AI Online Reinforcement Learning “Learn While Doing”: Stanford Team Boosts 7B Model to Surpass GPT-4o
AgentFlow: A New Framework for Adaptive, Multi‑Agent Reasoning
Overview
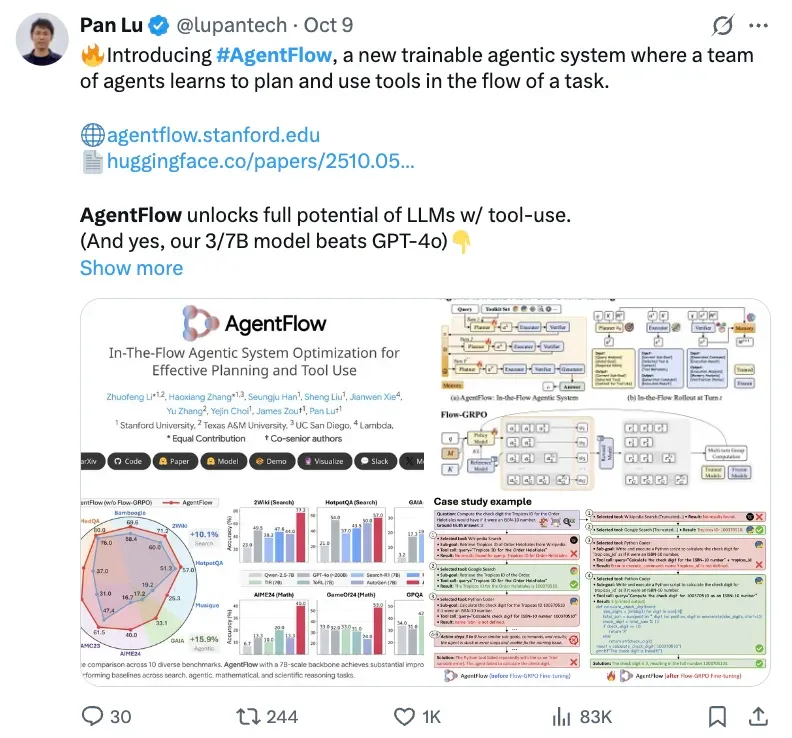
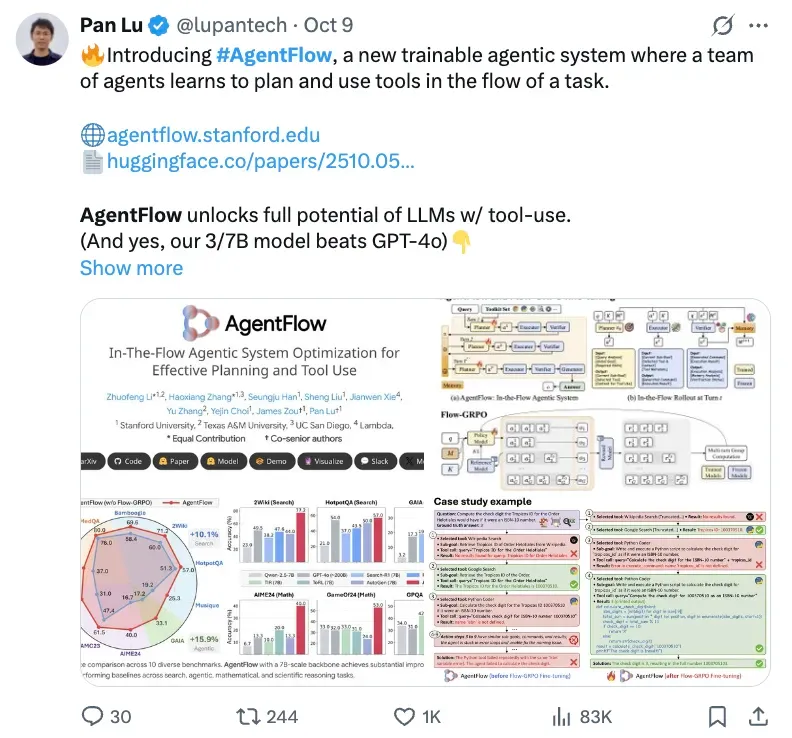
Stanford and collaborators have introduced AgentFlow, a paradigm leveraging online reinforcement learning to help agentic systems "achieve more with less" — in some cases surpassing models like GPT‑4o.
