Zero Downtime! A Thrilling Real-World Migration of 1 Billion Financial Records
A Migration Story That Stays With You Forever
Some projects leave a permanent mark.
For me, it was those long nights spent migrating over 1 billion records from our old database to a new one — without a single second of downtime.
We were moving mission‑critical financial data: payments, orders, ledgers. One mistake could cause customers to lose money, dashboards to crash, and trust to disappear overnight.
This journey was more than just a technical challenge — it was a test of system design under extreme pressure, requiring deep knowledge of databases, hard trade‑offs, and precise decision-making.
---
Why We Had to Migrate
Our legacy database had served us well, but scale had changed the game.
- Queries that used to take milliseconds now took seconds.
- Batch processes (such as settlement) ran for hours.
- We had already scaled vertically (stronger servers) and horizontally (read replicas) — still insufficient.
- Schema rigidity made feature development feel like open-heart surgery.
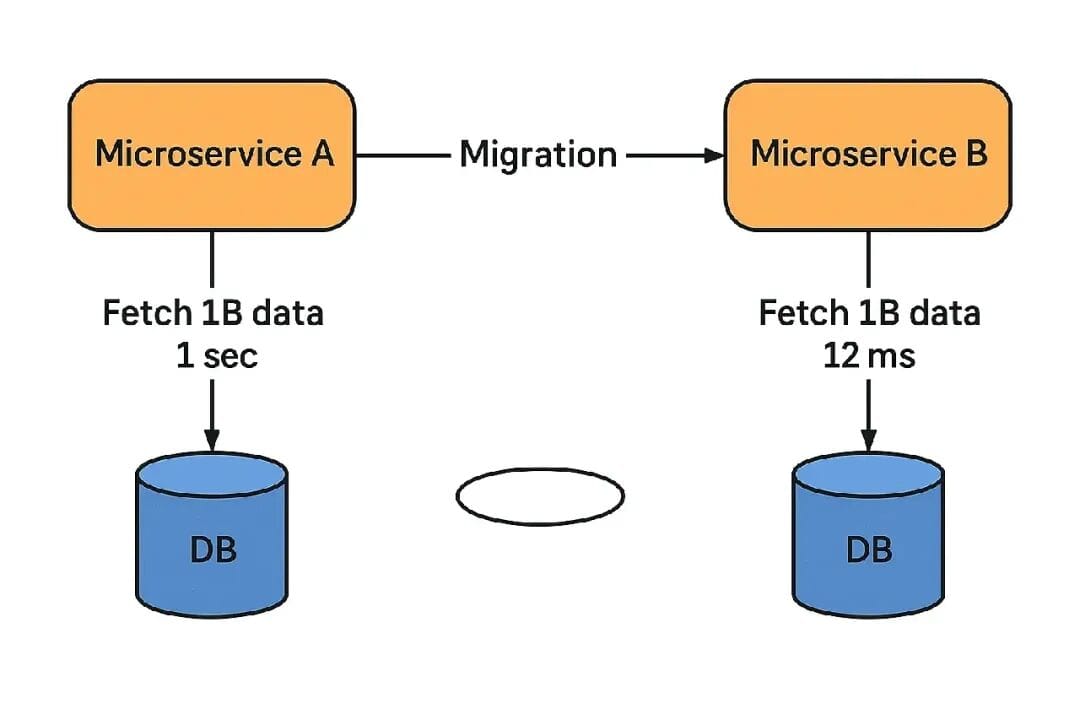
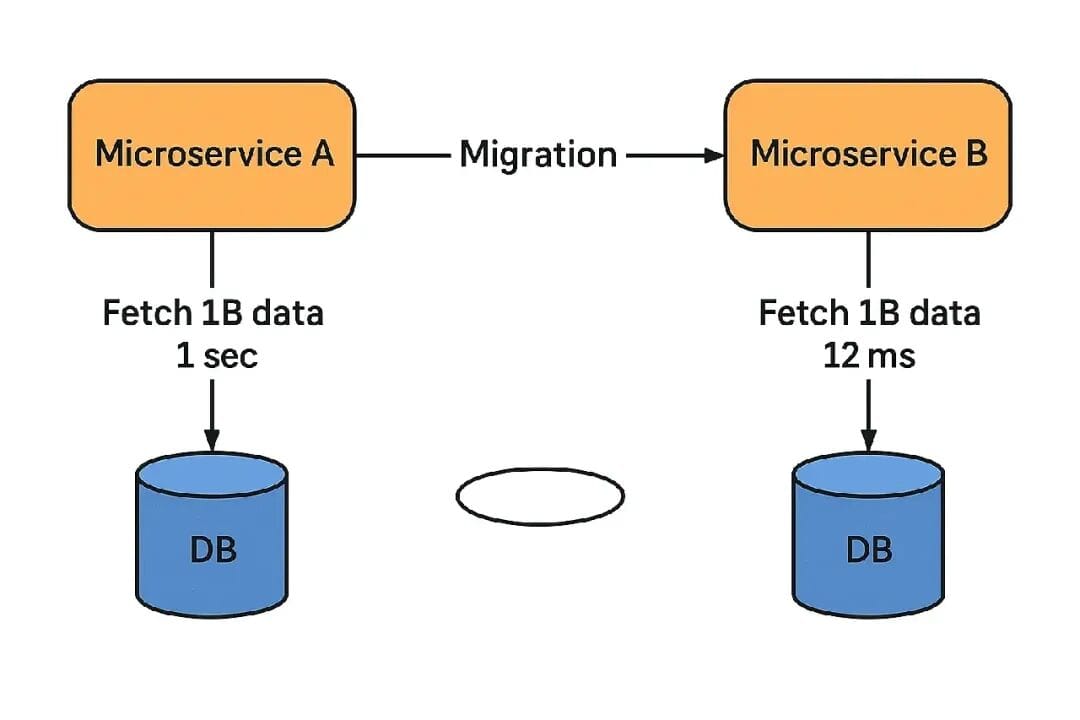
After crossing 1 billion records, performance was unacceptable.
