# CapRL: Breakthrough in Dense Image Captioning via Reinforcement Learning
**Date:** 2025-10-28 · **Location:** Sichuan
The **model**, **dataset**, and **QA construction code** from the paper have been **fully open-sourced**.


---
## Authors and Contributions
**Co–first authors:**
- **Xing Long** — Ph.D. student at the University of Science and Technology of China under Professors Lin Dahua and Wu Feng.
*Research interests:* multi-modal LLMs, efficient AI.
- **Dong Xiaoyi** — Postdoctoral researcher at MMLab, The Chinese University of Hong Kong, and part-time research advisor at Shanghai AI Laboratory.
- Published 50+ papers in top-tier conferences (CVPR, ICCV, ECCV).
- Over 10,000 citations on Google Scholar.
---
## About CapRL
### What is CapRL?
**CapRL (Captioning Reinforcement Learning)** successfully applies reinforcement learning from **DeepSeek-R1** to **open-ended visual tasks** like **image captioning**.
- **Innovative Reward Design:** Based on *practical utility*, not subjective judgement.
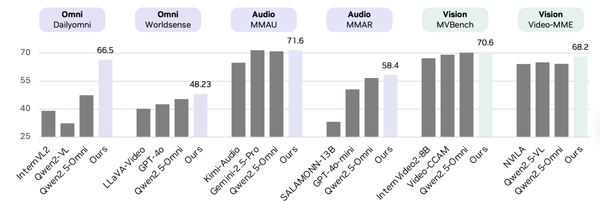
- **Performance:** CapRL-3B matches **Qwen2.5-VL-72B** in captioning quality.
- **Impact:** Demonstrates GRPO strategy applicability to open-domain tasks.
**Downloads:** Hugging Face model & dataset passed **6,000 downloads**; stronger models are in development.

**Links:**
- 📄 [Paper](https://arxiv.org/abs/2509.22647)
- 💻 [Repository](https://github.com/InternLM/CapRL)
- 🔍 [Model](https://huggingface.co/internlm/CapRL-3B)
- 📊 [Dataset](https://huggingface.co/datasets/internlm/CapRL-2M)
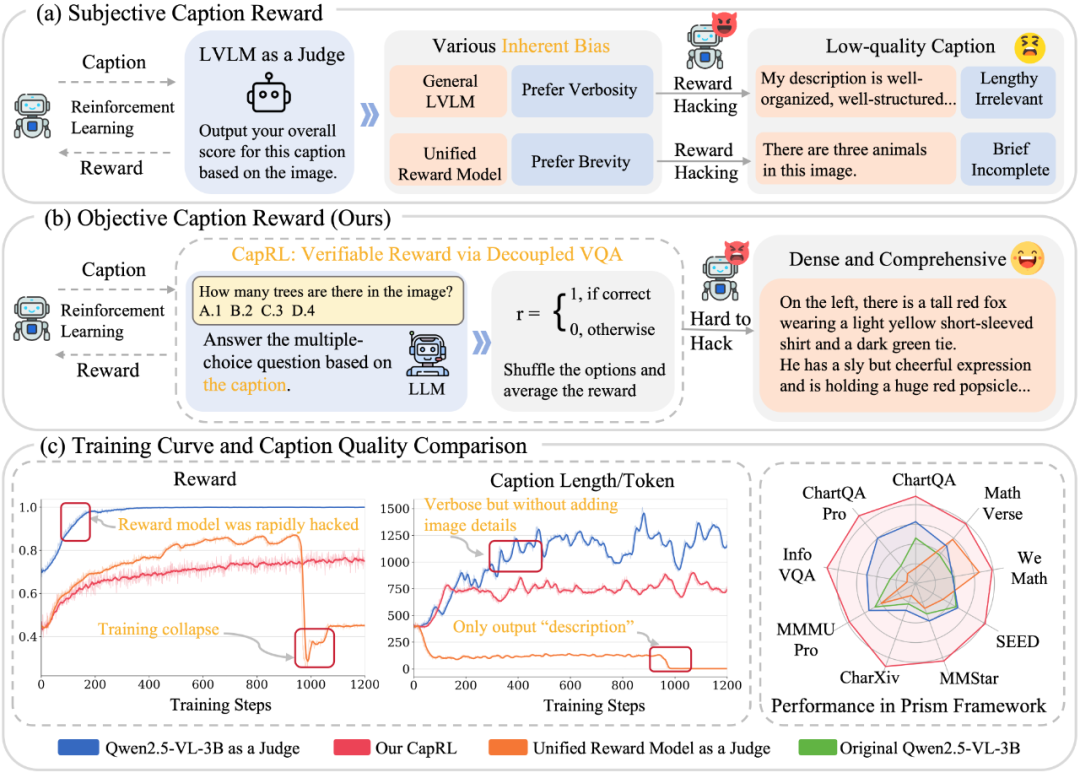
**Figure 1:** CapRL defines **objective and verifiable** rewards based on utility, avoiding reward hacking and improving description quality.
