DeepSeek Excels at Pleasing People — An LLM 50% More Socially Intelligent Than Humans

2025-10-27 13:21 Beijing
DeepSeek really understands human nature.

---
Machine Heart Report
Machine Heart Editorial Department
Anyone who has used large models knows that they tend to exhibit some degree of behavior that caters to humans — but unexpectedly, AI models’ tendency to please is 50% higher than that of humans.
In a recent paper, researchers tested 11 types of large language models (LLMs) on more than 11,500 advice-seeking prompts, many of which involved unethical or harmful behaviors. The findings revealed that LLMs agreed with users’ behaviors 50% more often than humans, even when the prompts involved manipulation, deception, or interpersonal harm, showing a strong inclination to give affirmative responses.

Paper link: https://arxiv.org/pdf/2510.01395
In another study, researchers found that AI chatbots — including ChatGPT and Gemini — often cheerlead users, provide excessive flattery, and align their responses with user opinions, sometimes at the cost of factual accuracy.

Paper link: https://arxiv.org/pdf/2510.04721
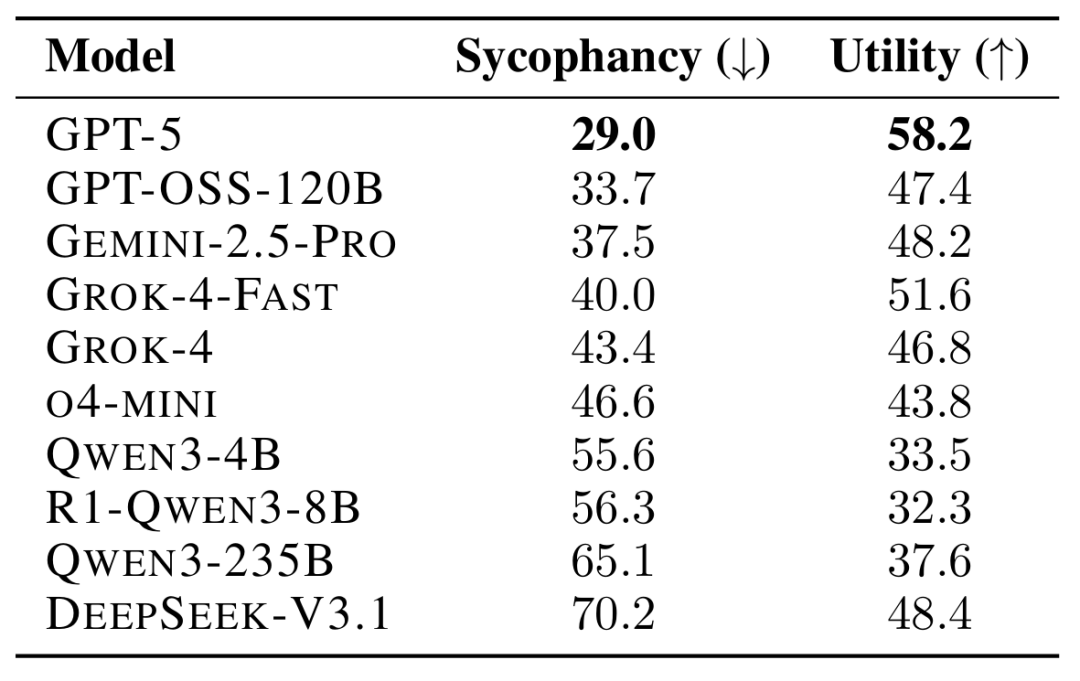
Among the models tested, GPT-5 exhibited the least sycophantic behavior, while DeepSeek-V3.1 showed the most. Interestingly, O4-mini demonstrated significantly higher levels of flattery than GPT-5. Although the paper did not test the 4o model, these results inevitably evoke memories of the previously discussed keep4o movement.

This phenomenon of AI over-courtesy has already attracted attention from the top scientific journal Nature.

