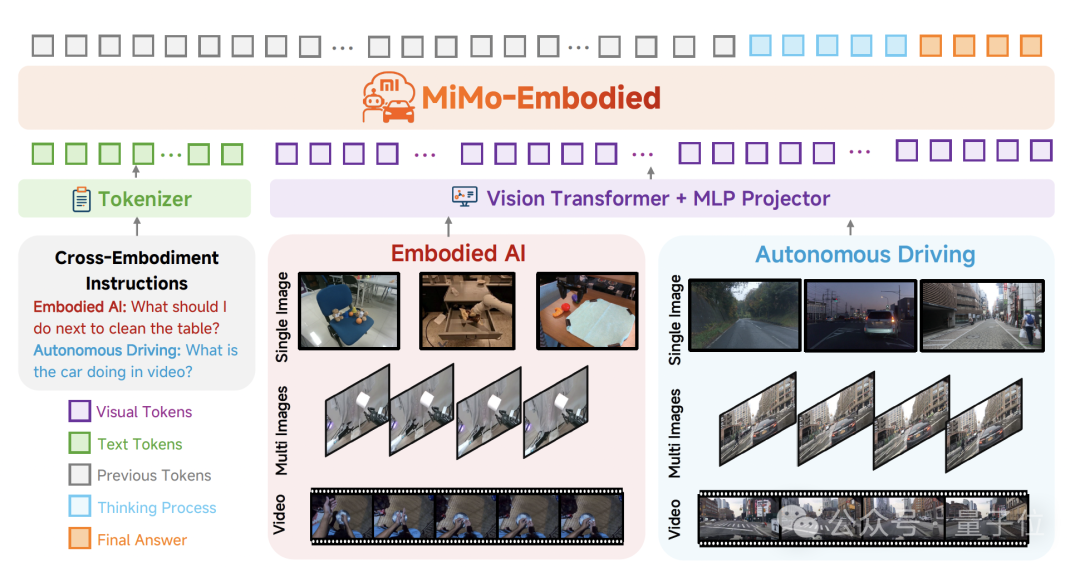
MiMo-Embodied Architecture
The MiMo-Embodied architecture features three core components:
- Vision Transformer (ViT) – Encodes single images, sequences, and videos into rich visual representations.
- Projector (MLP) – Maps visual tokens into a latent space aligned with the LLM.
- Large Language Model (LLM) – Understands text, reasons, and integrates visual cues for context-aware outputs.
By unifying vision and language processing, MiMo-Embodied enables advanced multimodal reasoning applications.
---
Dataset & Progressive Training Strategy
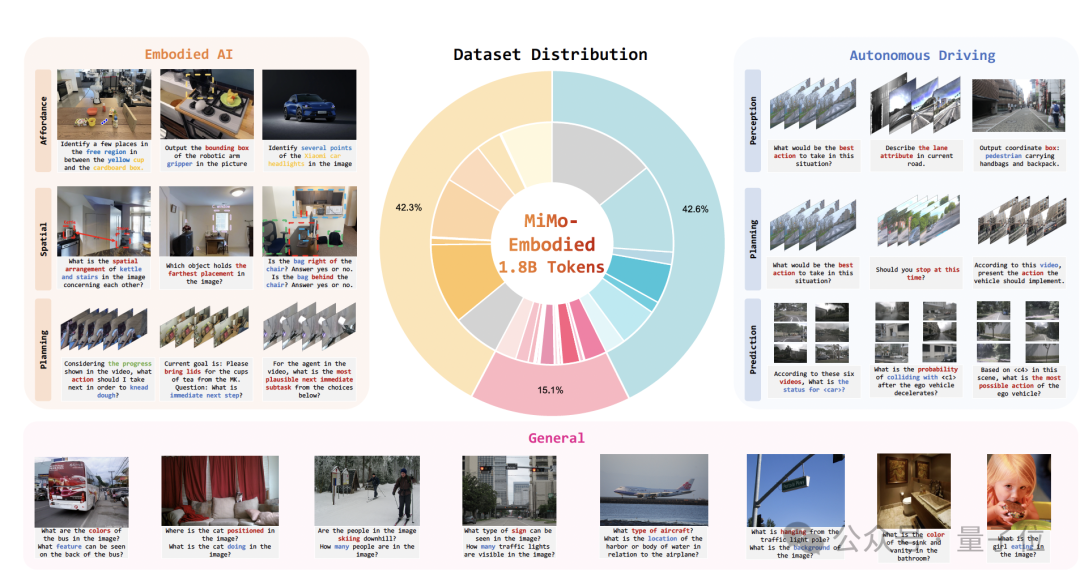
Dataset Coverage
Training data spans:
- General Multimodal Data – From MiMo-VL corpus; includes synthetic reasoning for perception, reasoning, and interaction.
