# Introducing Zoomer: Meta’s Automated AI Debugging & Optimization Platform
## Overview
**Zoomer** is Meta’s **comprehensive, automated platform** for profiling, debugging, and optimizing AI workloads.
It supports **all training and inference operations** across Meta, delivering **deep performance insights** that:
- Reduce **energy consumption**
- Accelerate **workflows**
- Improve **AI infrastructure efficiency**
Zoomer has significantly reduced training times and increased **Queries Per Second (QPS)**, making it the **standard tool for AI performance optimization** at Meta.
---
## Why Performance Debugging Matters
At Meta’s scale, hundreds of thousands of GPUs run AI workloads. Even **small inefficiencies** can lead to:
- **Energy waste**
- **Higher operational costs**
- **Underutilized hardware**
A **1–2% improvement** in utilization can translate into **major capacity gains** for innovation and expansion.
Zoomer addresses this with **automated profiling, debugging, and optimization**—producing **tens of thousands** of profiling reports daily for engineering teams supporting all Meta applications.
🔗 **Background Articles**:
- [Meta’s Infrastructure Evolution and the Advent of AI](https://engineering.fb.com/2025/09/29/data-infrastructure/metas-infrastructure-evolution-and-the-advent-of-ai/)
- [Maintaining Large-Scale AI Capacity](https://engineering.fb.com/2024/06/12/production-engineering/maintaining-large-scale-ai-capacity-meta/)
---
## AI Ecosystem Context
Zoomer’s principles—**integrated analysis**, **efficient workload distribution**, and **streamlined publishing**—are valuable across industries.
Example: **[AiToEarn官网](https://aitoearn.ai/)** (open-source)
Provides AI creators with tools for:
- Content generation
- Cross-platform publishing
- Analytics & model ranking
- Monetization across Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
---
## AI Workload Scale at Meta
**Training Level:**
Supports models for:
- [Ads Ranking](https://engineering.fb.com/2025/11/10/ml-applications/metas-generative-ads-model-gem-the-central-brain-accelerating-ads-recommendation-ai-innovation/)
- [Content Recommendations](https://engineering.fb.com/2025/05/21/production-engineering/journey-to-1000-models-scaling-instagrams-recommendation-system/)
