Zhipu Wujie·Emu3.5 Released, Launching “Next-State Prediction”! Wang Zhongyuan: Could Open the Third Scaling Paradigm

WuJie·Emu3.5 — The Next Leap in Multimodal World Models
Introduction
In October 2024, the Beijing Academy of Artificial Intelligence (BAAI) released the world’s first natively multimodal world model — WuJie·Emu3.
This groundbreaking model is based entirely on next-token prediction, avoiding diffusion or composite methods, and achieves a unified representation across images, text, and video.
One year later, BAAI launched WuJie·Emu3.5, extending the Next-Token Prediction paradigm to Next-State Prediction (NSP) for multimodal sequences. This evolution mimics human-style learning and provides generalized world modeling capabilities.
---
Core Principles
> "The essence of a world model is predicting the next spatio-temporal state." — Wang Zhongyuan, BAAI Director
Wang emphasized that world modeling is vital for embodied intelligence — far beyond just handling video or images.
Real-World Analogy
Humans naturally form multimodal understandings of their environments (e.g., seeing coffee near the edge of a table and anticipating the risk of falling).
Robots interacting in such scenarios must precisely control force, timing, and direction.

📄 Paper: Read on arXiv
---
Key Enhancements in Emu3.5
Emu3.5 introduces three major upgrades:
- Intention to Planning
- Understand high-level human goals (e.g., build a spaceship, make latte art)
- Autonomously generate multi-step action plans
- Dynamic World Simulation
- Unified framework for understanding → planning → simulation
- Can predict physical dynamics, spatio-temporal evolution, and causal relationships
- Foundation for Generalized Interaction
- Emergent causal reasoning and planning
- Supports human-AI interaction in physical and digital contexts
---
The Third Scaling Paradigm
> "Emu3.5 may mark the beginning of the third scaling paradigm." — Wang Zhongyuan
From Language Models to Multimodal Scaling
- Language Scaling: Increased parameters, datasets, and compute boosted LLM performance
- Challenge: Text data is nearing saturation
- Recent Trend: Scaling via post-training & inference stages to unlock potential
Multimodal AI lacked a mature scaling approach — until now.
Why Emu3.5 Can Scale
- Autoregressive Design — Unified architecture for multimodal data
- Large-Scale Multimodal RL — First successful application in an autoregressive multimodal model
- Performance Gains — Production-level results, prepped for industrial adoption
---
Back to First Principles
Humans start learning visually — not with text.
With the ubiquity of video, AI models now have an ideal medium for world knowledge learning:
- Understanding operational rules
- Building causal reasoning
- Learning physical common sense