Core Concept:
AgentFlow continuously enhances agents’ reasoning capabilities when tackling complex problems through a collaboration of four specialized agents:
- Planner
- Executor
- Verifier
- Generator
These agents work via shared memory, with the Planner optimized in real time using the novel Flow‑GRPO method.
---
Performance Highlights
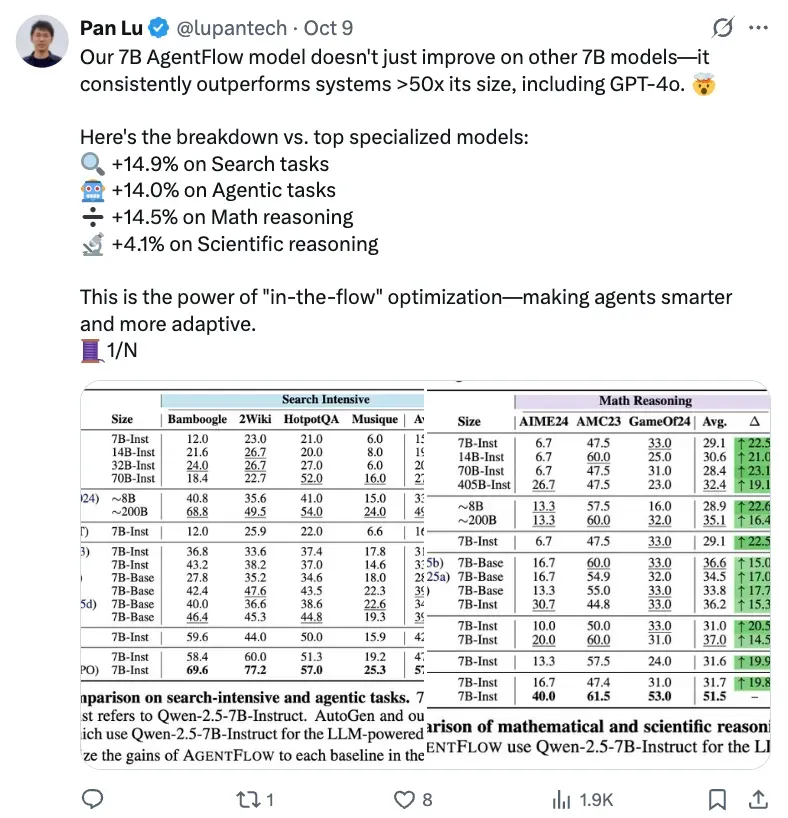
Built on Qwen‑2.5‑7B‑Instruct, AgentFlow achieves notable improvements over existing systems across 10 benchmarks:
- Search tasks: +14.9%
- Agentic tasks: +14.0%
- Math tasks: +14.5%
- Science tasks: +4.1%
It even outperforms much larger models (50× in scale), including GPT‑4o and Llama3.1‑405B.
---
Community Reception
AgentFlow has attracted strong interest:
> “Multi‑agent flow feels like phase‑coupled reasoning. Looking forward to coordination ability replacing scale as the key metric for intelligence.”
> “Flow‑GRPO’s shared‑memory multi‑agent architecture is brilliantly designed. The Verifier’s ability to block hallucinated tool calls reduces error propagation in multi‑step reasoning chains.”

---
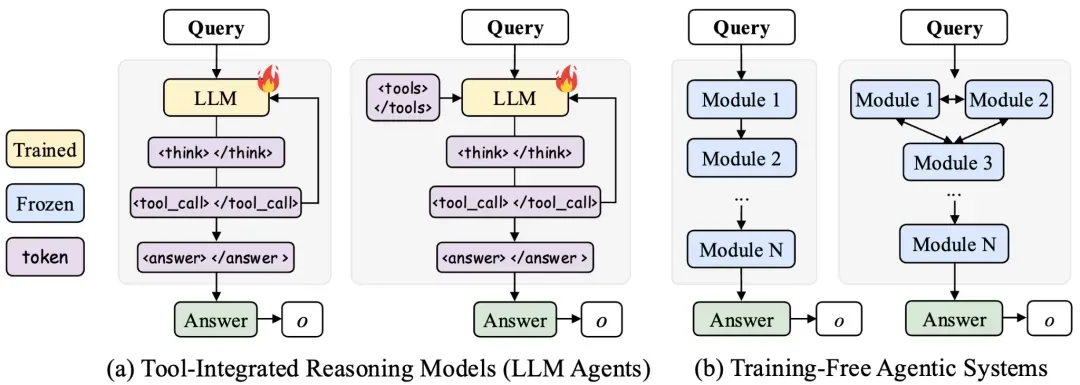
Need for AgentFlow
Agent-based AI systems have expanded rapidly across vertical and general-purpose applications, yet they still struggle with:
- Complex decision-making
- Continuous optimization
Breakthrough: Integrating agent reasoning with reinforcement learning for self-improvement.
