Yang Zhilin and the Kimi Team Respond Late at Night: Everything After K2 Thinking Went Viral

2025-11-12 13:45 Zhejiang

---
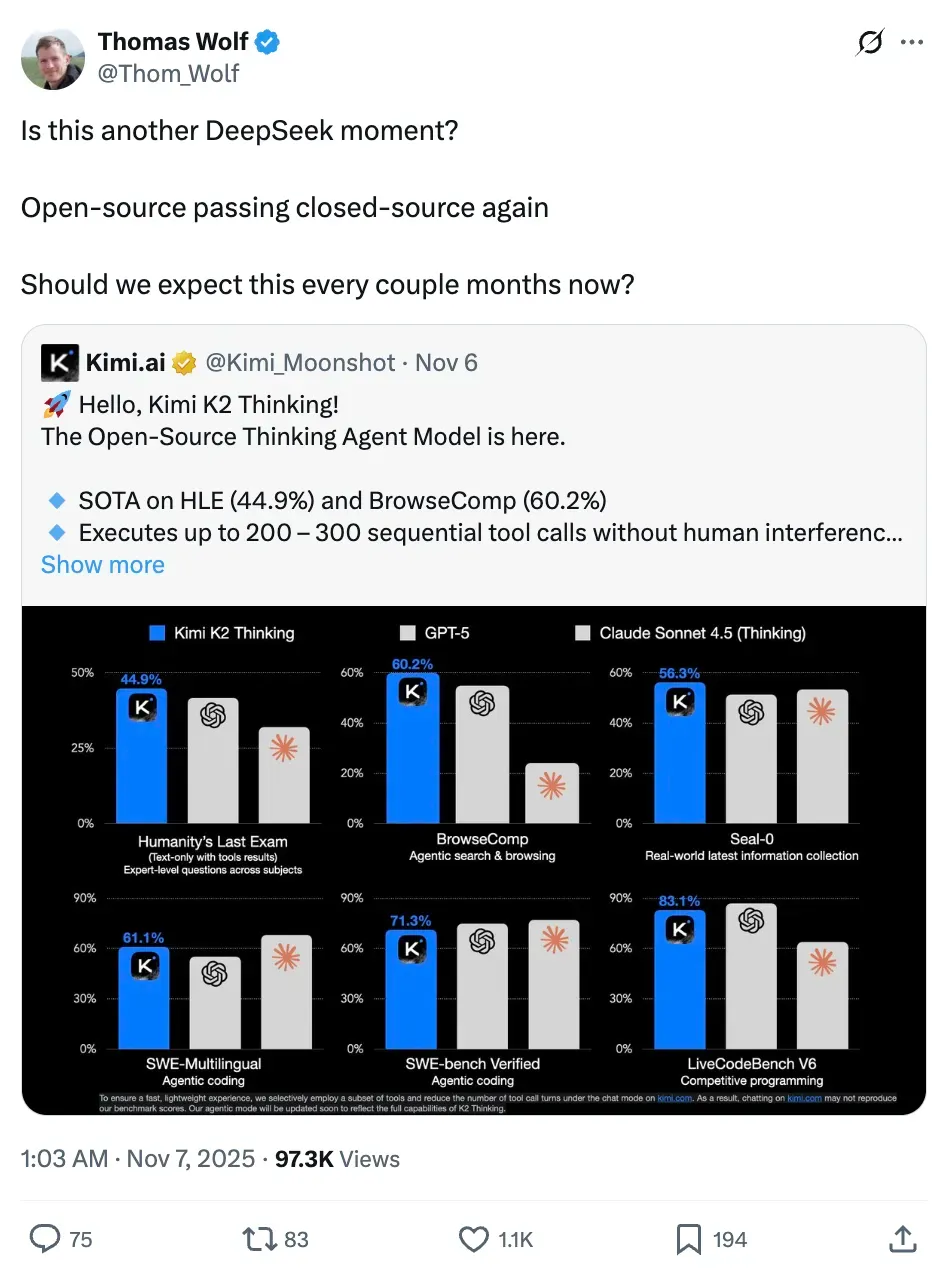
Moonshot AI’s Big Reveal: Kimi K2 Thinking
Last week, Moonshot AI surprised the AI community by open-sourcing an enhanced version of Kimi K2 — dubbed Kimi K2 Thinking — under the slogan “Model as Agent”.