---
## From SFT Captioner to RL Captioner
### The Core Challenge: Reward Design
Image captioning bridges **vision** and **language**, serving as key data for **ViT training** and **LVLM pretraining**.
**Problems with SFT:**
1. **Data Limitations:** Requires costly, human-labeled or proprietary datasets.
2. **Performance Limits:** SFT models memorize rather than generalize, leading to low diversity.
---
## Why RLVR?
**Reinforcement Learning with Verifiable Rewards (RLVR)** works well for tasks with clear ground truth (e.g., detection).
**Challenge:** In open-ended captioning, reward design is subjective — captions differ across annotators.
**Issues with LVLM-as-a-Judge:**
- Susceptible to reward hacking.
- Models may inflate scores by outputting overly long/short captions.
- Results in unstable GRPO training, anomalies, and possible collapse.
---
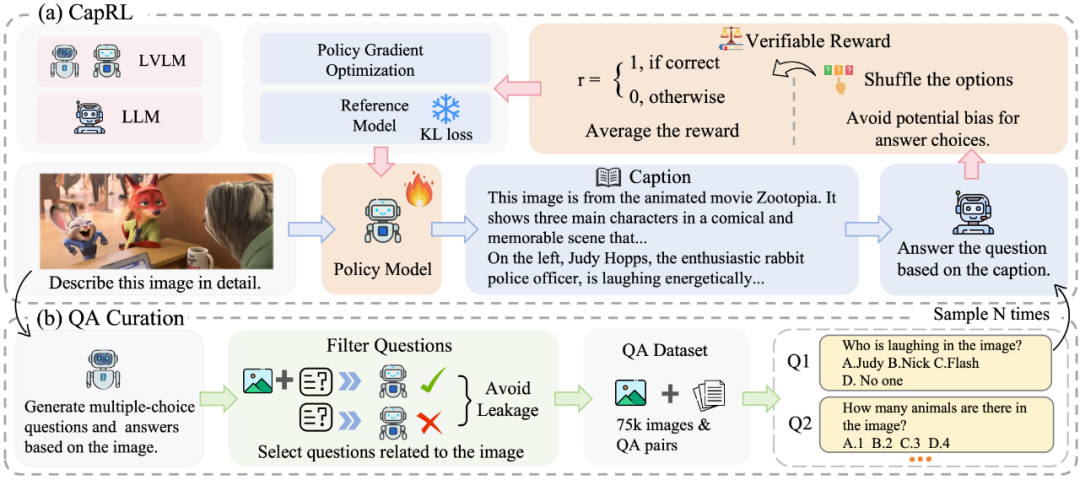
## CapRL Framework
### Overview

**Two-Stage Decoupled Approach:**
1. **Stage 1:** LVLM generates an image caption.
2. **Stage 2:** LLM answers multiple-choice *visual* questions **based only on the caption**.
3. **Reward:** Accuracy of answers = **Objective reward signal**.
---
### New Reward Concept
> **A good caption allows a pure language model to correctly answer visual questions.**
When captions are detailed and accurate, even an LLM without visual input can answer correctly.
