DeepSeek-V3.2 Acceleration Technology Explained: The Secret Behind Its Amazing Performance
DeepSeek-V3.2: Inference Speed Optimization with Sparse Attention

---
📑 Table of Contents
- Starting from DeepSeek-V3
- DeepSeek's Sparse Attention Concept
- Deep Dive into V3.2’s DSA
- Training Process
- The Astonishing Results
- Summary & Limitations
---
DeepSeek has kept its tradition of surprising developers right before major holidays. Just before the National Day break, the team released the DeepSeek-V3.2 report — only six pages, with few but impactful optimizations. I resisted the urge to post before the holiday, letting the technology "settle" alongside Tencent’s Mid-Autumn mooncakes. Here’s my post-holiday review.
📢 Live Tencent Cloud Q&A — 10/23 at 7:30 PM!
Follow Tencent Cloud Developers for early insight 👇
---
1. Starting from DeepSeek-V3
1.1 MOE: DeepSeekMoE
- Originated in DeepSeek V2 under DeepSeekMoE: Training Strong Models at Economical Costs. (Read paper)
- Innovation: uses permanently active shared experts in addition to token-based expert routing.
- Benefits: resolves Expert Specialization imbalance, improves balance without heavy theoretical complexity.
- V3 improvement: Auxiliary Loss-Free Load Balancing → reduced bias from skewed specialization.
---
1.2 MLA: Multi-Head Latent Attention
- First introduced in V2; compresses Q, K, V in Multi-Head Attention, similar in spirit to LoRA.
- Process:
- Input \( h_t \) → compressed into low-dimensional ckv vector.
- K and V reconstructed from ckv via up-projection matrices.
- Only ckv is cached → reduces memory transfer overhead.
DeepSeek claims: Matrix multiply is much faster than GPU memory access (~1:100 speedup). FP8 precision maintained without loss, thanks to smaller compression matrices aiding convergence.
---
1.3 MTP: Multi-Token Prediction
- New in V3 → doubled inference speed compared to V2.
- Predicts multiple tokens per step (ideally 4, V3 uses 2 for accuracy).
- Difference from look-ahead: MTP trains on multi-token loss from the start, rather than only predicting ahead at inference.
---
1.4 FP8 Mixed Precision
- Some BF16 parameters converted to FP8 (model weights & inputs).
- Intermediate results in BF16; gradients & optimizer in FP32.
- Gains: Smaller precision drop, reduced compute/memory load, stable training with FP8.

