Yang Zhilin and the Kimi Team Respond Late at Night: All Controversies After K2 Thinking Went Viral

2025-11-11 — Beijing Update

Last week, Moonshot AI released and open-sourced the enhanced version of Kimi K2 —

Kimi K2 Thinking, positioned as a “model as Agent”, immediately generated strong buzz in the AI community.
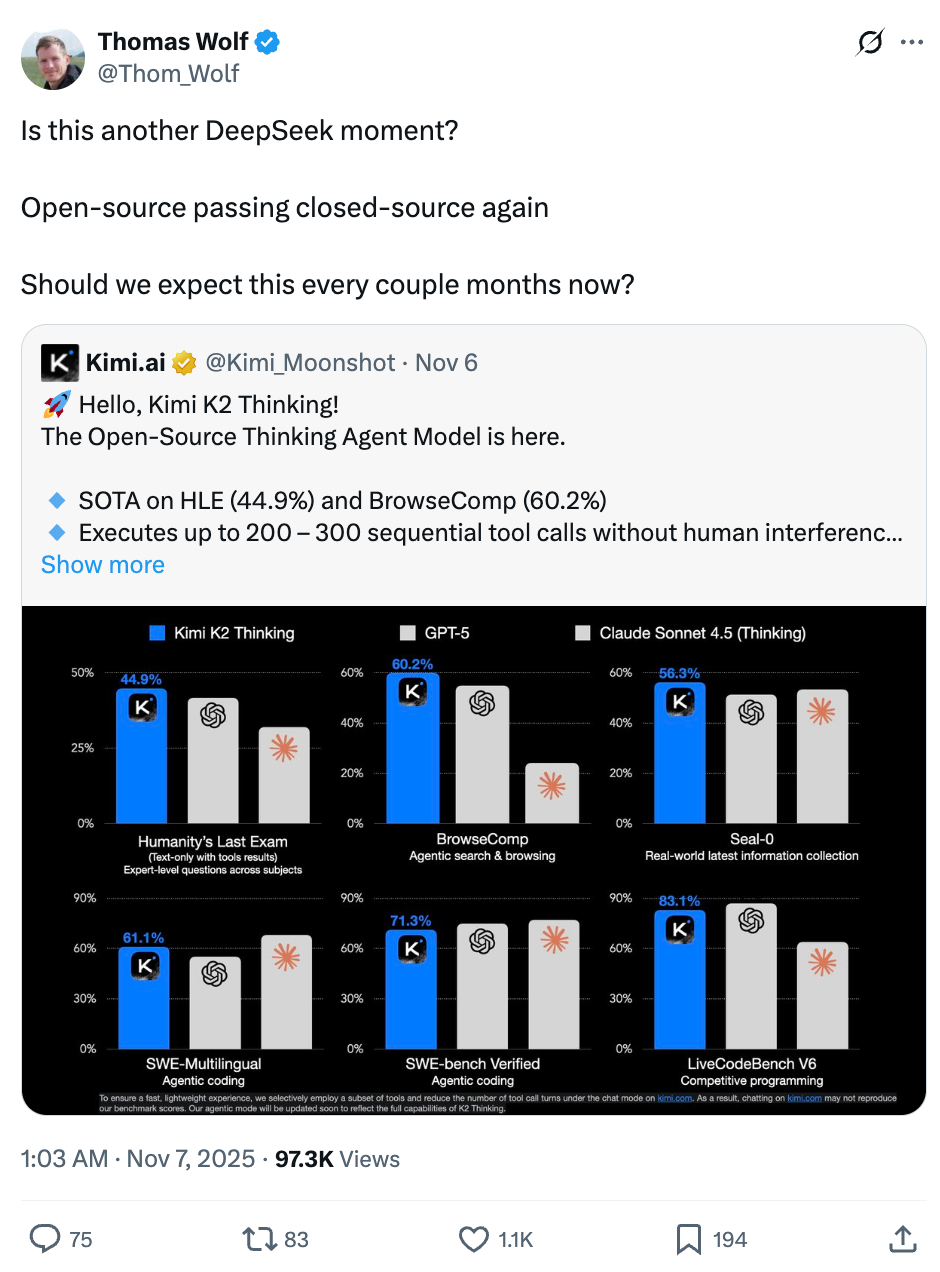
Hugging Face co-founder Thomas Wolf wondered aloud:
> "Is this another DeepSeek moment?"
---
First AMA: Founders Respond
Early this morning, Zhilin Yang, Xinyu Zhou, and Yuxin Wu held a content-heavy AMA on Reddit, tackling direct and sometimes sharp questions from the community.