- Embodied Intelligence Data – Affordance prediction, planning, spatial understanding via datasets like PixMo-Points, RoboAfford, RoboRefIt.
- Autonomous Driving Data – Perception, prediction, planning with datasets such as CODA-LM, DriveLM, nuScenes-QA.
Four Training Stages
- Embodied AI Supervised Fine-Tuning
- Combine general-purpose + embodied data to establish core vision-language reasoning.
- Autonomous Driving Supervised Fine-Tuning
- Train spatial reasoning, video consistency, traffic understanding with large-scale driving data.
- CoT Supervised Fine-Tuning
- Explicit multi-step reasoning for tasks like risk assessment and rationale explanation.
- Reinforcement Learning Fine-Tuning
- Utilize GRPO with reward signals for correctness (multiple-choice matching, IoU scores).
---
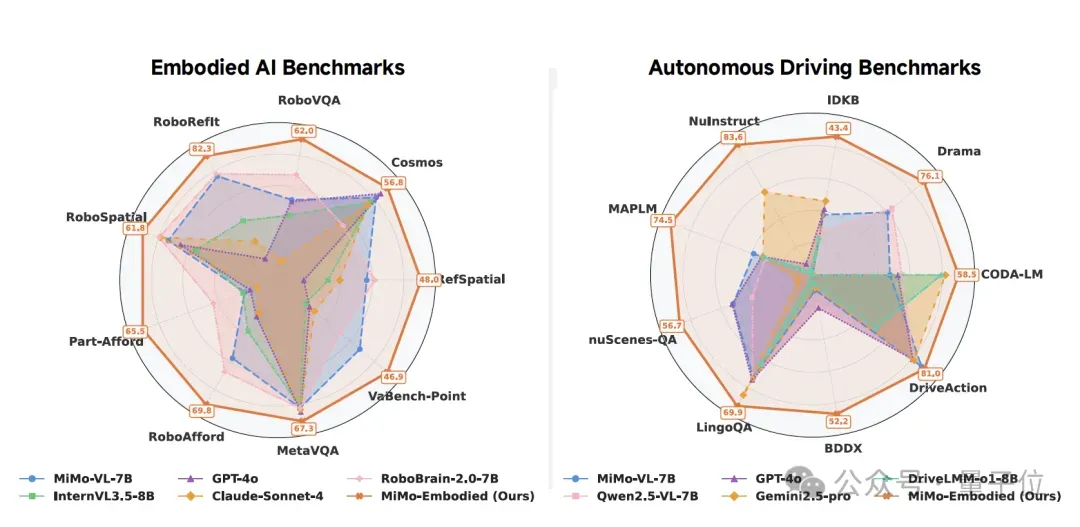
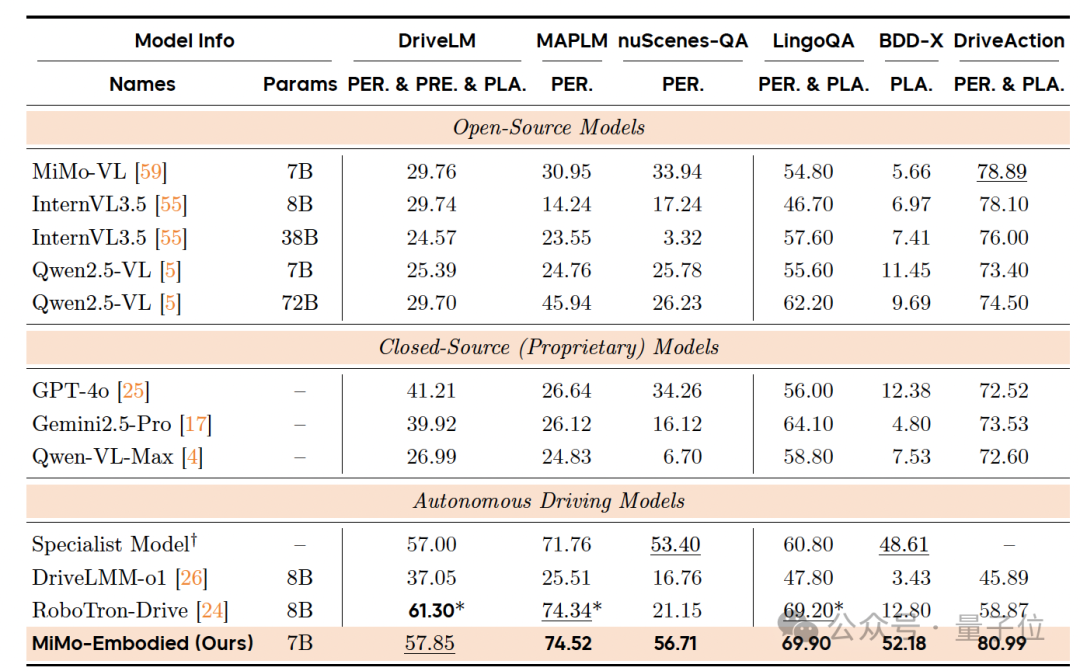
