Xie Saining Praises ByteDance Seed’s New Research: Single Transformer Achieves Arbitrary View 3D Reconstruction

Single Transformer for Any-View 3D Reconstruction
Overview
ByteDance’s Seed team, led by Kang Bingyi, has introduced Depth Anything 3 (DA3) — a minimalist yet powerful approach to 3D reconstruction. The model has received high praise from industry names such as Xie Saining.

DA3 can:
- Generate accurate depth from a single image, multi-view photos, or videos.
- Reconstruct camera positions.
- Stitch full 3D scenes.
- Create “novel views” — perspectives never captured in the source data.

---
Benchmark Performance
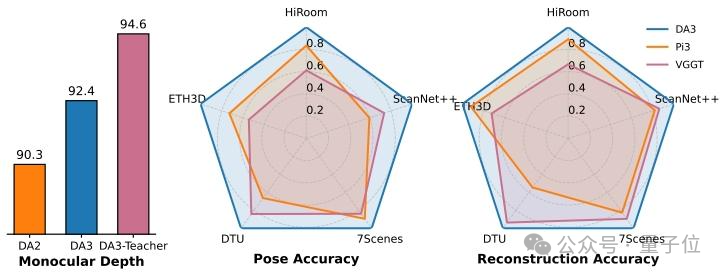
DA3 dominates the team’s visual geometry benchmark:
- 📈 35.7% average improvement in camera localization accuracy.
- 📈 23.6% gain in geometric reconstruction accuracy.
- 📈 Monocular depth estimation surpasses DA2.

---
Problem with Previous Models
Traditional 3D vision pipelines require:
- Separate models for single-image depth estimation and multi-view reconstruction.
- Additional modules just for camera pose estimation.
Drawbacks:
- High development cost.
- Poor leverage of large-scale pretraining.
- Heavy reliance on labeled datasets.
- Models highly specialized and narrow in scope.

---
DA3’s Core Innovation
DA3’s breakthrough rests on two key principles:
- Use a standard visual Transformer as the foundation.
- Predict only two targets — Depth and Illumination.
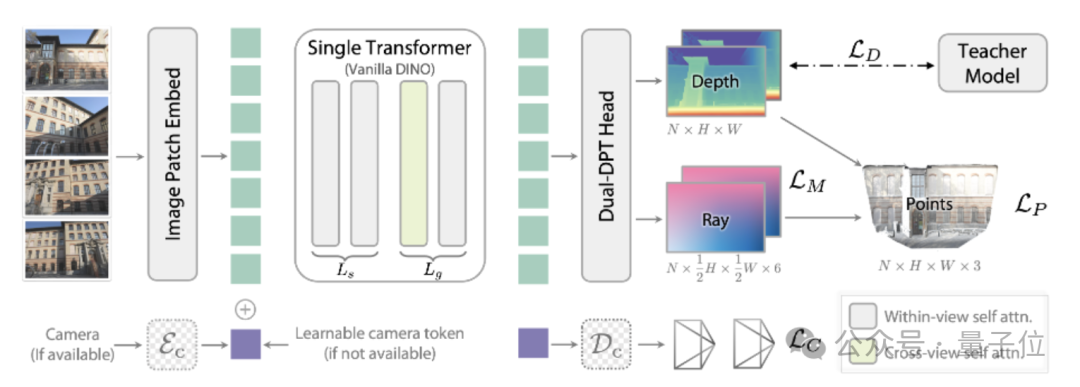
---
Architecture Workflow
DA3 executes its reconstruction pipeline in four major stages:
- Input Processing
- Multi-view images pass through Image Patch Embed to create feature blocks.
- Camera parameters:
- Use encoded parameters if available.
- Use learnable camera tokens if not.
- Concatenate and fuse image features and camera feature vectors.
- Single Transformer (Vanilla DINO)
- The core "brain" is a pre-trained DINO Visual Transformer.
- Within-view and cross-view self-attention connect spatial and temporal information, handling images or videos seamlessly.
- Dual DPRT Head Outputs
- One head → Depth map prediction.
- Other head → Lighting parameters prediction.
- Camera Pose Extraction
- Trajectory estimation for accurate camera motion reconstruction.

---
Training Strategy
- Uses Teacher-Student Distillation:
- Teacher generates high-quality pseudo-labels from large-scale data.
- Student (DA3) learns from them, reducing dependence on costly annotations.
- Covers diverse scenarios by integrating multiple datasets.
---
New Visual Geometry Benchmark
The team designed a benchmark covering five datasets — from indoor scenes to object-level and outdoor environments.
Evaluations include:
- Camera localization
- 3D reconstruction
- Novel-view synthesis
---
Evaluation Highlights
- Video-based camera estimation:
- DA3 determines intrinsic/extrinsic parameters per frame, reconstructing full trajectories.
- Dense, accurate 3D point clouds:
- Combining predicted depth + camera poses yields cleaner reconstructions than traditional methods.