This move sparked immediate excitement and global discussion.

Hugging Face co-founder Thomas Wolf remarked:
> “Is this another DeepSeek moment?”
---
Insights from Moonshot AI’s AMA
Earlier today, Zhilin Yang and fellow co-founders Xinyu Zhou and Yuxin Wu addressed public questions about K2 Thinking in a Reddit AMA.

From left to right: Zhilin Yang, Xinyu Zhou, Yuxin Wu.
Key takeaways:
- KDA attention mechanism (Kimi Delta Attention) will continue in Kimi K3.
- Rumored $4.6M training cost is not official; actual cost is hard to quantify.
- A Vision-Language Model is in development.
- Progress made in reducing sLoP (Spurious Long-term Output Problems), though it remains a challenge.
---
Why K2 Thinking Stands Out
Benchmark Performance
- HLE & BrowseComp: Surpassed both GPT-5 and Claude 4.5.
- AIME25: Matching GPT-5 and Claude 4.5, far above DeepSeek V3.2.
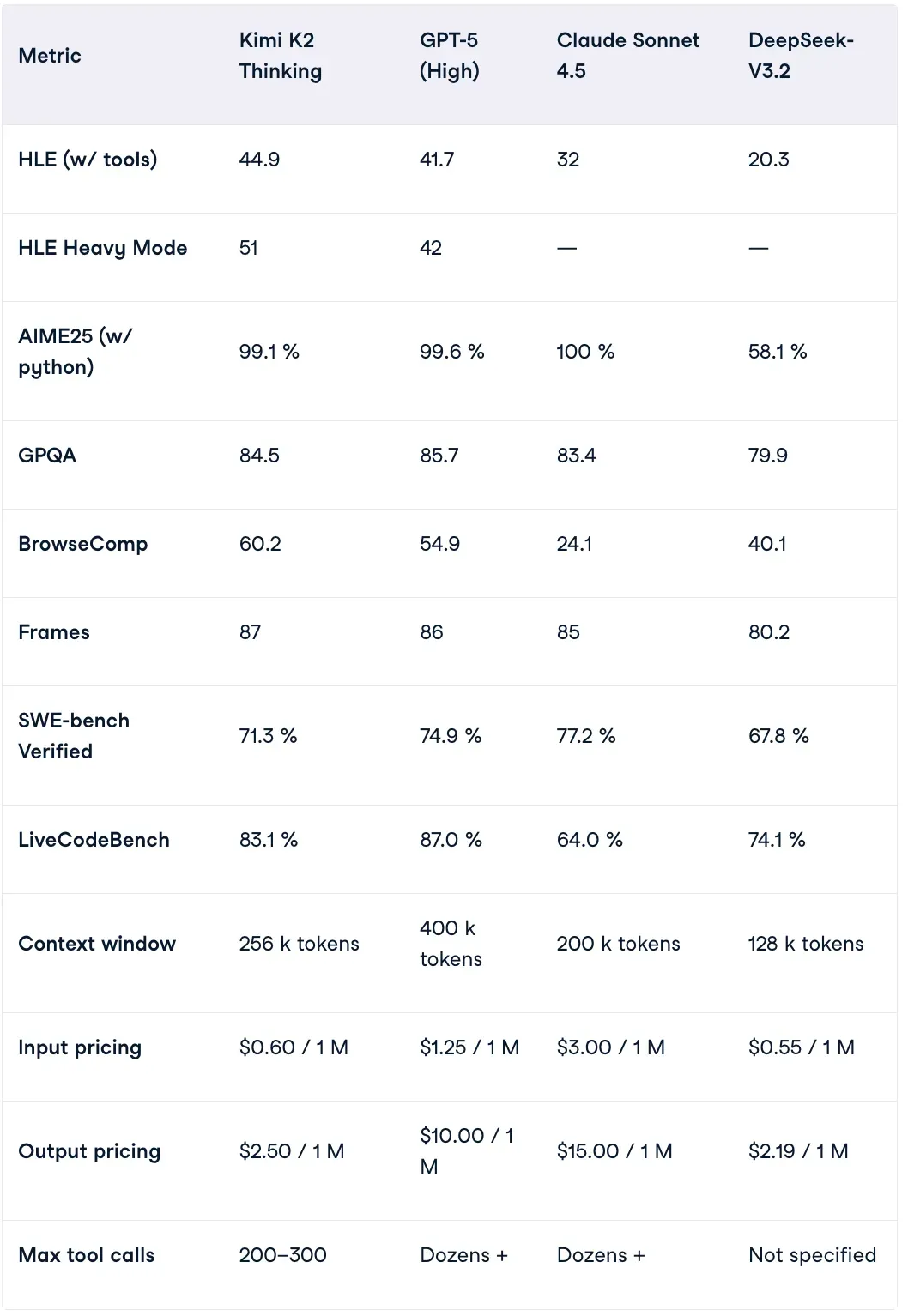
Source: datacamp
---
AMA Highlights
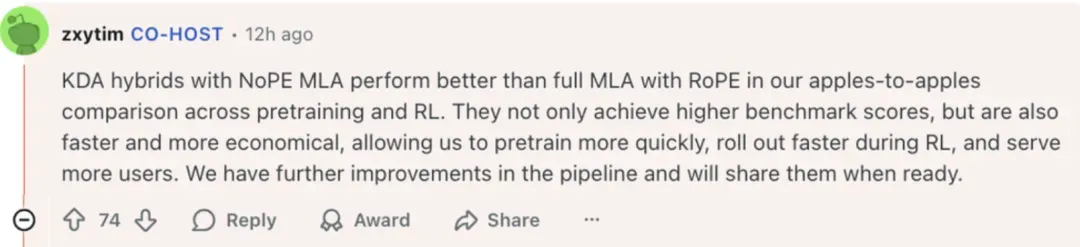
KDA (Kimi Delta Attention)
A key innovation replacing full attention with incremental update + gating.
Benefits:
- Solves MoE long-context instability
- Reduces large KV cache requirements
Future in K3:
> “Core ideas will very likely carry over to K3.” — Zhilin Yang
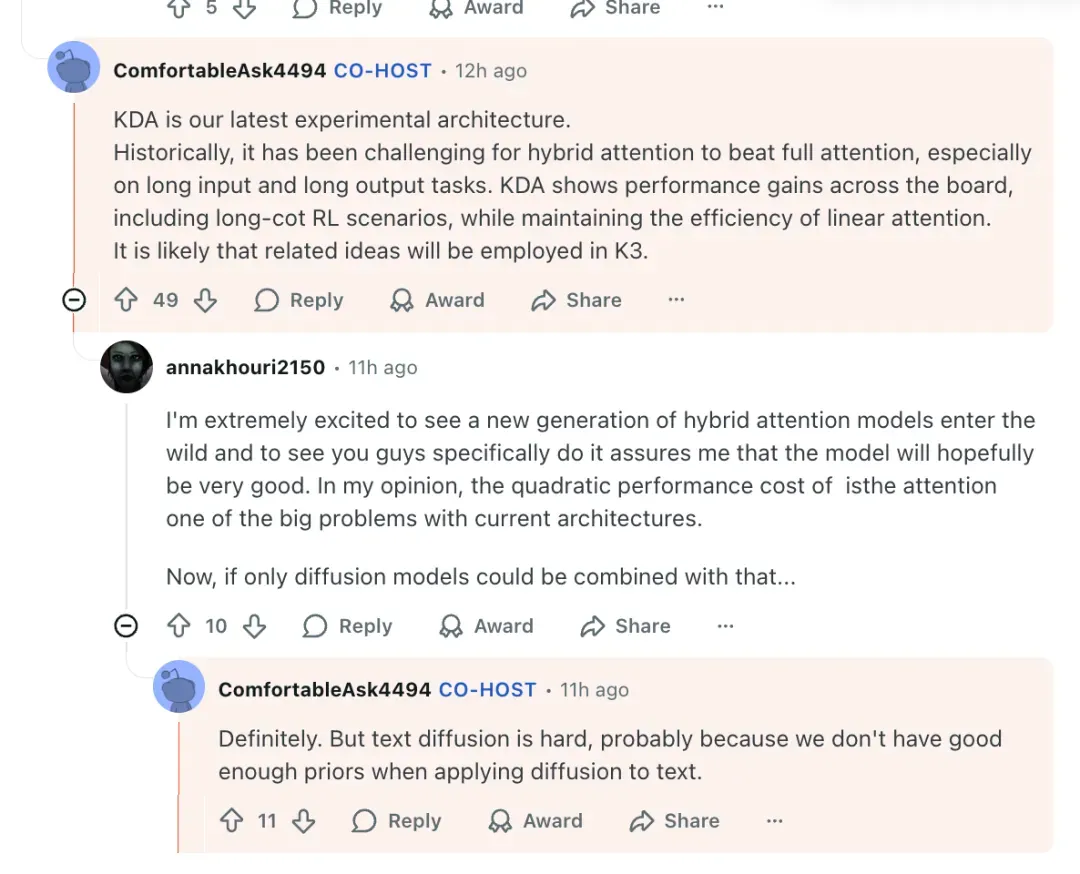
Further improvement plans: shared by Xinyu Zhou.