---
Limitations of Current Approaches
Most AI systems separate understanding from generation.
This often leads to:
- Forgetting — Memory limitations remain unsolved
- Poor Agent Optimization — Limited usability in applied contexts
Emu series solves this using a unified autoregressive architecture where the next token may be visual or text, with no performance trade-off.
---
Real-World Applications
Platforms like AiToEarn integrate such models into content workflows:
- AI-Driven Content Creation
- Cross-Platform Publishing (Douyin, Kwai, Instagram, YouTube, X, etc.)
- Revenue Opportunities for creators & researchers
---
Technological Innovations
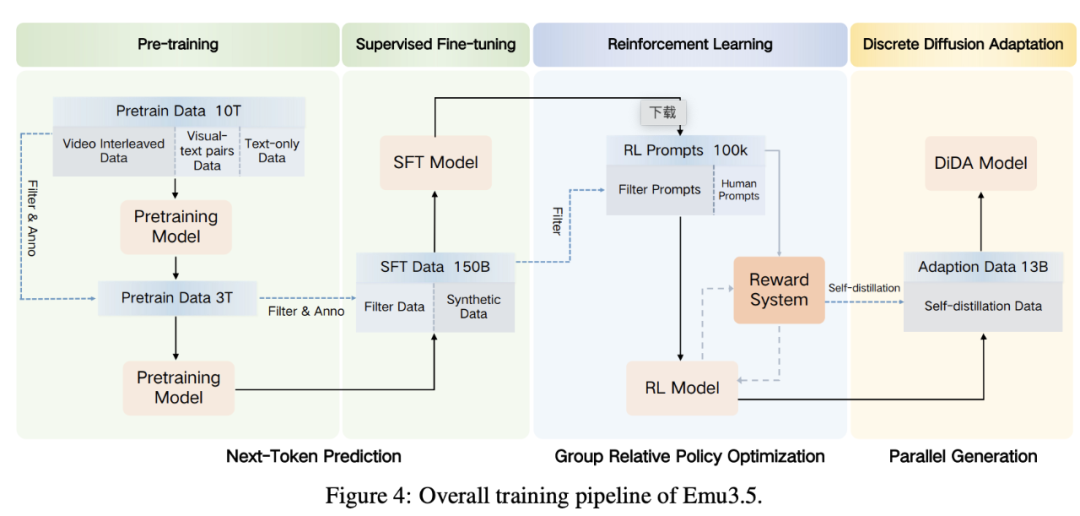
1. Two-Stage End-to-End Pretraining
- Stage 1 & 2: ~13 trillion tokens
- Data diversity: Higher resolution, quality, annotation richness
- Unified multimodal generation interface
- Final steps: SFT (150B samples) → Large-scale RL → DiDa tech for fast inference
Dataset Highlights:
- 10T+ tokens
- 63M videos (avg. 6.5 min)
- Total: ~790 years of video time
- Covers real-world & imaginative domains
- Only 1% of publicly available online videos
> Parameter Size: 34B — significant room for scaling
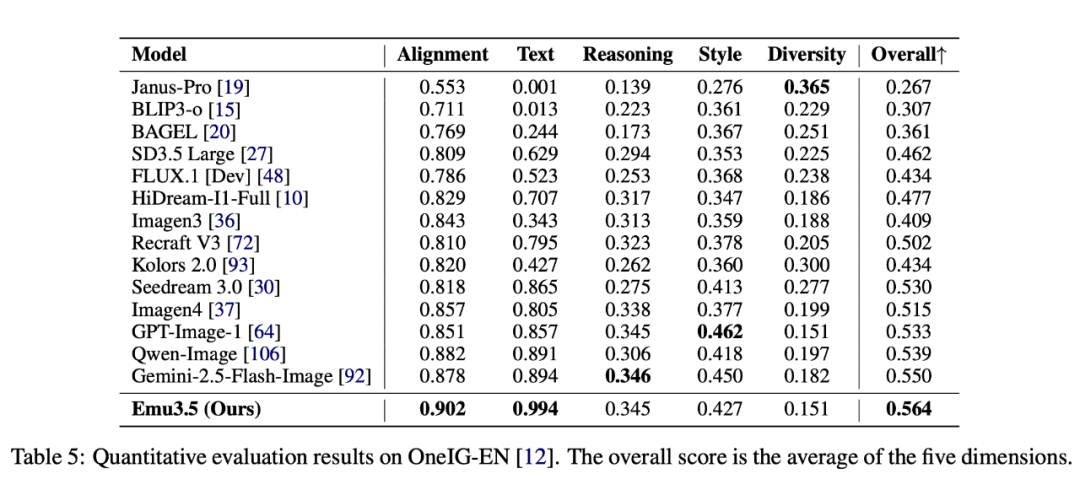
---
2. Large-Scale Native Multimodal RL
Key achievements:
- Unified multitask multimodal RL
- Reward system designed for generality, task-specificity, and uniformity
- Handles complex multimodal outputs: text → image, text + image → image edit
Example: Generating sequences like “taking out a phone step-by-step” or “pouring water” — with realism and interaction.
---
3. Practical Breakthroughs in Inference Acceleration
Challenge: Autoregressive models are slower than diffusion-based ones
Solution: DiDa Technology — lossless next-token prediction acceleration → 20× speed boost
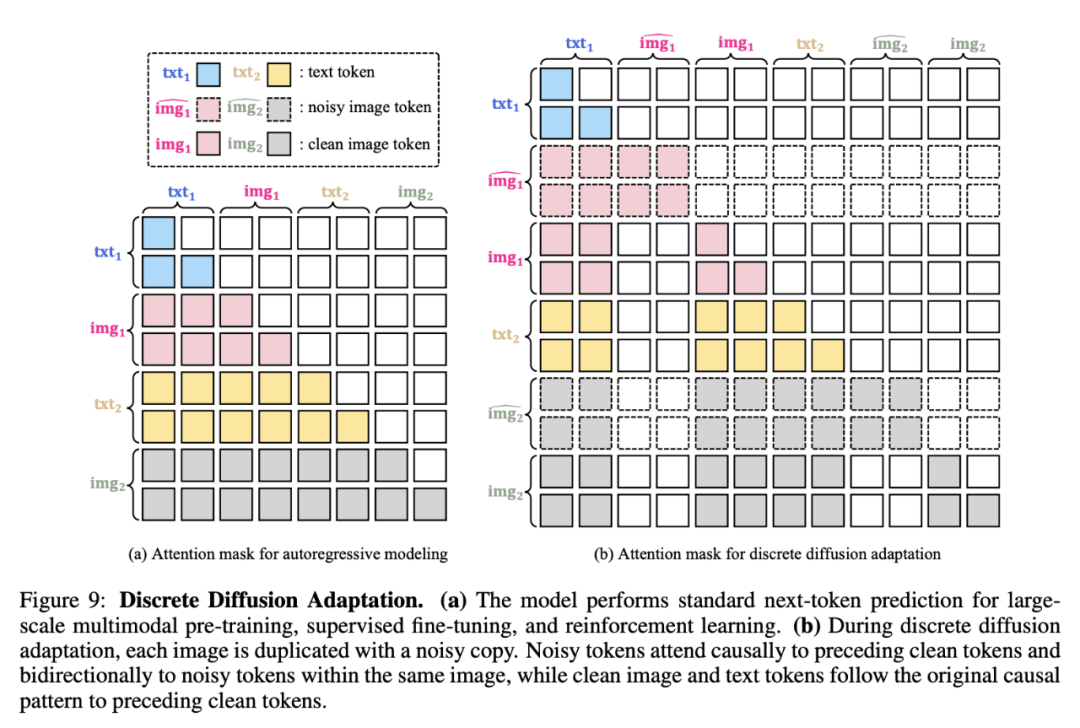
How DiDa Works
- Extends discrete diffusion formula to visual tokens
- Generates initial image token sequence in parallel
- Refines via multiple discrete denoising steps
> “A 20× acceleration drastically reduces the cost of native multimodal processing.” — Wang Xinlong
---
Conclusion
WuJie·Emu3.5 stands out as a multimodal world model that can:
- Understand and generate across space, time, and modalities
- Maintain long-term consistency
- Reason causally about physical and temporal events
It may open a new track in large model evolution — bridging theoretical AI capabilities with real-world creator economies.
---
🔗 Related Platform: AiToEarn官网 — public, open-source AI monetization ecosystem for cross-platform distribution and analytics.
---
Would you like me to also produce a side-by-side comparison chart between Emu3 and Emu3.5 to make the upgrades clearer? This could make the Markdown even more reader-friendly.