Z Tech | LMSYS Team Releases Large-Scale MoE Reinforcement Learning Framework Miles — Small Steps Lead to Long Journeys

!image
Miles: Enterprise-Scale Reinforcement Learning for MoE & Production
The lightweight RL framework slime quietly gained popularity thanks to its support for diverse post-training pipelines and Mixture-of-Experts (MoE) tasks — including GLM‑4.6. Building on that foundation, the LMSYS team has officially introduced Miles: a reinforcement learning framework purpose-built for enterprise-scale MoE training and production workloads.
Miles is forked from slime, inheriting its lightweight and modular DNA, but with deep optimizations for next-generation hardware (e.g., GB300) and large-scale MoE deployments. It introduces infrastructure-level True On‑Policy, speculative training, and extreme memory management to deliver smooth, controllable large-scale RL training for teams that demand high reliability.
> "A journey of a thousand miles begins with a single step."
> The release of Miles is a major milestone in LMSYS’s vision for production-grade AI infrastructure.
---
🔍 Key Highlights
1. True On‑Policy (Strict Online Policy)
Infrastructure-level alignment between training and inference, eliminating subtle discrepancies. Uses:
- Flash Attention 3
- DeepGEMM
- Strict bit‑wise consistency ensures no divergence between training and deployment.
2. Speculative Sampling via MTP Online Training
Performs online SFT on the Draft Model during RL training to prevent distribution shift.
Benefits:
- 25%+ rollout acceleration
- Improved performance throughout training
3. Extreme Memory Optimization
Multiple system-level memory enhancements:
- NCCL Memory Margin Control
- Partial Offloading
- Peak Host Memory Savings
- Significantly reduces OOM risk in large-scale MoE scenarios.
---
🌱 Inherited Strengths from slime
Miles builds on slime’s lightweight structure and proven efficiency. Core advantages include:
- Native High Performance
- Optimized for SGLang and Megatron with direct support for rapid framework updates.
- Clear Modular Design
- Four decoupled modules: Algorithm, Data, Rollout, Eval. Easy insertion of new agents or reward functions.
- Researcher-Friendly
- Readable abstractions, ability to edit sampling or loss logic without touching the core.
- Includes independent debug modes for inference-only or training-only workflows.
Miles is a product of community-driven feedback from LMSYS and the SGLang ecosystem — turning open collaboration into robust engineering design.
---
⚙️ Technical Breakthroughs
Infrastructure-Level True On‑Policy
Strict numerical consistency between training and inference:
- Kernel-level optimization with Flash Attention 3, DeepGEMM
- Batch-invariant kernels from Thinking Machines Lab
- Alignment via `torch.compile`
> Goal: Reduce training–inference mismatch to zero.
---
🚀 Large-Scale MoE GPU Memory Optimization
Upgrades to avoid OOM while maximizing GPU throughput:
- Propagation mechanism to recover from benign OOM
- Memory Margin mechanism for NCCL-related OOM
- Fixed extra overhead in FSDP
- Partial Offloading via `Move` plus peak host memory reduction
---
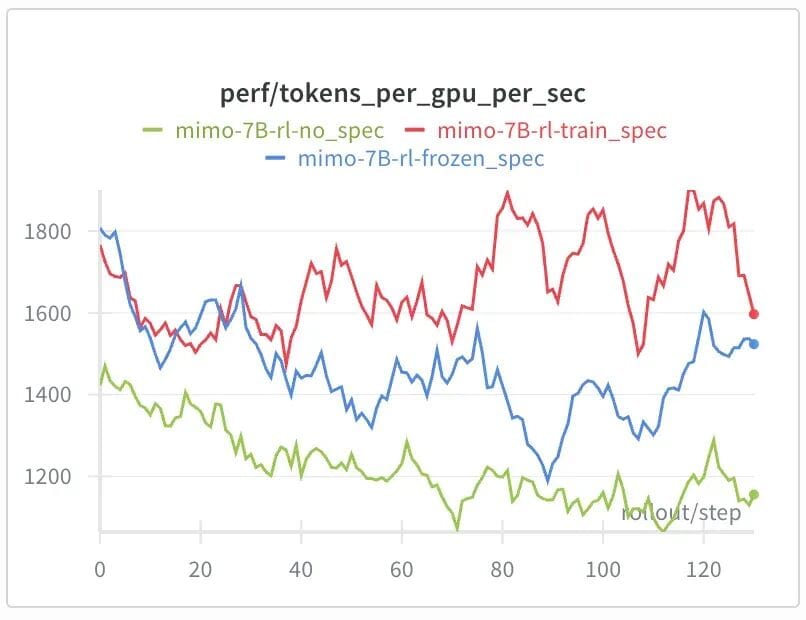
🎯 Speculative Sampling in Online SFT
Challenge: With a frozen Draft Model, RL training suffers from reduced Accept Length and slower rollouts.
Solution: Miles applies Online SFT to the Draft Model during RL training, delivering:
- 25%+ rollout acceleration over frozen MTP baseline
- Greater performance boost in later training stages
Compatibility:
- Works with MTP + Sequence Packing + Context Parallel (CP)
- Handles loss masking edge cases
- Gradient isolation for LM Head / Embedding
- Weight sync between Megatron and SGLang
---
🔧 Other Engineering Improvements
- FSDP Backend Stability enhancements for large-scale distributed jobs
- Independent Rollout Deployment to separate rollout subsystems for flexible cluster scheduling
- Advanced Debug Toolkit with extra metrics, analyzers, and profiling
- Mathematical Formal Verification via Lean examples (SFT/RL scripts)
---
📈 Roadmap & Vision
Planned Enhancements:
- New Hardware: GB300-scale RL + MoE training examples
- Multimodal Training support
- Rollout Acceleration with SGLang Spec v2, EAGLE3, multi-spec layer speculative techniques
- Elastic Training: Balanced resource allocation for asynchronous large-scale training, GPU failure tolerance
Miles owes its existence to slime’s authors and the broader SGLang/RL community. LMSYS invites researchers, startups, and enterprises to contribute — accelerating the path to efficient RL production environments.
Source: https://lmsys.org/blog/2025-11-19-miles/
---
🌍 Dissemination: Pairing Miles with AiToEarn
For teams looking to share, benchmark, and distribute AI work globally, tools like AiToEarn官网 are complementary:
AiToEarn Capabilities:
- Generate AI content
- Publish simultaneously to Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter
- Engagement analytics
- Track AI模型排名 via AI模型排名
While Miles optimizes training pipelines, AiToEarn ensures results and insights reach audiences worldwide — balancing technical scaling with knowledge distribution.



{kind=link}