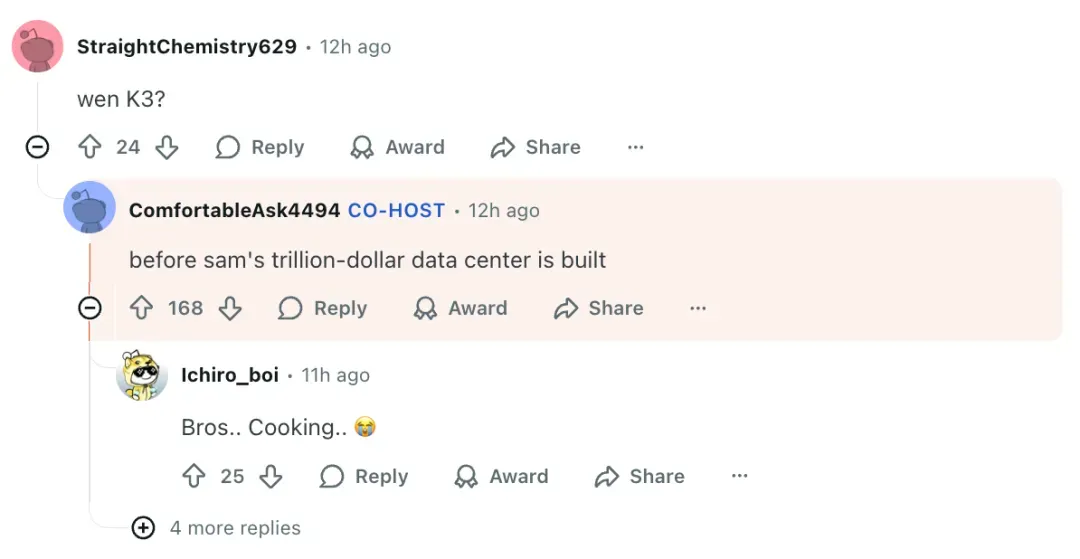
Release timeline joke:
> “Before Sam Altman’s trillion-dollar data center is completed.” — Zhilin Yang
---
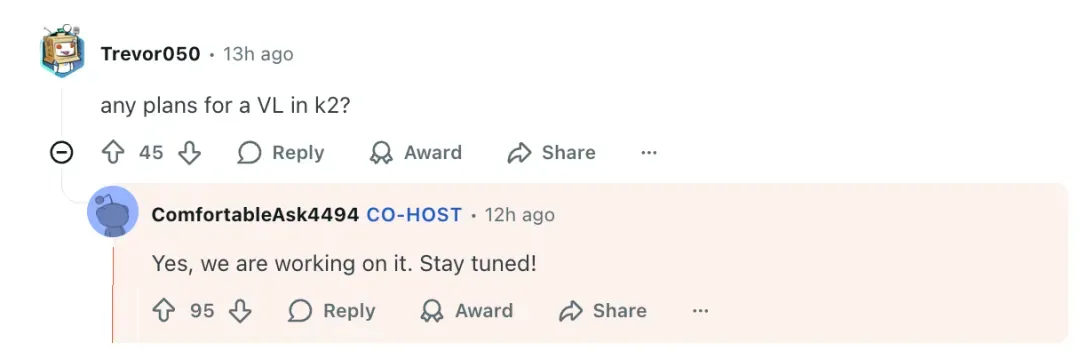
Vision-Language Model (VL) Plans
> “Yes, we are working on it. Stay tuned!” — Zhilin Yang
---