- [GenAI Features](https://engineering.fb.com/2025/05/20/web/metas-full-stack-hhvm-optimizations-for-genai/)
**Inference Level:**
Executes **hundreds of trillions** of AI model runs daily.
---
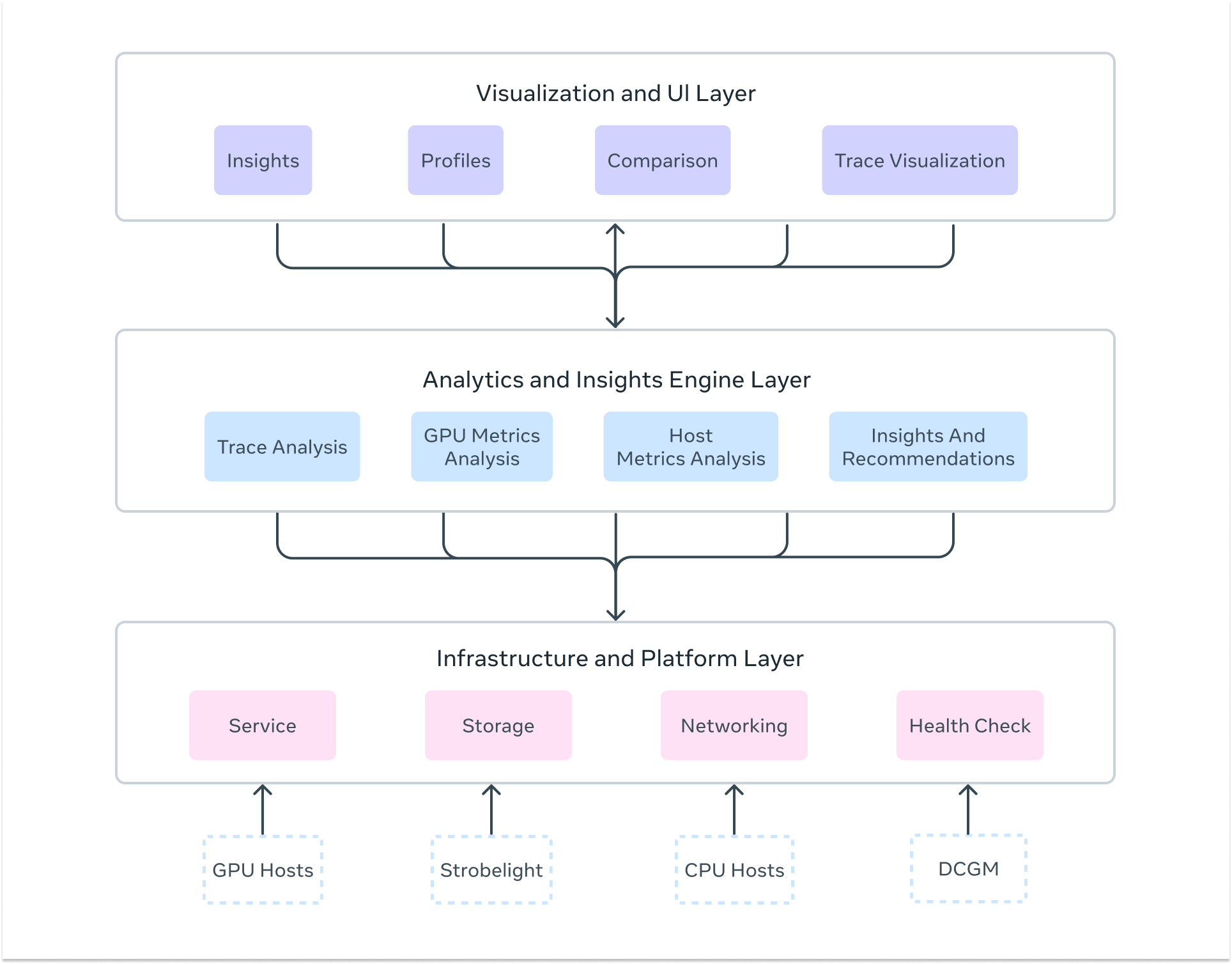
## Zoomer’s Three-Layer Architecture
### 1. Infrastructure & Platform Layer
- **Scalable profiling** across Meta’s infrastructure
- Distributed storage via [Manifold](https://www.youtube.com/watch?v=tddb-zbmnTo)
- Fault-tolerant trace processing pipelines
- Automated profiling triggers on thousands of hosts
- Redundant workers for **high availability**
### 2. Analytics & Insights Engine
- **GPU analysis** via Kineto + NVIDIA DCGM
- **CPU profiling** via [StrobeLight](https://engineering.fb.com/2025/01/21/production-engineering/strobelight-a-profiling-service-built-on-open-source-technology/)
- **Host-level metrics** via [dyno telemetry](https://developers.facebook.com/blog/post/2022/11/16/dynolog-open-source-system-observability/)
- Communication + straggler detection
- Memory allocation profiling
- Automatic anti-pattern detection & optimization suggestions
### 3. Visualization & UI Layer
- Interactive GPU activity timelines
- Multi-iteration training analysis
- Drill-down dashboards
- Perfetto integration for kernel inspection
- GPU deployment heat maps
- Automated insight summaries
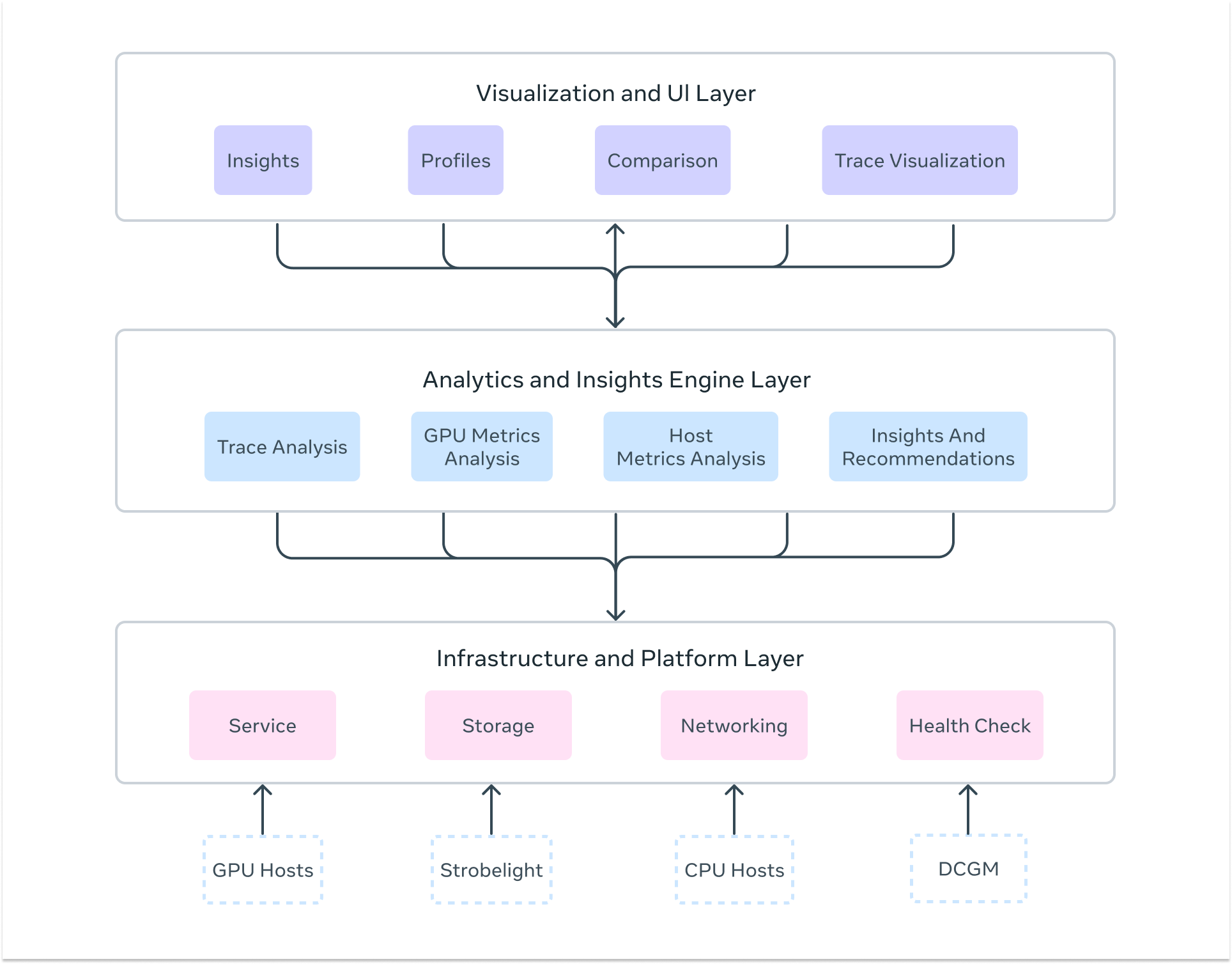
*Zoomer architecture layers.*
---
## How Zoomer Profiling Works
### Trigger Mechanisms
- **Training workloads**: Auto-profile at iteration 550–555 for stable-state capture
- **Inference workloads**: On-demand or integrated with benchmarking systems
### Data Captured
- **GPU metrics**: Utilization, bandwidth, Tensor Core usage, power, clocks
- **Execution traces**: CUDA calls, communications, memory transfers
- **Host metrics**: CPU/memory/network/storage usage
- **Annotations**: Iteration phases, passes, optimizer steps
- **Inference-specific data**: Request rate, latency, memory patterns
- **Communication analysis**: NCCL operations, network utilization
---
## Distributed Analysis Pipeline
### Automated Analyses
- **Straggler detection**
- **Bottleneck analysis**
- **Critical path analysis**
- **Anti-pattern detection**
- **Parallelism analysis**
- **Memory analysis**
- **Load imbalance detection**
---
## Results Delivery Formats
- Interactive timelines
- Metrics dashboards