Prior work — DeepSeek‑R1, Search‑R1, LangGraph, PydanticAI, OWL — advanced task planning, agent collaboration, and tool integration. AgentFlow builds on these foundations.
---
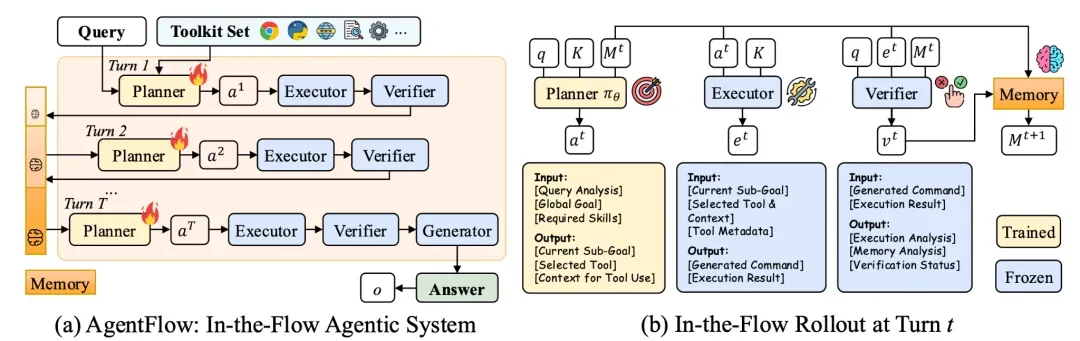
Core Architecture
Four Specialized Agents (with persistent memory):
- Planner – Analyzes tasks, develops strategy, and chooses tools.
- Executor – Executes selected tools and consolidates results.
- Verifier – Validates intermediate outputs against shared memory.
- Generator – Produces final task output.
---
Real‑Time Strategy Adjustment
During each task:
- Planner modifies approach based on environment changes and feedback from other agents.
- Continuous co‑evolution of modules nurtures adaptive reasoning.
- Updates are stored in shared memory for future optimization.
---
AiToEarn Integration Example
Open‑source platforms like AiToEarn官网 complement frameworks like AgentFlow, enabling content creators to:
- Generate AI content
- Publish across multiple channels (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Monitor analytics & model rankings
This ecosystem connects technical innovation with monetization opportunities.
---
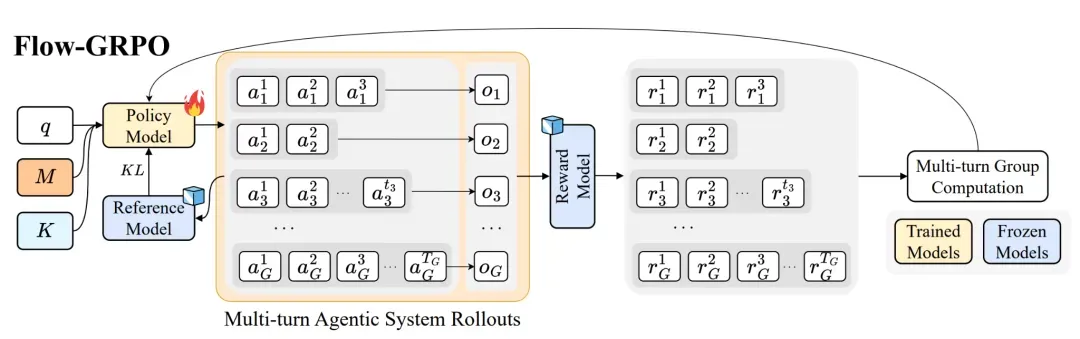
Reinforcement Learning in the Flow
AgentFlow’s novelty: On-policy, real-time optimization of the Planner in the interactive agent workflow.
Workflow Steps:
- Environment perception + memory retrieval
- Action planning + tool selection
- Strategy optimization + shared memory update
---
Flow‑GRPO: Tackling Multi‑Turn RL Challenges
Challenges in agent RL:
- Multi‑turn credit assignment
- Sparse rewards
- Long‑horizon reasoning
Solution:
Flow‑GRPO leverages an action-level multi‑turn optimization objective.
The final reward (success/failure) is broadcast to every step, simplifying training to single-turn policy updates and improving efficiency.