Downtime was not an option.
Migration was unavoidable.
---
Step 1 — Bulk Migrate the Cold Data
We started with cold data — historical transactions that were no longer updated.
Why this is tricky:
- Exporting billions of rows consumes massive buffers, triggers disk spills, and risks crashes.
- Inserts update indexes, slowing everything down.
- Foreign key constraints require validation against other tables.
Our solution:
- Split tables into chunks by primary key ranges (e.g., `ID 1–5 M`, `5 M–10 M`).
- Disable secondary indexes and constraints during load.
- Run multiple parallel worker processes.
- After each chunk, run checksums to ensure exact data matches.
Lesson learned:
For massive migrations, avoid a single big move. Use chunks + parallel workers + idempotency.
---
Step 2 — Dual Writes to Handle Real-Time Traffic
While migrating old data, new transactions kept pouring in every second.
Our approach:
- Application code performed dual writes to both old and new databases.
- Failed writes to the new DB went into a Kafka retry queue.
- Consumers retried until successful.
- Each write had a unique ID to ensure idempotency.
Why it works:
Relational DBs write to a WAL (Write-Ahead Log) before committing. We ensured at least one successful write, then retried until both DBs matched.
> Lesson: Dual writing is a practical low-cost approach to distributed transactions. A retry queue saves you from partial failures.
---
Step 3 — Shadow Reads for Silent Validation
With both databases in sync, the question remained: Can we trust the new one?
Shadow reads strategy:
- Customers read from the old DB.
- The same queries execute silently on the new DB.
- Results are compared and differences logged.
Findings:
- Time zone differences (`TIMESTAMP WITHOUT TZ` vs `WITH TZ`).
- NULLs turning into default values.
- Different sorting due to UTF‑8 vs Latin1 collations.
> Lesson: Shadow traffic is essential; staging won’t surface real-world quirks.
---
Step 4 — The Switch (Cutover Night)
Data was synced, shadow reads passed — time for cutover.
Risks:
- Cold buffer pools cause slow queries.
- Unwarmed indexes hurt performance.
- Background tasks may spike disk I/O.
Our plan:
- Pre‑warm caches with synthetic queries.
- Schedule cutover during lowest traffic (4:30 AM).
- Enable feature flags to redirect reads to the new DB.
- Keep dual writes active for safety.
First 10 minutes monitoring Grafana:
- Latency — stable.
- Error rate — zero.
- Business metrics — all green.
> Lesson: Cutover requires pre‑warming, monitoring, and rollback readiness — not just flipping a switch.
---
Step 5 — Observability: The True Lifeline
Success came not from complex SQL, but from observability.
We monitored:
- Replication lag.
- Deadlocks.
- Cache hit rates.
- Shadow read mismatches.
- Business KPIs — orders, revenue flow.
> Lesson: Migration is a monitoring problem disguised as a data problem.
---
Key Trade-offs We Made
Big Bang vs Phased Rollout
- Big Bang: fast, irreversible.
- Phased: slower, reversible.
- ✅ We chose phased.
ETL vs Dual Write
- ETL: simpler, no real-time handling.
- Dual Write: complex, safe.
- ✅ We chose dual write.
Index Creation Timing
- During load: slows everything down.
- After load: faster overall.
- ✅ We delayed index creation.
---
The Human Side of Migration
- Business teams: “Can’t you just finish over the weekend?”
- DBAs: lost sleep over possible corruption.
- Developers monitored dashboards like a patient’s vital signs.
When success came, there were no cheers, only relieved silence.
---
Final Lessons for Zero-Downtime Migrations
- Idempotence is mandatory.
- Disable indexes/constraints during bulk loads.
- Use dual writes with unique IDs.
- Perform shadow reads under real traffic.
- Warm caches before cutover.
- Monitor internals, not just application metrics.
- Always have a rollback plan.
---
Conclusion
Migrating 1 billion records taught us:
It’s not just a database problem — it’s a system design problem.
You migrate batch by batch, WAL entry by WAL entry, checksum by checksum.
Treat migration like building a distributed system, and zero downtime becomes a matter of design, not luck.
---