Zhipu Was Just Unlucky — Visual Token Research Collided with DeepSeek

Glyph & DeepSeek-OCR: The Visual Token Showdown
It’s quite the coincidence — Zhipu and DeepSeek have crossed paths again.
Just one day after DeepSeek-OCR debuted, Zhipu open-sourced its own visual token framework: Glyph.

And on the same stage? Enter Karpathy, who’s been showering DeepSeek with likes the past few days:
> Maybe you’ll be interested in our work too.

Publishing papers is one thing —
Why does this feel like competing for affection? 🐶
Netizens joked: The AI world now has its own “CEO romance drama.”

---
The Context Length Problem
Like DeepSeek-OCR, Zhipu’s Glyph seeks to tackle overly long LLM contexts — but does so visually.
As LLM capabilities climb, long context needs rise sharply.
Whether for:
- Long document analysis
- Code reviews
- Complex, multi-round dialogues
…models can’t afford goldfish memory. They need large, stable working memory.
Why Extending Context Is Difficult
Extending context length is costly:
- Doubling context length from 50K → 100K quadruples computational costs.
- More tokens = more activations, caches, and attention weights = higher training & inference bills.
And even then — you may not get better performance.
IBM research highlights that more tokens ≠ linear improvements — longer, noisier inputs may cause overload and reduce accuracy.