Benchmark Performance
Embodied Intelligence Benchmarks
Tested for affordance prediction, task planning, and spatial understanding.
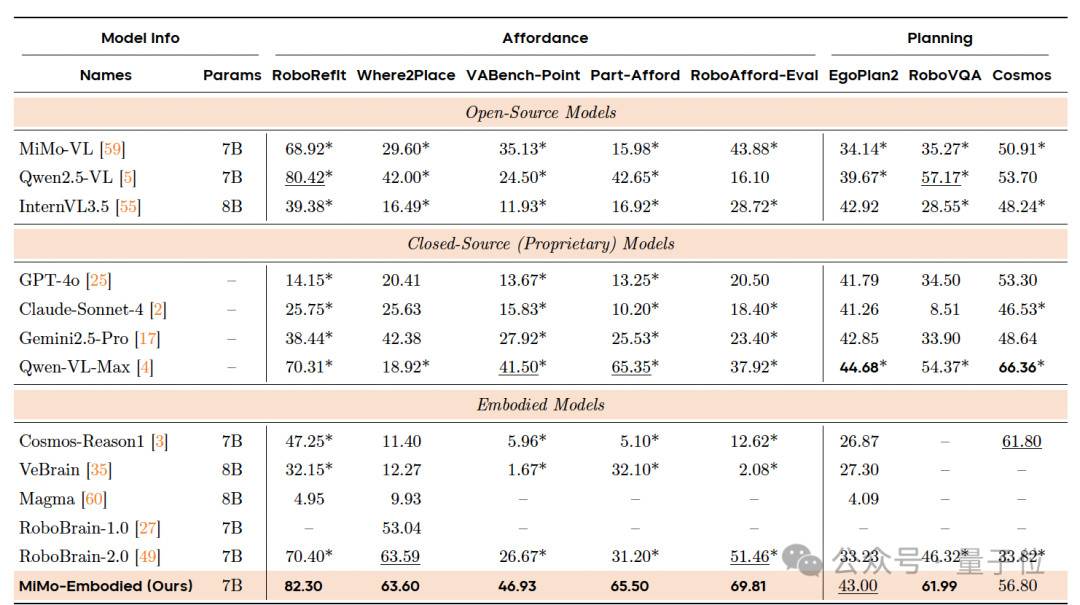
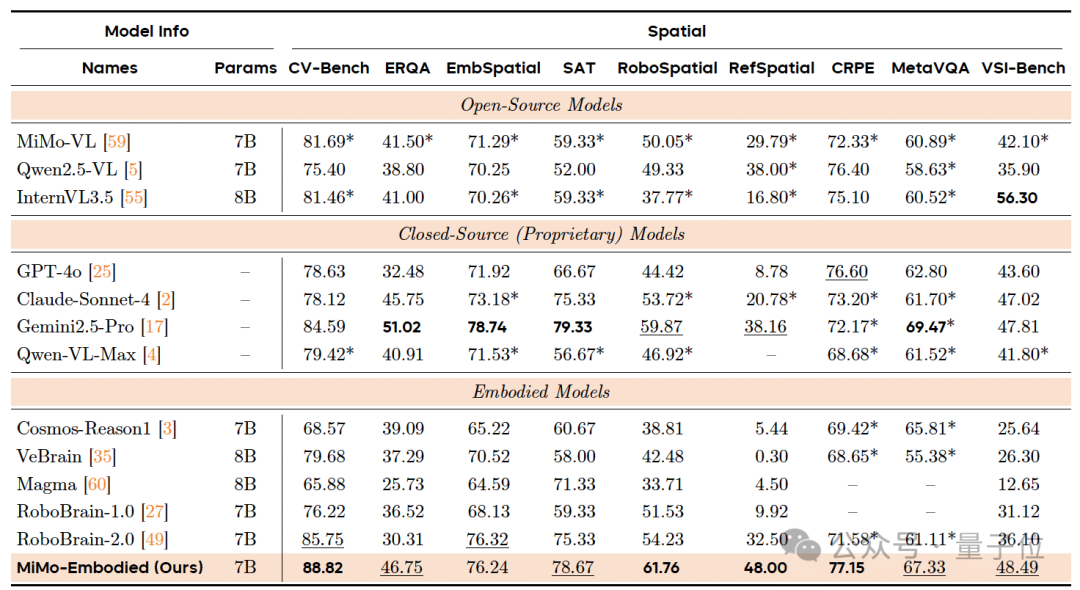
Result: Significant gains over both general-purpose multimodal and specialized embodied models.
---
Autonomous Driving Benchmarks
Measured across perception, prediction, and planning with 12 datasets.