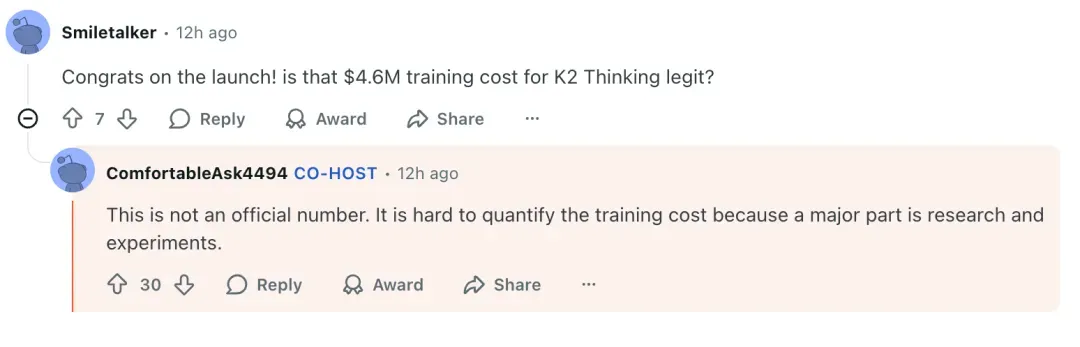
Training Cost Rumor
> “Not an official figure. Costs are hard to quantify due to research overhead.” — Zhilin Yang
---
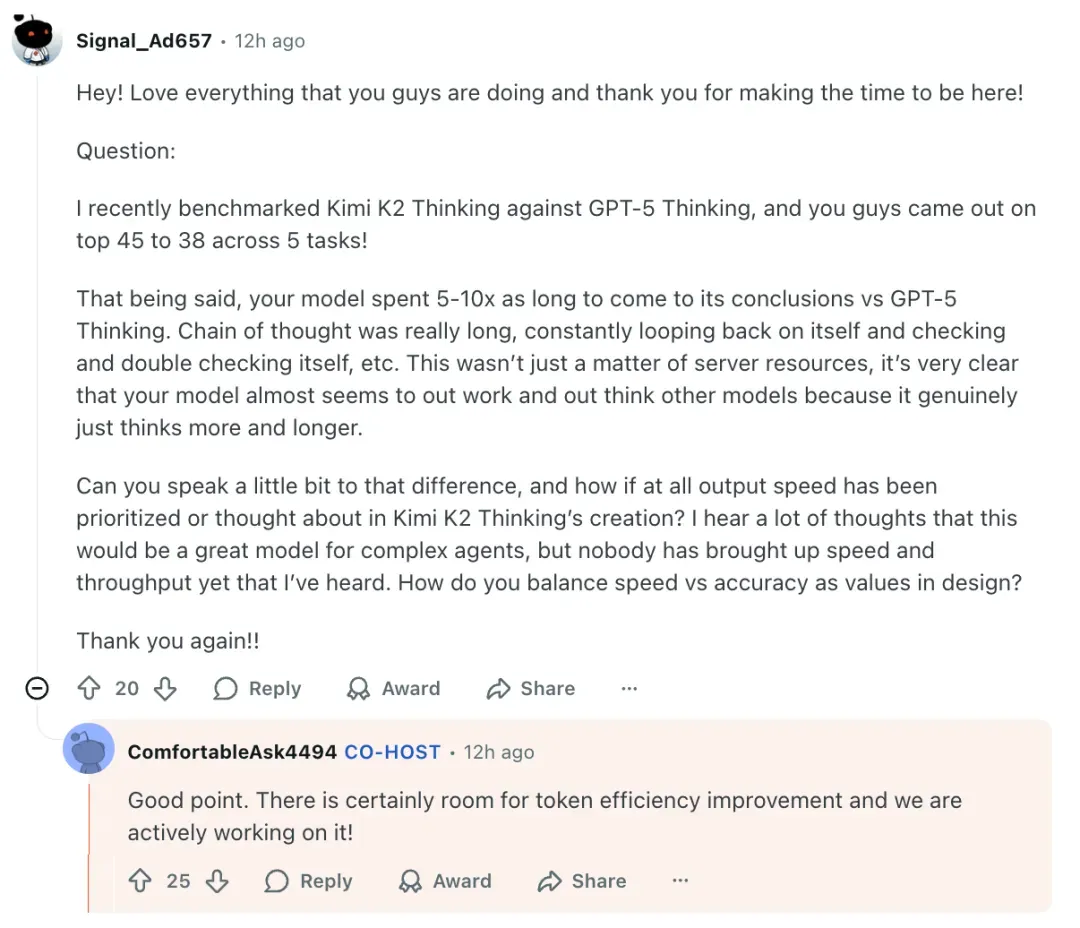
Speed vs Accuracy
K2 Thinking is slower than GPT‑5 (5–10×) but gives deeper reasoning.