---
Mainstream Approaches to Long Context
1. Extending Positional Encoding
- Transformer models don’t natively grasp token order.
- Positional encoding stretches input range, e.g., from 0–32K → 0–100K.
- Limitations: still process all tokens, no training on huge ranges, results are limited.
2. Attention Mechanism Optimisation
- Use sparse/linear attention for efficiency.
- Limitations: efficiency gains can’t overcome hundreds of thousands of tokens.
3. Retrieval-Augmented Generation (RAG)
- Retrieve only relevant content to feed model.
- Limitations: retrieval isn’t as reliable as trained responses; slows down responses.
---
Glyph’s Approach: Images as Memory
Glyph’s philosophy:
If raw text lacks information density, render it as an image.
Why This Matters
- Text → split into tokens → processed sequentially → low efficiency
- Visual tokens pack dense information in fewer units
- Allows fixed-context VLMs to handle much longer works without complex tricks
---
Example: Compressing Jane Eyre
- Jane Eyre ≈ 240K text tokens
- Traditional LLM (context window: 128K) can process ≈ half.
- Glyph rendering → ≈ 80K visual tokens
- VLM with 128K context can “see” and process the entire book.
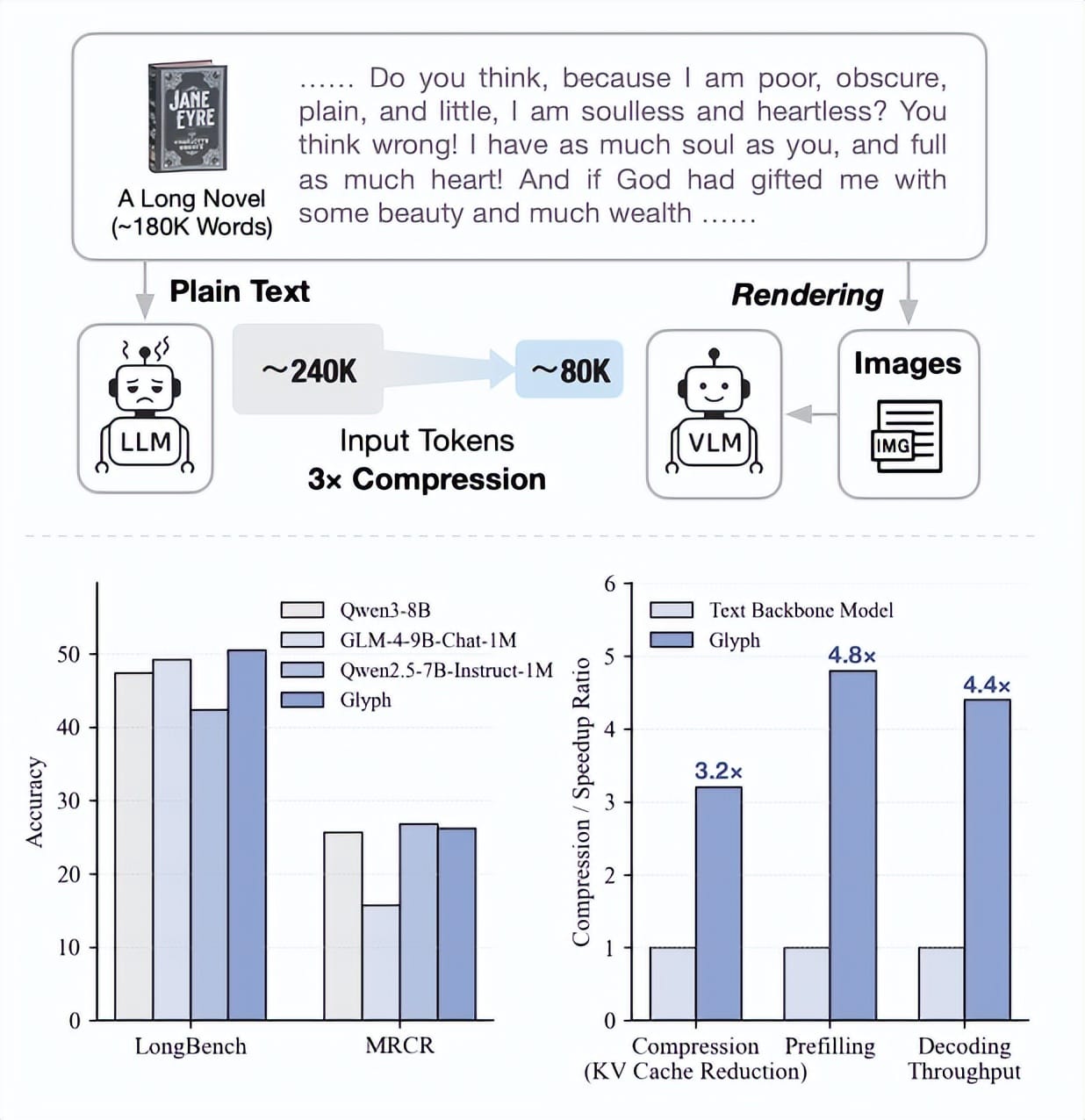