- Perfetto kernel-level viewers
- Insight summaries
- Actionable notebooks for re-running jobs with optimizations
---
## Specialized Workload Support
### For Large-Scale GenAI Training
- Dedicated LLM workload platform
- GPU efficiency heat maps
- N-dimensional parallelism visualizations
### For Inference
- Single GPU → massive distributed inference analysis
- Kernel execution optimization
- Memory access tuning
---
# Advanced Zoomer Capabilities
## Training Features
- Straggler analysis
- Critical path analysis
- Advanced trace manipulation (multi-GB)
- Memory profiling
## Inference Features
- Single-click QPS optimization (+2%–50% gains)
- Request-level deep dive via Crochet
- Realtime memory profiling
## GenAI Specialized
- LLM Zoomer for 100k+ GPU workloads
- Post-training profiling (SFT, DPO, ARPG)
- GPU efficiency mapping
## Universal Intelligence
- Holistic Trace Analysis (HTA)
- Auto-recommendations engine (Zoomer AR)
- Multi-hardware profiling (NVIDIA, AMD MI300X, [MTIA](https://ai.meta.com/blog/next-generation-meta-training-inference-accelerator-AI-MTIA/), CPU)
---
## Optimization Impact
**Workflow:** Bottlenecks → Metric improvements → Workflow acceleration → Resource reduction → Energy & cost savings
### Training Gains
- Algorithmic optimizations for fleet-wide power savings
- 75% training time reduction for Ads relevance models
- 20% QPS increase with one-line memory copy fix
### Inference Gains
- 10–45% power reduction via parameter tuning
- QPS boosts through GPU trace analysis
---
## Large-Scale Impact
- **32k GPUs**: 30% speedup from broadcast fix
- **64k GPUs**: 25% speedup in <24h
---
## Looking Ahead
Zoomer is evolving toward:
- Cross-hardware insights
- Proactive analyzers
- Democratized optimization tools
---
## Related Open-Source Ecosystem
**[AiToEarn官网](https://aitoearn.ai/)** enables AI creators to:
- Generate content from AI models
- Publish across platforms instantly
- Analyze performance & audience reach
- Monetize content efficiently
📂 **Source**: [GitHub](https://github.com/yikart/AiToEarn)
📚 **Docs**: [Documentation](https://docs.aitoearn.ai/)
---
**In summary:** Zoomer drives efficiency for AI workloads at scale, and when paired with ecosystems like AiToEarn, that same optimization ethos can extend to **creative AI distribution & monetization worldwide**.