Cause: internal long-chain reasoning mechanism.
> “We prioritize depth over speed but are improving token efficiency.” — Zhilin Yang
---
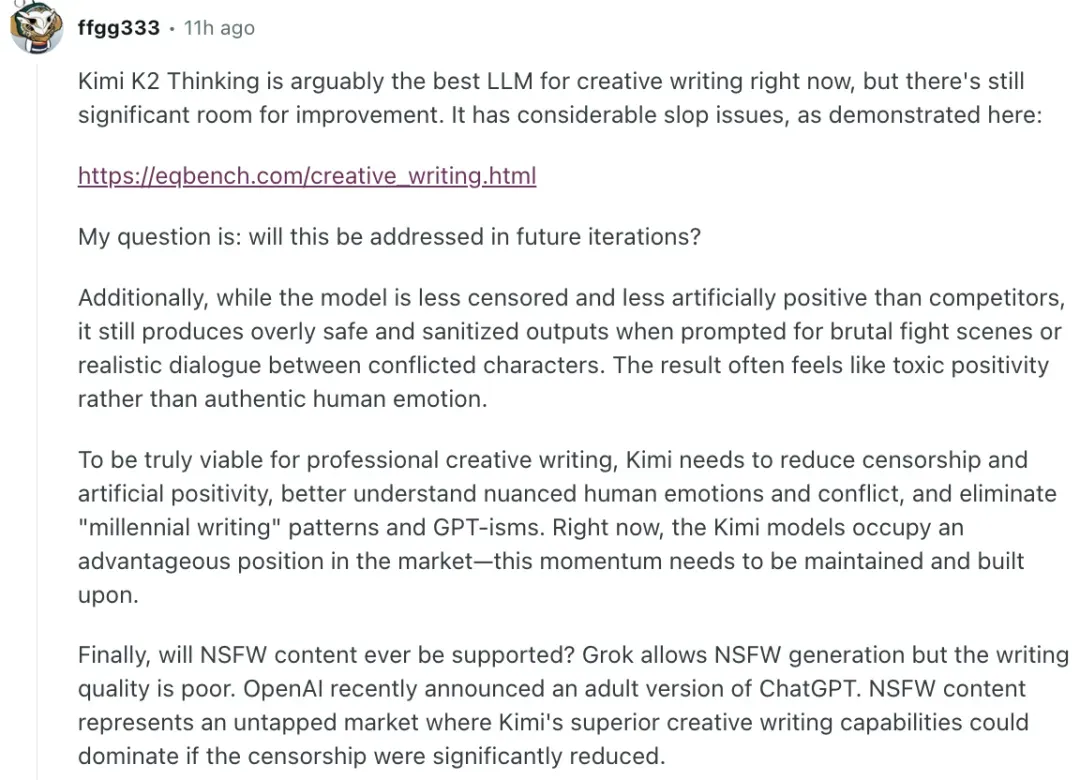
On ‘Slop Problem’ & Emotional Tone
User feedback: verbose, repetitive, lacking rhythm; sanitizing intense emotions.