From left to right: Zhilin Yang, Xinyu Zhou, Yuxin Wu
Key Takeaways
- KDA Attention Mechanism will continue into Kimi K3.
- The “$4.6M training cost” is unofficial; actual cost is hard to quantify.
- A Vision-Language Model (VL) is already under development.
- Progress has been made in reducing output slop, but it’s a persistent challenge for LLMs.
---
Performance Recap: K2 Thinking’s Benchmarks
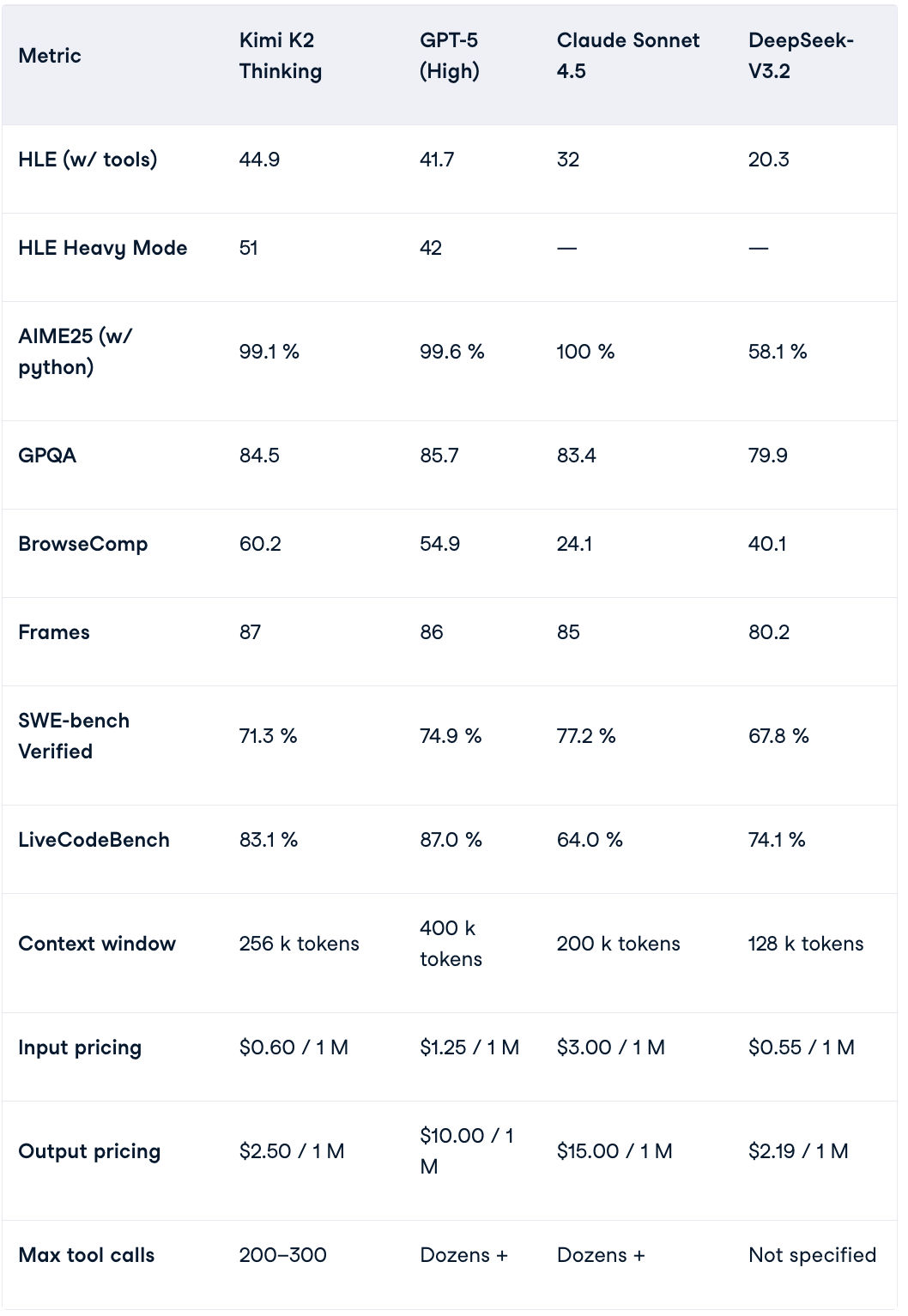
K2 Thinking scored exceptionally well in global benchmarks:
- HLE: Humanity’s Last Exam — extremely challenging AI benchmark.
- BrowseComp: Tests online reasoning with information retrieval and comprehension.
- AIME25: Mathematics reasoning — matches GPT-5 and Claude 4.5, far ahead of DeepSeek V3.2.
Source: datacamp
---
Inside the KDA Mechanism
Within Kimi K2, the KDA (Kimi Delta Attention) replaces traditional full-attention with incremental updates + gating.
Benefits:
- Fixes MoE problems like poor long-context consistency.
- Cuts KV cache and memory requirements.
- Acts like a high-performance attention engine in Transformers.
Zhilin Yang:
> “Related ideas will very likely be applied in K3.”
Xinyu Zhou:
> “We are exploring further improvements to KDA.”
---
K3 Timeline
Yang joked about K3’s release schedule:
> “Before Sam Altman’s trillion-dollar data center is completed.”
(That project would take at least 8 years—if it happens at all.)
---
Speed vs Accuracy
Some testers found K2 Thinking’s reasoning was smarter than GPT‑5 but much slower.
Yang explained:
- K2 Thinking’s long-chain reasoning is deliberate.
- Token efficiency improvements are in progress.
Trade-off: Prioritize depth of thought now, improve speed over time.
---
Creative Writing & "Slop" Problem
User feedback praised K2’s natural tone but noted:
- Occasional verbosity, repetition, uneven rhythm.
- Emotional sanitization reduces “human tension.”
Yang:
> “We have made progress in reducing slop. It's a long-standing LLM challenge.”
> “Reducing censorship and artificial positivity is possible; we will explore further.”
---
K2 Thinking: Moonshot AI’s Turnaround
During industry anticipation for DeepSeek R2, Moonshot AI launched the strongest open-source reasoning model to date.
Distinguishing Factors
- Agent-first design.
- Upgrades in reasoning, search, coding, and writing.
- Native INT4, ultra-sparse MoE, Test-Time Scaling.
- 200–300 autonomous tool calls without human intervention.
---
Test-Time Scaling Strategy
- More thinking tokens → deeper long-form reasoning.
- More tool invocation rounds → greater practical task coverage.
Results:
- Qualitative leap in reasoning depth.