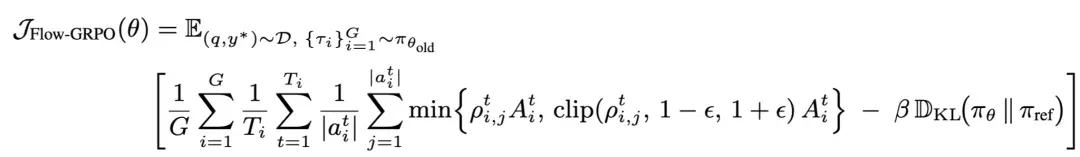
---
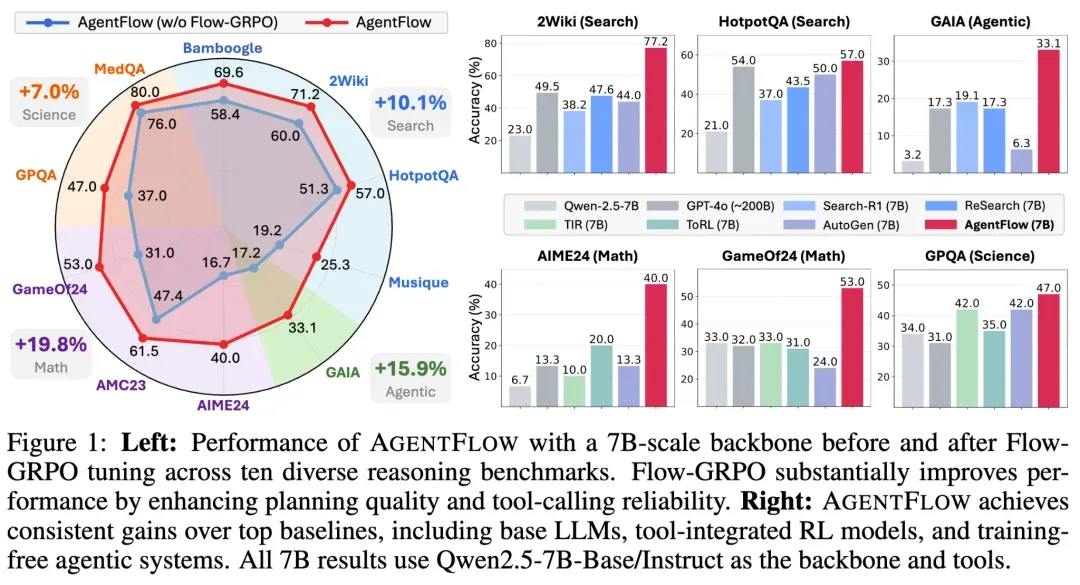
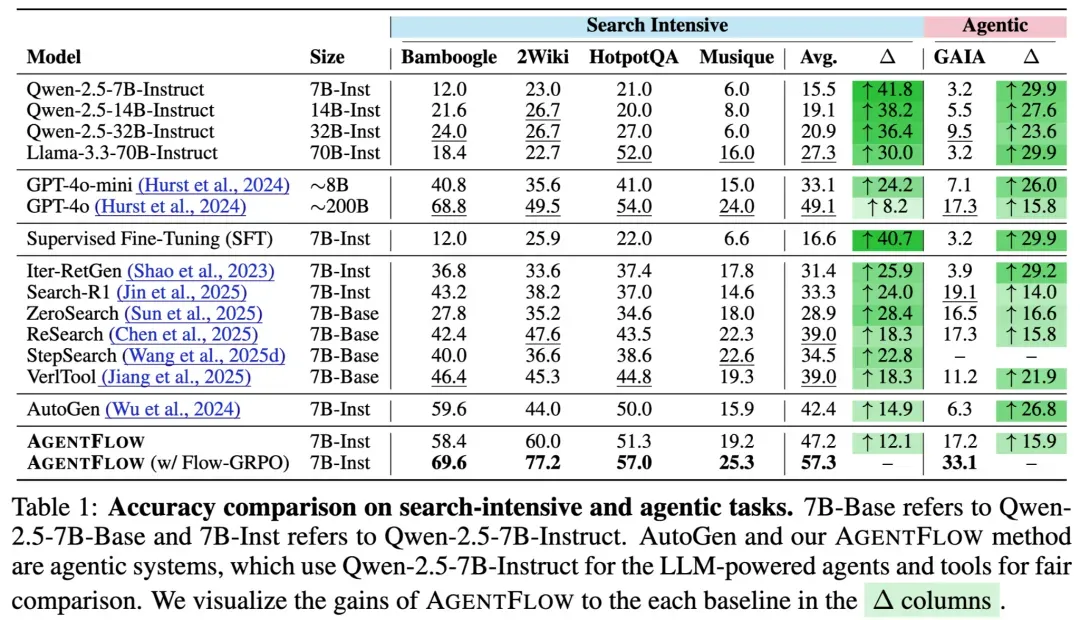
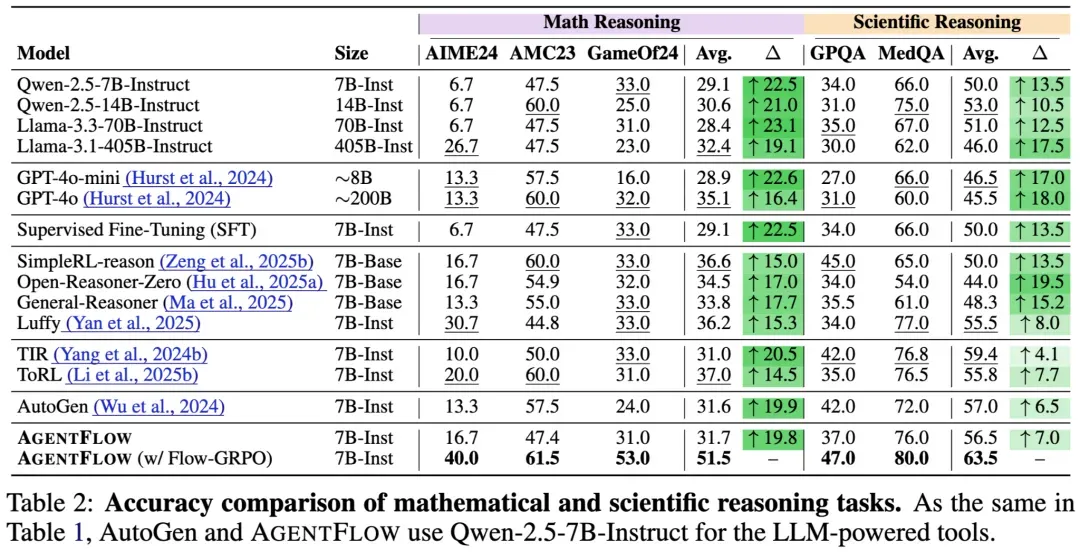
Benchmark Results
AgentFlow was tested across knowledge retrieval, agentic tasks, math reasoning, and science reasoning.
Results:
- Search: +14.9%
- Agentic: +14.0%
- Math: +14.5%
- Science: +4.1%
It even outperforms GPT-4o (~200B) and other large models.
---
Key Insights
1. Model Size ≠ Ultimate Performance
A well‑trained 7B parameter AgentFlow beat GPT‑4o and Llama3.1‑405B in Search (+8.2%) and agentic reasoning (+15.8%).
2. Importance of “Learning in the Flow”
Offline SFT training reduced performance by ~19%.
Online training:
- Corrects tool invocation errors quickly
- Plans precise sub‑tasks