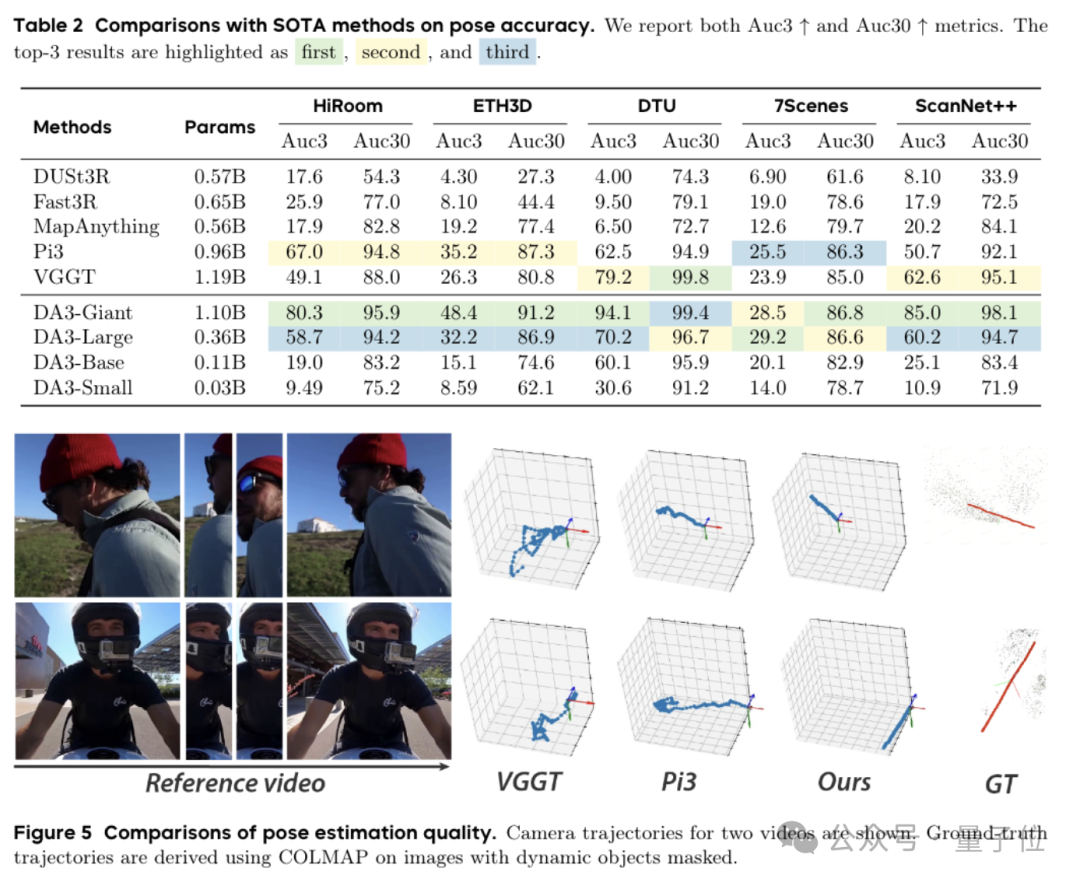
- View completion:
- DA3 fills in missing angles and synthesizes new perspectives — ideal for virtual tours, digital twins, and similar use cases.
---
Project Lead — Kang Bingyi
- Born: 1995.
- Research focus: Computer vision, multimodal models, interactive agents.
- Education:
- Undergraduate: Zhejiang University (2016)
- Master's & Ph.D.: UC Berkeley and National University of Singapore (supervised by Feng Jia).
- Experience: Internship at Facebook AI Research with Saining Xie, Marcus, etc.
- Developer of the Depth Anything series, previously integrated into Apple’s CoreML.
Paper: arXiv:2511.10647
References:
---
AiToEarn — Monetizing AI-Generated Content
As DA3 makes 3D reconstruction more accessible, creators seek platforms to distribute and monetize AI work globally. One open-source solution is AiToEarn, which offers:
- Cross-platform publishing: Douyin, Kwai, WeChat, Bilibili, Xiaohongshu (Rednote), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
- Integrated tools: AI content creation, publishing, analytics.
- Model ranking system: AI模型排名.
Explore more:

---
> Note: For AI researchers and creators, AiToEarn enables simultaneous distribution to major social & media platforms, while tracking model performance and audience analytics efficiently.
---
— End —