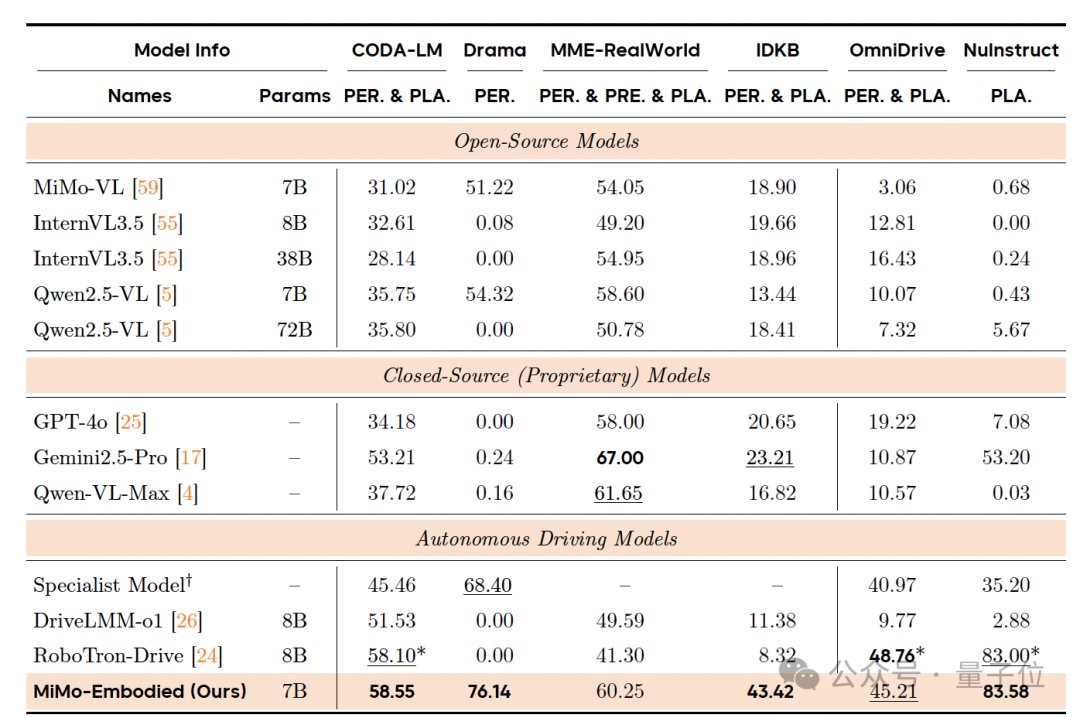
Highlights:
- State-of-the-art panoramic semantic understanding.
- Strong robustness for complex local perception scenarios.
---
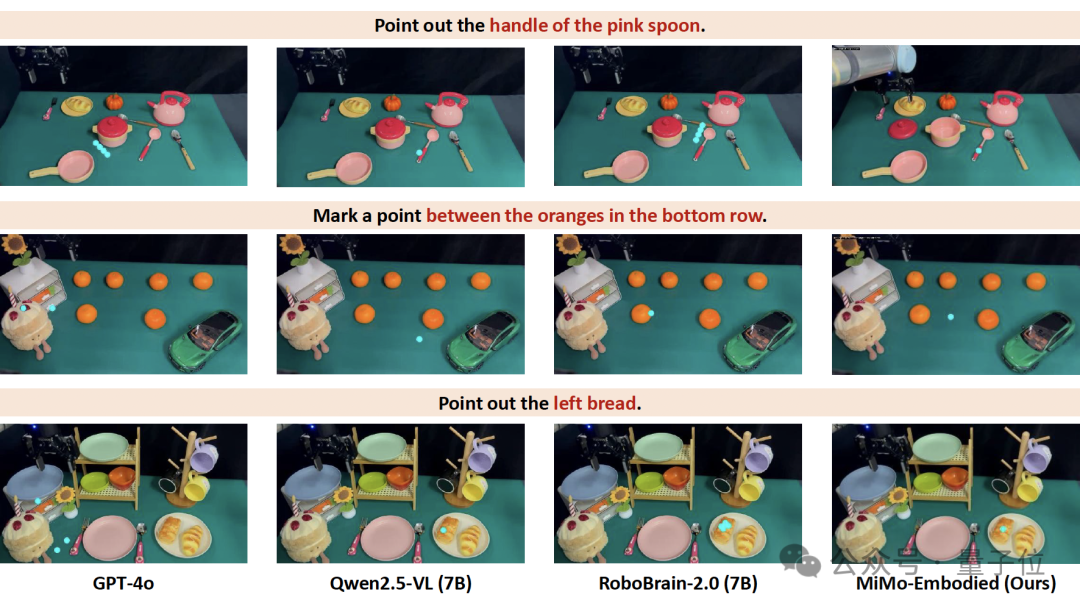
Real-World Qualitative Testing
Embodied Navigation
Compared to GPT-4o, Qwen2.5-VL, RoboBrain-2.0 —
MiMo-Embodied excels at object localization and environment consistency.