- Coherent multi-step problem solving maintained over hundreds of reasoning iterations.
- Top scores in HLE, BrowseComp, and SWE-Bench.
---
Coding Capability: Agent-Level Development
Benchmarks:
- SWE-Multilingual: 61.1%
- SWE-Bench Verified: 71.3%
- Terminal-Bench: 47.1%
K2 Thinking moves beyond code completion to full end-to-end engineering tasks:
- Understand requirements.
- Debug and verify code.
- Autonomously call tools and configure environments.
---
Intelligent Search & Browsing
K2 Thinking cycles through:
Thinking → Searching → Reading → Rethinking.
Benefits:
- Handles ill-defined problems effectively.
- Converges on accurate answers via iterative retrieval and reasoning.
---
Writing & General Capabilities
- Creative writing: Structures complex ideas with natural pacing.
- Academic assistance: Maintains logical rigor in research tasks.
- Conversation: Balances factual insight with emotional nuance.
---
Engineering Innovations
Key decisions:
- INT4 Quantization (instead of FP8) for extreme compression.
- Quantization-Aware Training (QAT) ensures stability in low-bit environments.
- Weight quantization applied only to MoE components for a speed/performance trade-off.
Result
- ~2× inference speed.
- Lower memory usage.
- No accuracy loss — all benchmarks run at native INT4 precision.
---
KDA: Kimi Delta Attention
Solves quadratic complexity in long-context tasks:
- Incremental computation updates only changed parts.
- KV cache reduction of ~75%.
- Gating ensures semantic continuity across MoE experts.
MoE makes it bigger, KDA makes it steadier.
---
AMA & References
Portal: Reddit AMA
Reference Links:
---
2025 Technology Annual Review — Vote Now!

Vote for three areas you most want reviewed. Share suggestions and trends you’re curious about in the comments!
---
AICon 2025 — Dec 19–20 Beijing
Topics: AI Agents, Context Engineering, AI Product Innovation, and more.
Special Offer: 10% discount for the final AI event of 2025.

---
Recommended Reads
- Altman’s compute order controversy, White House rejection
- Unitree CEO’s viral thesis response; tech industry exec shifts
- Robotics industry competitive heat-up
- Google reportedly supplying AI for Apple’s Siri
- Data centers in space: Google and NVIDIA
- Claude IDE service cuts spark backlash

---
---
> Tip for Creators: Tools like AiToEarn官网 offer open-source AI content generation, multi-platform publishing, and monetization — enabling creators to leverage models like K2 Thinking across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).
---
Would you like me to simplify this further into a 1-page briefing format so it’s easier to share internally? That could make it more actionable for your team.