- Enhances overall completion rates
---


---
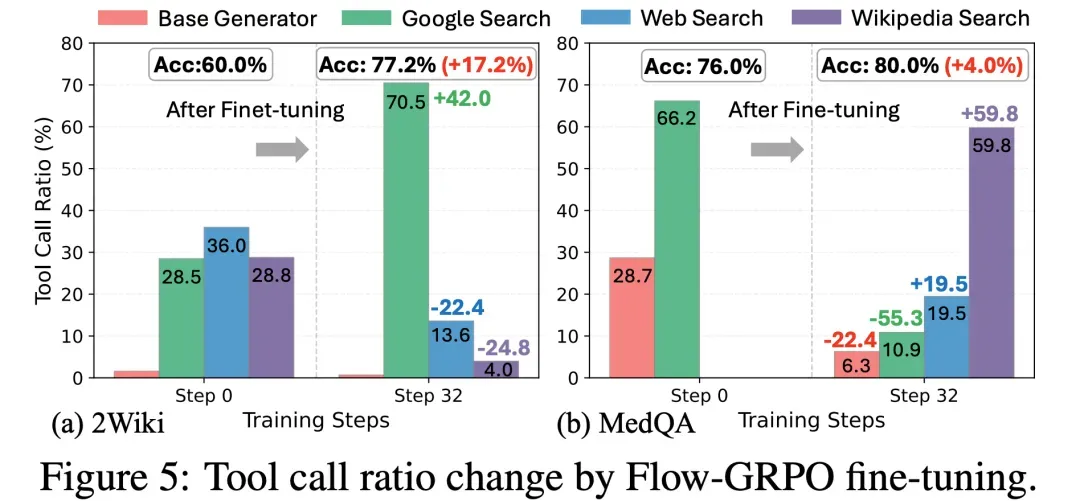
3. Autonomous Tool Path Discovery
Post Flow‑GRPO training:
- Planner learned optimal tool combinations
- Discovered “tool chain” usage (e.g., Wikipedia Search → targeted web search)
- Significantly improved information retrieval depth
---
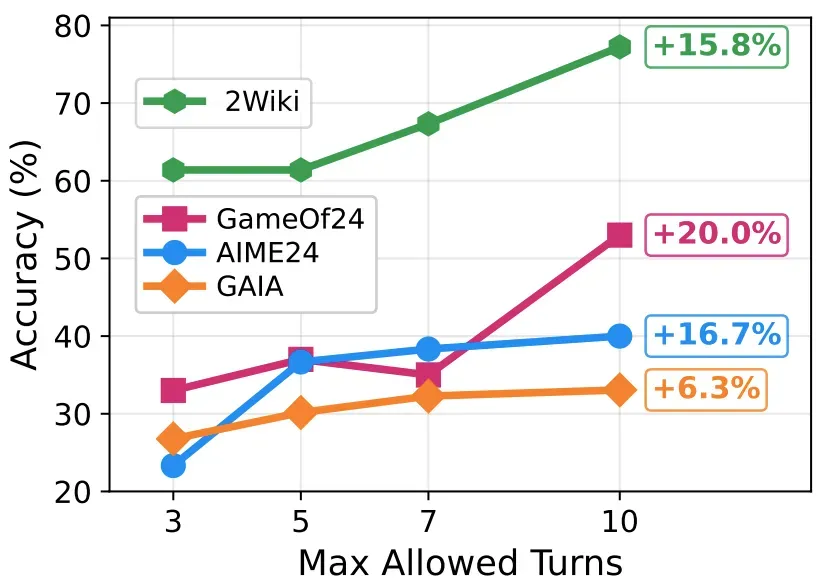
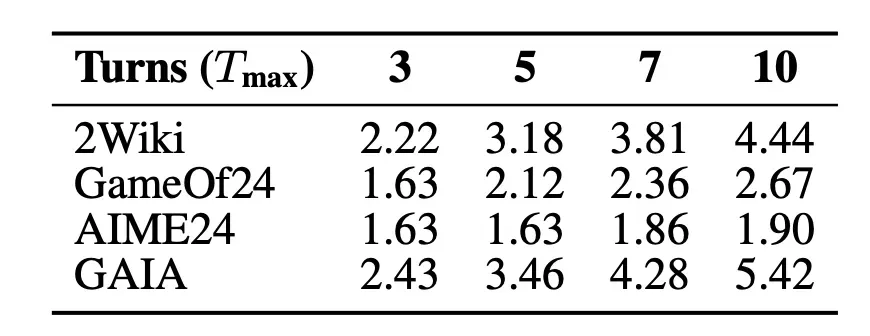
4. Dynamic Reasoning Depth
For complex tasks (e.g., Multihop Search):
- Performance improved with higher step limits without increasing average step count
- Indicates selective deep reasoning only when necessary
---
Conclusion
AgentFlow proposes a shift in agent training strategies:
- Move away from reliance on massive monolithic LLMs
- Enable continuous, adaptive, collaborative learning
- Combine collective intelligence with learning-by-doing for complex task handling
While real-world deployment at scale remains a challenge, AgentFlow’s potential is considerable.
---
Resources
- Paper: https://arxiv.org/abs/2510.05592
- Homepage: https://agentflow.stanford.edu/
- GitHub: https://github.com/lupantech/AgentFlow
- Demo: https://huggingface.co/spaces/AgentFlow/agentflow
- YouTube: https://www.youtube.com/watch?v=kIQbCQIH1SI
---
Cross‑Platform Monetization Opportunity
Platforms like AiToEarn官网 allow creators to:
- Integrate AI agents into content generation workflows
- Publish at scale across global platforms
- Track performance via tools like AiToEarn核心应用 and AI模型排名
This connects AgentFlow’s technical capabilities to creative revenue streams.