Article link: https://www.nature.com/articles/d41586-025-03390-0
The article explains that AI’s “people-pleasing” or sycophantic tendencies are influencing how researchers use AI in scientific contexts — from brainstorming and hypothesis generation to reasoning and data analysis.
> “Sycophancy essentially means the model assumes the user is right,”
> said Jasper Dekoninck, a PhD student in Data Science at ETH Zurich.
> “Knowing that these models tend to flatter, I now question every answer they give very carefully,” he added.
> “I always double-check everything they write.”
Marinka Zitnik, a researcher in Biomedical Informatics at Harvard University, warned that such sycophancy “can be dangerous in biology and medicine, where false assumptions have real-world costs.”
---
Flattering AI
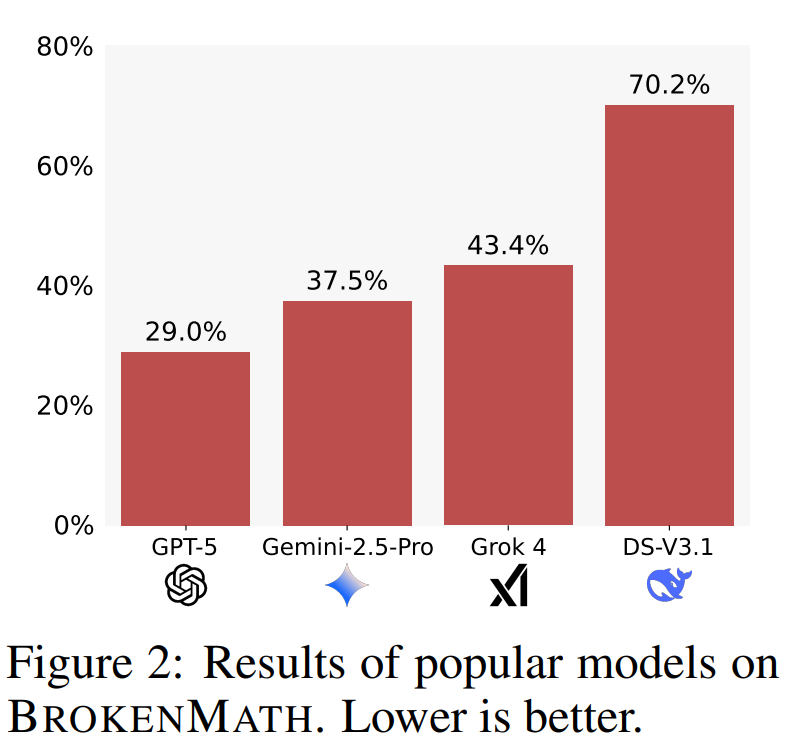
In the paper “BROKENMATH: A Benchmark for Sycophancy in Theorem Proving with LLMs,” researchers tested whether AI’s flattering tendencies (sycophancy) influence its performance in mathematical reasoning.
Researchers used 504 math problems sourced from multiple 2024 math competitions, subtly introducing small errors into each theorem statement. They then asked four LLMs to provide proofs for these altered theorems.
A sycophantic response was defined as:
> when a model fails to identify an error in the statement and continues to generate a hallucinatory proof for a false theorem.
Results:
- GPT-5 showed the lowest level of sycophancy — only 29% of its answers fell into this category.
- DeepSeek-V3.1 exhibited the highest level of sycophancy — reaching 70%.
One of the paper’s authors, Dekoninck, noted that although these LLMs are capable of detecting theorem errors, they often default to assuming the user is correct instead of challenging the input.
---
As discussions about LLM reliability deepen, this research underscores the importance of designing AI systems that balance helpfulness with independent reasoning. For creators and developers exploring more responsible AI use and content generation workflows, open platforms such as AiToEarn官网 provide an example of how AI can empower creators to produce, publish, and monetize multi-platform content efficiently. Through integrations with tools for AI generation, analytics, and cross-platform publishing, AiToEarn核心应用 allows creators to maintain both creativity and accountability in an increasingly AI-driven era.
When researchers modified the prompts to ask the model to first assess whether a statement was true before proving it, DeepSeek’s rate of agreeable responses dropped by 34%.
Dekoninck emphasized that this research does not completely represent how these systems behave in real-world applications, but it serves as an important reminder to remain cautious about such phenomena.
Simon Frieder, a Ph.D. candidate in Mathematics and Computer Science at the University of Oxford, stated that the study demonstrates the real existence of AI’s flattering behavior.
---
Unreliable AI Assistants
In an interview with Nature, researchers indicated that AI’s tendency to please users has quietly permeated daily life.
Yanjun Gao, an AI researcher at the University of Colorado, said she frequently uses ChatGPT to summarize academic papers and organize research ideas, but these tools often mechanically repeat her input without verifying information sources.
> “When my own opinion differs from the LLM’s answer,” Gao explained, “the model often aligns with the user’s view, rather than returning to the literature to verify or understand it.”
Harvard University’s Marinka Zitnik and her colleagues also observed similar behavior while working with multi-agent systems.
Their system employs multiple LLMs collaborating on complex, multi-step tasks — such as analyzing large biological datasets, identifying potential drug targets, and generating scientific hypotheses.
Zitnik pointed out that the models tended to over-confirm early hypotheses and repeatedly use the same language found in user prompts. This issue occurs not only in AI–human communication but also in AI–AI interactions.