Manipulation Tasks
Demonstrates advanced affordance and spatial reasoning.
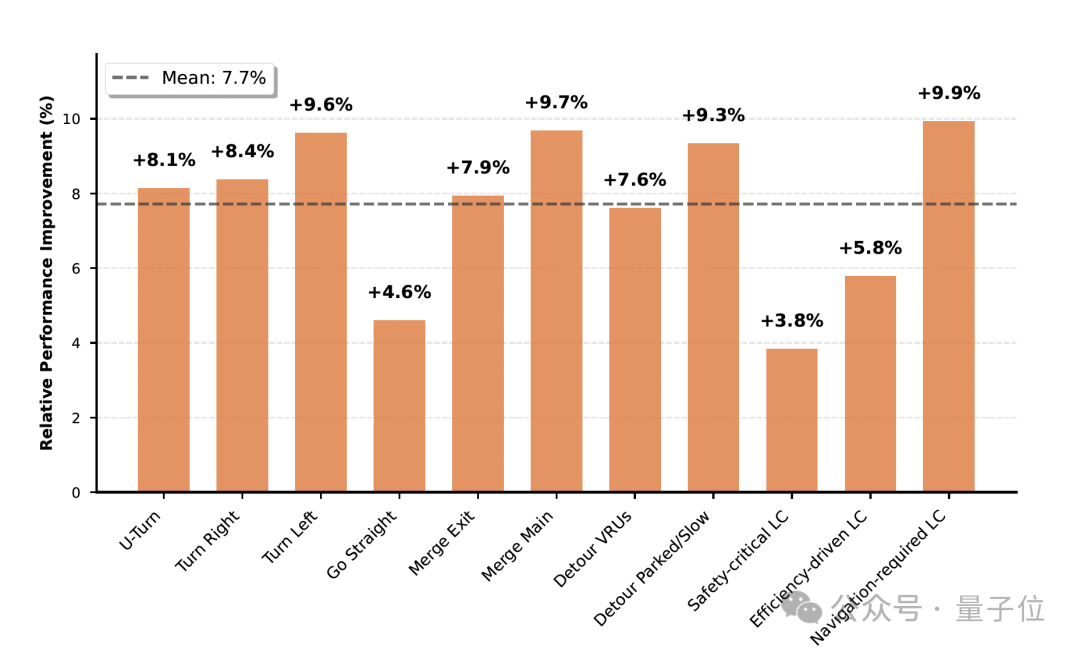
Autonomous Driving Scenarios
Successfully executes complex maneuvers: intersection turns, U-turns, following, lane changes.

Major improvement seen in interactive operations like turning, obstacle avoidance, lane change.
---
AI Content Monetization Connection
Open-source platforms like AiToEarn官网 support creators in:
- AI-powered content generation.
- Simultaneous publishing to Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X.
- Access to cross-platform analytics & AI model rankings (AI模型排名).
Tools like AiToEarn help bring innovations such as MiMo-Embodied to wider audiences and monetizable formats.
---
Research Team
- Dr. Xiaoshuai Hao – First Author
- Joined Xiaomi Auto (Aug 2024), previously at BAAI, Samsung, Amazon.

- Dr. Long Chen – Project Lead & Chief Scientist, Xiaomi Intelligent Driving
- Formerly at Wayve (UK), Lyft.

---
Resources
- Paper: https://arxiv.org/abs/2511.16518
- GitHub: https://github.com/XiaomiMiMo/MiMo-Embodied
- Hugging Face: https://huggingface.co/XiaomiMiMo/MiMo-Embodied-7B
---
Future Work:
The team plans to enhance Vision-Language-Action (VLA) modeling for richer interaction in complex environments, leveraging MiMo-Embodied’s unified architecture.
---
Would you like me to also produce an at-a-glance one-page summary table of MiMo-Embodied’s datasets, architecture, and benchmarks for quick reference? That would make the tech stack and performance easier to digest.