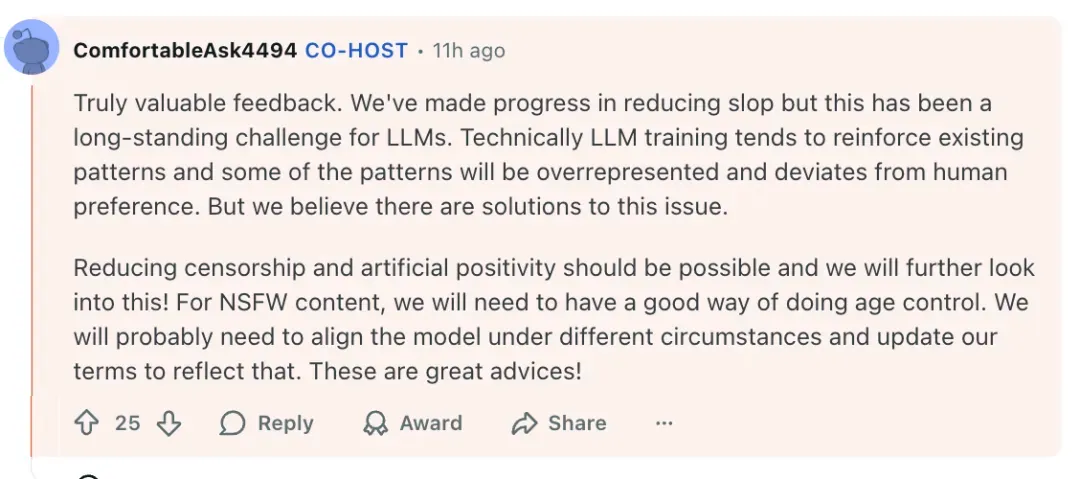
> “We’ve made progress, and will further reduce slop and censorship.” — Zhilin Yang
---
K2 Thinking — Game-Changer for Open Source
Architectural Strengths
- Built on Kimi K2 and beyond DeepSeek R1
- Trillion-parameter MoE, native INT4, 256k context
- Able to chain 200+ tool calls autonomously
- Designed as an Agent from the outset
Advanced features:
- Reasoning, search, coding, writing
- Test-Time Scaling for longer thinking and more tool invocations
Benchmark dominance:
HLE, BrowseComp, SWE-Bench — coherent and goal-oriented reasoning over hundreds of steps.
---
Agent-Level Coding Skills
Performance:
- SWE-Multilingual: 61.1%
- SWE-Bench Verified: 71.3%
- Terminal-Bench: 47.1%
Moves from code completion to full agentic programming:
- Understand requirements
- Generate & refine code
- Debug & verify autonomously
---
Intelligent Search & Browsing
Closely resembles research workflows:
- Iterative think–search–read–think cycles
- Handles ambiguous goals
- Constantly updates hypotheses & evidence
---
Writing & General Abilities
- Organizes long-form creative content naturally
- Academic research assistance
- Balanced, nuanced everyday responses
---
Engineering Highlights
Why INT4 over FP8?
Low-bit quantization is risky but efficient; solved via Quantization-Aware Training (QAT).
Results:
- Nearly 2× inference speed
- Minimal accuracy drop
- Stable lab & real-world performance
---
KDA Impact
- Reduces KV cache & memory by ~75%
- Maintains continuity & coherence in MoE
- Enables deep, stable reasoning in long tasks
---
Big Picture
K2 Thinking signals a shift toward:
- Smarter, lighter large models
- Deep, agent-like reasoning
- Sustainable real-world deployment
---
Portal:
References:
---
Related Reads
---
AI Leaders Debate: Is AI a Bubble?
Participants: Jensen Huang, Fei-Fei Li, Yann LeCun, and other top AI figures.
Discussion Themes:
- Market sustainability vs. hype
- LLM maturity vs. early stage potential
- Ethics & Regulation
- Long-term impact on education & work
Key quotes:
- Jensen Huang: AI is the next industrial revolution.
- Fei-Fei Li: Focus on human-centered AI.
- Yann LeCun: Need architectures capable of true reasoning.
---
Creator Tools: AiToEarn Platform
AiToEarn官网 gives users:
- AI content generation
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X)
- Analytics & model ranking (AI模型排名)
Open-source resources:
---
This rewrite organizes the article into clear sections with headings, highlights key facts, and keeps Markdown valid with all original links and images intact. Would you like me to also add comparison tables for K2 Thinking vs GPT‑5/Claude to make benchmarks easier to scan?