This enables broader plot understanding and global question answering.

---
Glyph's Training Process
Stage 1: Continual Pre-Training
- Render long text into images with varied fonts, layouts, and styles.
- Train VLM to align image text with semantic meaning.
Stage 2: LLM-driven Rendering Search
- Balance compression rate vs readability.
- Use genetic search to optimise:
- Font size
- Layout
- Resolution
Stage 3: Post-Training
- Apply Supervised Fine-Tuning (SFT) & Reinforcement Learning (RL).
- Introduce OCR alignment tasks to preserve fine-text detail.
---
Skills Achieved
- Precise reasoning over long text
- Detail extraction from images without strain
---
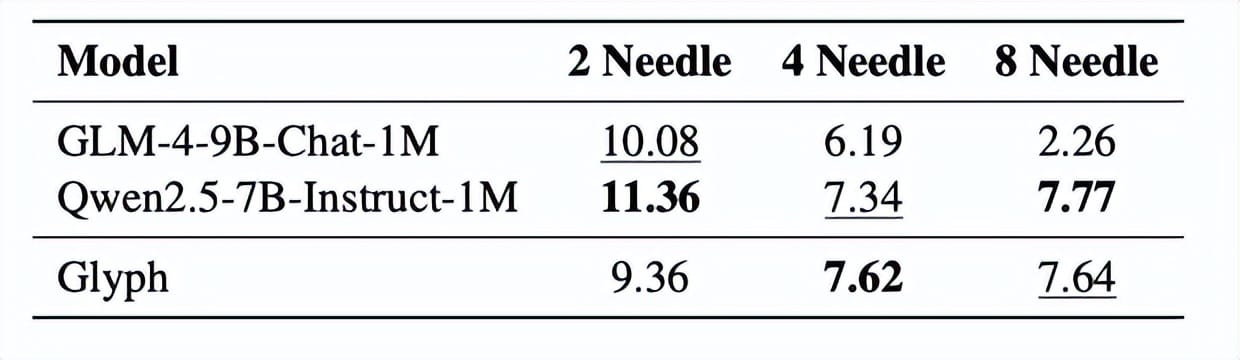
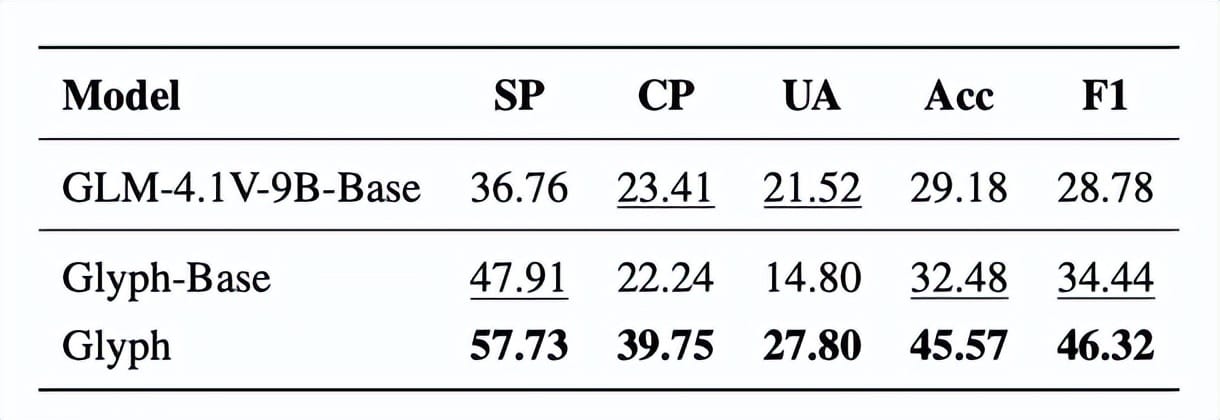
Glyph’s Performance
- 3–4× token compression while matching accuracy of Qwen3-8B
- 4× faster prefill & decoding
- 2× faster SFT training
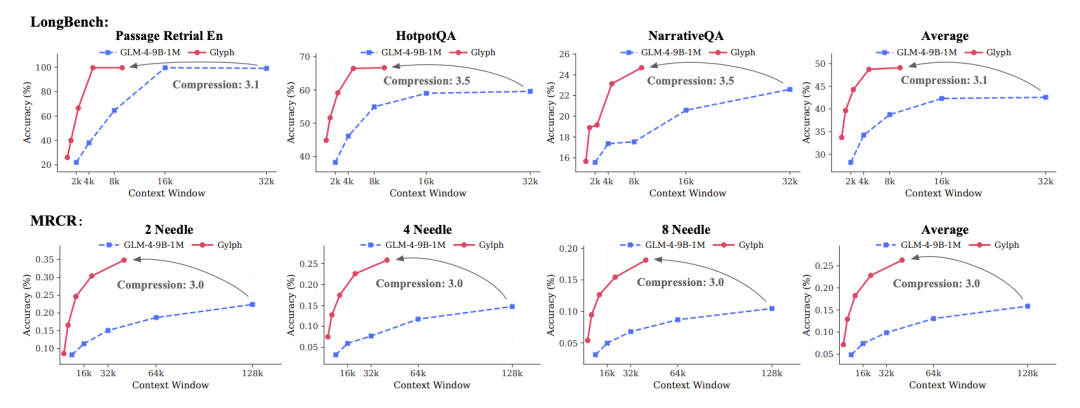
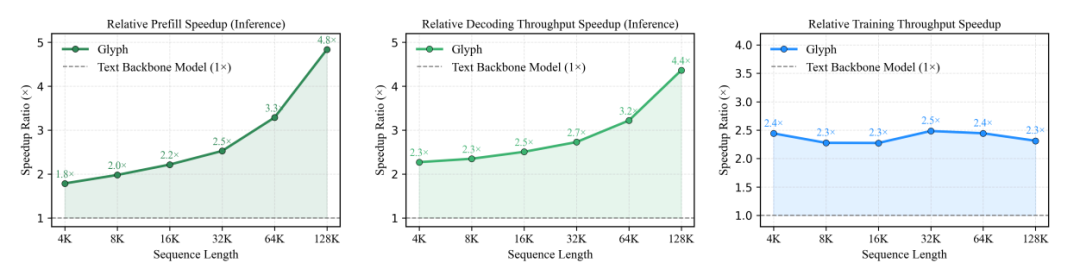
- Handles million-token tasks in a 128K window
- Strong multimodal generalisation despite image-tuned data
---
Paper: https://arxiv.org/pdf/2510.17800
GitHub: https://github.com/thu-coai/Glyph
Reference: [1] https://x.com/ShawLiu12/status/1980485737507352760
---
Humans, Visual Tokens & AI Futures
DeepSeek-OCR achieves 97.3% accuracy with 10× fewer tokens.