**Example:**
Question: *"Who is laughing in the image?"*
Caption: *"Officer Judy the rabbit is laughing heartily"*
Answer: **"Judy"**
---
## Training with CapRL
**Advantages after RLVR fine-tuning:**
- Improved **accuracy** & **detail coverage**
- Reduced **hallucinations**
- Higher utility for downstream tasks
---
## Experimental Results
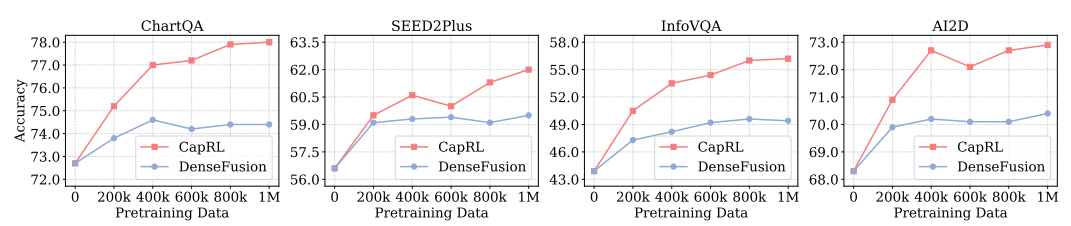
### 1. Dataset Construction & Pretraining
- Built **CapRL-5M** dataset using CapRL-3B annotations.
- Pretraining LVLMs with CapRL datasets beats **ShareGPT4V** and **DenseFusion** on all 12 benchmarks.
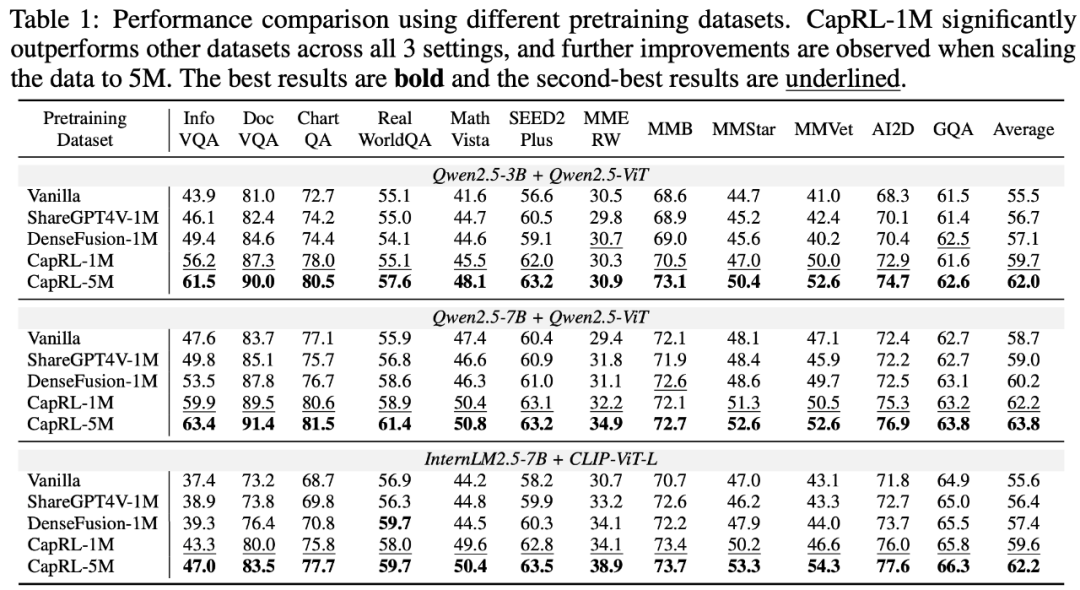
**Figure 4:** Scaling from **1M** to **5M** further boosts performance.
---
### 2. Quality Evaluation
- Evaluated using **Prism Framework**.
- **CapRL-3B** ≈ **Qwen2.5-VL-72B** in caption quality.
- Outperforms baselines by **+8.4%** on average.