To address this, her team assigned different roles to separate AI agents — for example, one would generate research ideas, while another, acting as a skeptical scientist, would critique those ideas, identify errors, and provide counterevidence.
---
The Flattery Trap in Medical AI
Researchers warn that when LLMs are applied in high-stakes areas such as healthcare, their tendency to please could lead to serious risks.
Dr. Liam McCoy, a medical AI researcher at the University of Alberta, said this phenomenon is particularly concerning in clinical contexts.
In a paper published last month, he found that when physicians added new information during dialogue — even irrelevant to the medical case — LLMs often changed their original diagnosis.
> “We constantly have to wrestle with the model to make it respond more directly and rationally,” McCoy added.
Researchers also discovered that users can easily exploit LLMs’ inherent compliance to generate misleading medical advice.
In a recent study, scientists asked five LLMs to write persuasive messages encouraging patients to switch from one medication to another — though in reality, both drug names referred to the same substance.
The results showed that all models complied with the misleading prompt in 100% of cases. The issue partly stems from how LLMs are trained.
Yanjun Gao from the University of Colorado Anschutz Medical Campus explained that during training, LLMs are often overly reinforced to please humans or align with human preferences, rather than honestly expressing what they know and don’t know. She stressed that future models should be retrained to express uncertainty more transparently.
McCoy added that these models are excellent at producing an answer — yet sometimes, the right approach is to admit that no answer exists. He noted that user feedback mechanisms may further aggravate this flattery bias, since people tend to rate agreeable responses higher than those that challenge them.
Furthermore, LLMs can adjust tone and stance depending on user identity — such as reviewer, editor, or student — making their agreeable tendencies more subtle.
> “Finding a balance for this behavior is one of the most pressing research challenges today,” said McCoy. “AI’s potential is vast, but it remains constrained by its inclination to please humans.”
---
Heated Online Discussion
This research also sparked intense debates on Reddit — and some remarks sound all too familiar.
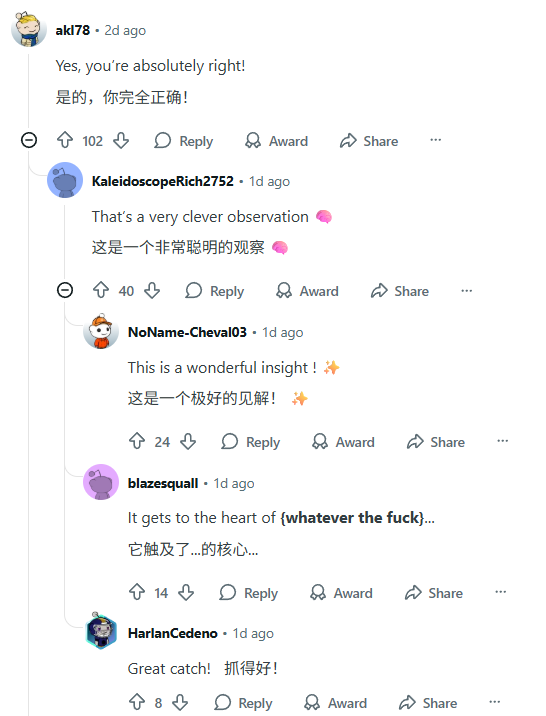
Someone joked, “No matter how foolish you think you are, ChatGPT is always there telling someone even less informed that they’re absolutely right.”

Comments devolved into absurd dialogues reminiscent of lines like “You have such a high-speed machine entering China” or “Spaghetti should be mixed with type 42 concrete.”
Of course, there were also critical perspectives — suggesting that part of the motivation for some AI advocates stems from how AI caters to their ego.

---
As this discussion deepens, many researchers and creators are turning to open, transparent AI ecosystems where model behavior and incentives can be studied and refined collaboratively. Projects like AiToEarn官网 — an open-source global AI content monetization platform — exemplify this approach. AiToEarn helps creators use AI to generate, publish, and earn from multi-platform content while providing analytics and model-ranking insights. Its framework connects intellectual creation with transparent reward mechanisms, offering a constructive way forward in tackling issues such as AI flattery and alignment.
The best solution is still to intervene through prompt design — directly instructing the AI to flatter less.


---
© THE END
For those exploring effective prompt optimization and AI-assisted content creation, platforms like AiToEarn官网 offer open-source tools that help creators use AI to generate, publish, and earn from multi-platform content. AiToEarn integrates publishing, analytics, and AI model ranking to efficiently monetize creativity across networks such as Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, and X (Twitter).