OCR enables a single NVIDIA A100-40G to process >200K pages/day, reducing pre-training costs drastically.
Karpathy notes pixels > text for LLM input:
- Greater compression → shorter context, greater efficiency
- More expressive bandwidth → includes fonts, colours, arbitrary images
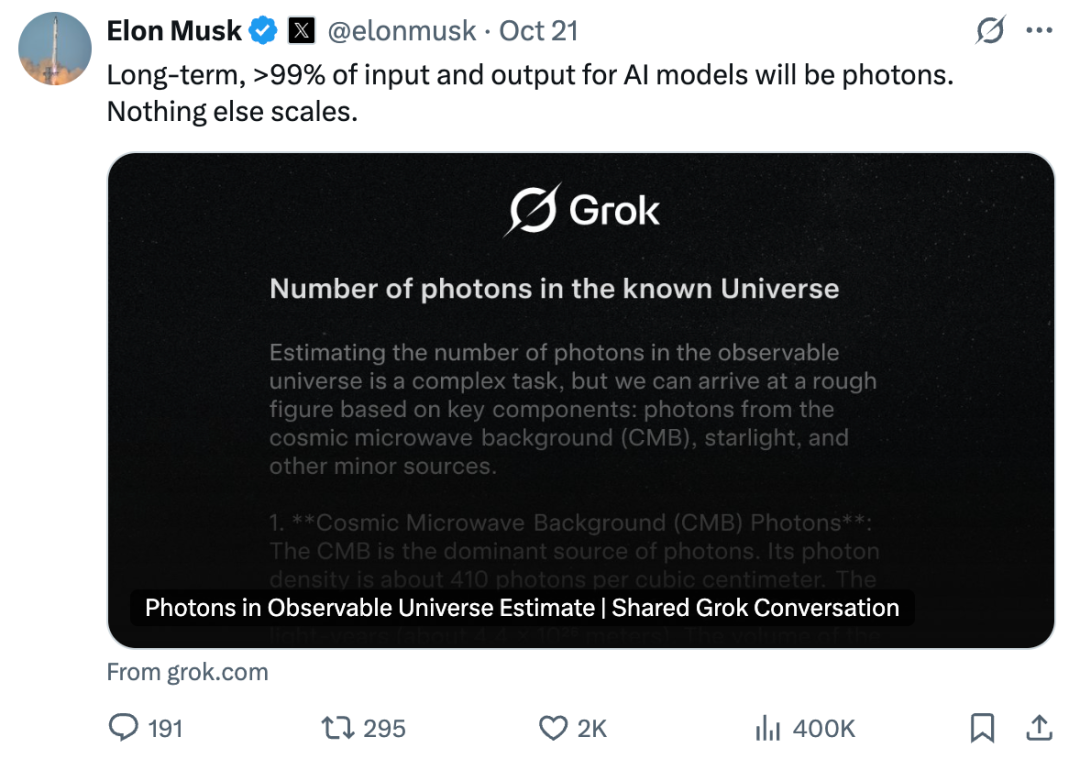
Elon Musk is even bolder:
> In the long run, over 99% of inputs/outputs for AI models will be photons.
---
Neuroscience Connection
Human brains process images first — text is an abstraction layer.
OCR and visual tokens mimic how we naturally absorb data.
This could reshape LLMs’ core information handling:
- From text → pixels
- From linear reading → visual comprehension
---
Linking Research to Content Creation
Platforms like AiToEarn官网 bring these concepts into real-world publishing:
- AI-driven content generation
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X)
- Integrated analytics & AI model rankings (AI模型排名)
Developer resources:
- Docs: AiToEarn文档
- GitHub: AiToEarn开源地址
This bridges cutting-edge AI research with global monetisation.
---
📌 Summary
Glyph:
- Renders text → images → processed as visual tokens
- Achieves compression, speed & performance gains
- Mimics human visual cognition
Visual tokens are not just a niche trick — they may be the next fundamental shift in AI context modelling.
---
If you want, I can prepare a side-by-side bilingual Chinese-English version of this Markdown for technical teams working in multilingual environments — making it easier to reference and discuss across research and engineering teams.
Would you like me to produce that next?