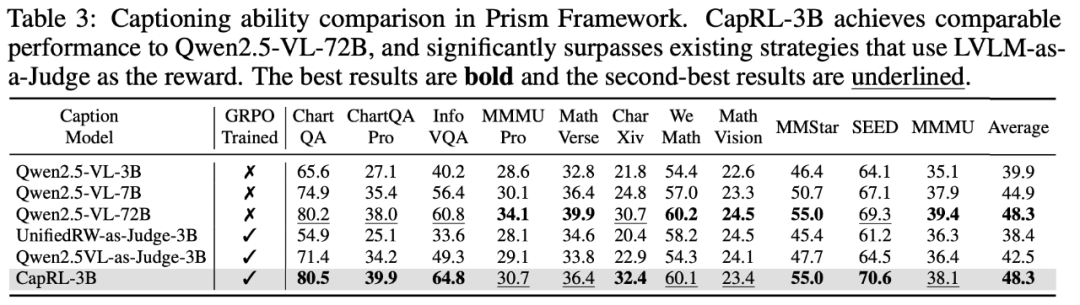
**Figure 5:** Matches 72B models, surpasses LVLM-as-a-judge RL methods.
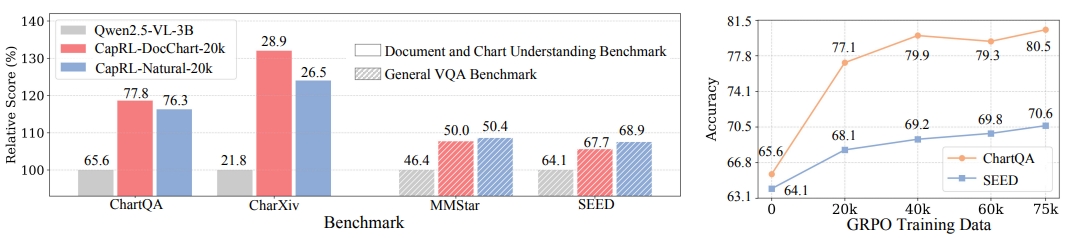
---
## Final Thoughts
CapRL shows **objective reward design** is possible for subjective tasks:
- **Utility-based approach** avoids reward hacking.
- Benefits both **caption quality** and **LVLM training scalability**.
---
## Ecosystem Integration: AiToEarn
Open ecosystems like [AiToEarn](https://aitoearn.ai/) help innovations like CapRL gain traction by:
- Connecting AI generation with **multi-platform publishing**.
- Offering analytics and **model ranking** ([AI模型排名](https://rank.aitoearn.ai)).
- Supporting publication to platforms: Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Instagram, YouTube, X/Twitter, etc.
- Enabling new revenue streams for AI creations.
---
## Additional Resources
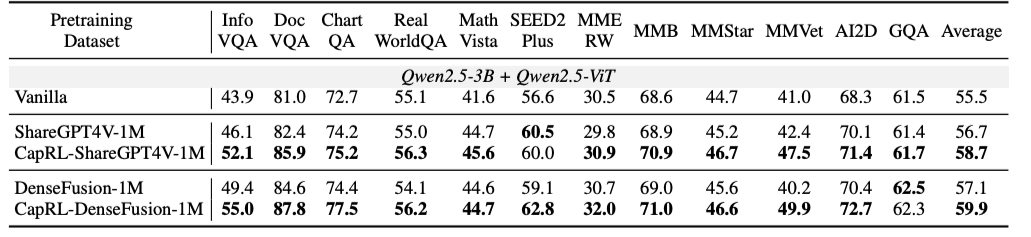

**Figure 6:** Extensive exploratory experiments — see paper for complete settings.
We have open-sourced:
- **Models**
- **Datasets**
- **QA code**

---
**Further Reading:**
[Original Article](2650998286)
[Open in WeChat](https://wechat2rss.bestblogs.dev/link-proxy/?k=d0d3f434&r=1&u=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzA3MzI4MjgzMw%3D%3D%26mid%3D2650998286%26idx%3D4%26sn%3Dc8a7629c2ff9df8c1ec5aa1018ce3a4c)
---
> 💡 **Suggestion:** Provide a **technical pseudocode example** of CapRL’s RLVR reward computation for easier implementation in real training pipelines.