---
2. DeepSeek’s Sparse Attention Concept
V3.2 focuses entirely on inference speed — near-lossless optimization with no training speed or accuracy improvement.
Earlier this year, DeepSeek introduced Native Sparse Attention. Its design included three parallel attention branches combined via a gated output, shown below:
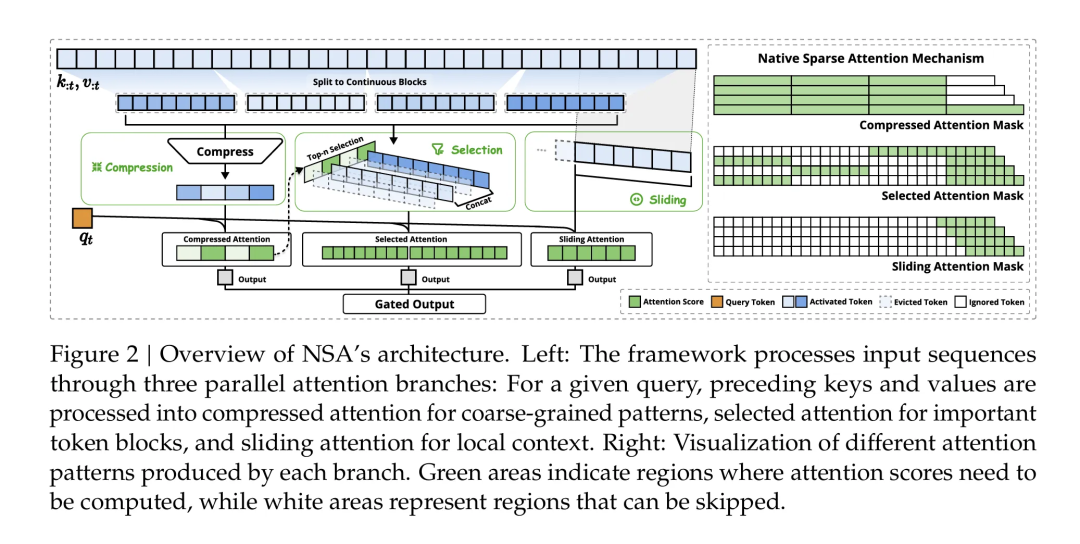
The Three Branches
- Compressed Attention (MLA)
- Compresses KV at storage; restores only when needed. Trained sparsity = Natively Trainable Sparse Attention.
- Selected Attention for Important Tokens
- Focuses attention computation on the most relevant tokens.
- MLA + this branch = V3.2’s DSA (DeepSeek Sparse Attention).
- Sliding Attention for Local Context
- Windowed attention similar to LONGNET or SWA (2023). Not yet integrated in V3.2.
---
3. Deep Dive into V3.2’s DSA
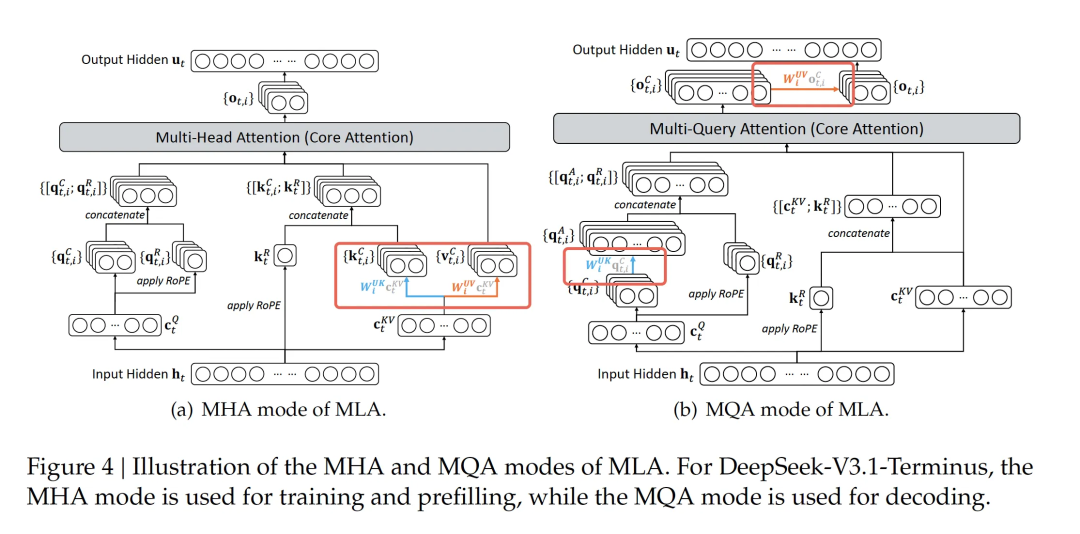
DSA = MLA (adapted) + Selected Important Tokens, with MLA switched from MHA to MQA.
---
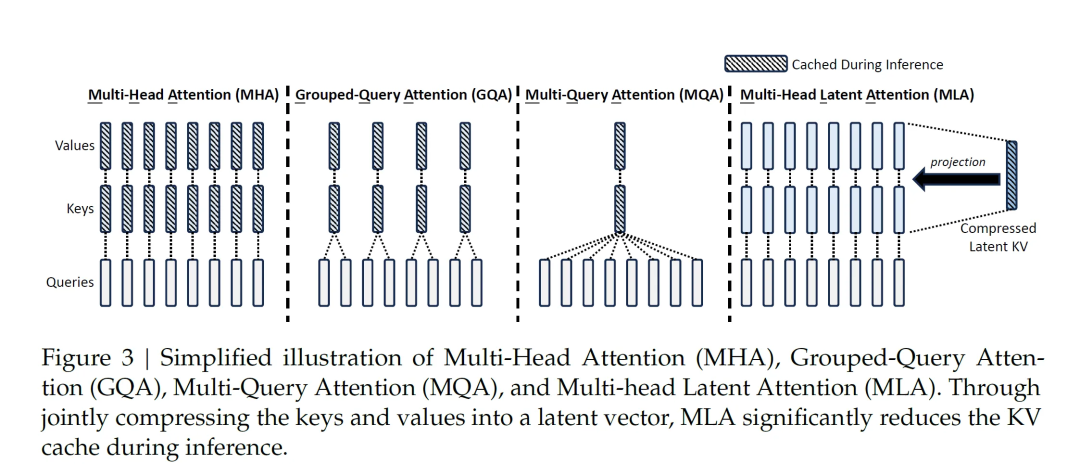
3.1 MHA-based MLA vs MQA-based MLA
In MQA, all heads share one KV set — criticized for information loss.
V3 MLA also shared KV after compression, then restored fully.
V3.2 change:
- No longer fully decompress KV before computation.
- Computes attention on compressed/intermediate KV; restores Value only at the end.
- Saves significant compute, behaves closer to MQA.
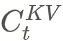
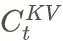
---
3.2 Lightning Indexer & Fine-Grained Token Selection
- Lightning indexer: Computes query-weight against all previous tokens to score importance.
- Selection: Top-K tokens chosen (K=2048); others set to value=0.

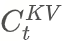
---
4. Training Process
Key reminder: This is an inference optimization — model performance is unchanged.
Steps:
- Start from trained V3.1.
- Modify architecture → dense version training (no token selection yet).
- Pretrain lightning indexer:
- LR = `1e-3`
- 2.1B tokens
- Enable Top-K selection (K=2048), reduce LR to `7.3e-6`.
- Train with 943.7B tokens.
- Repeat all V3.1 post-training steps for V3.2.
---
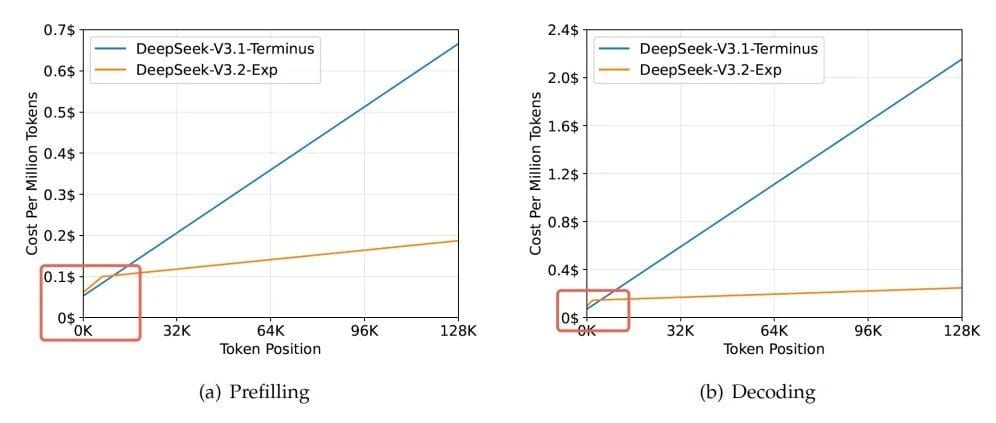
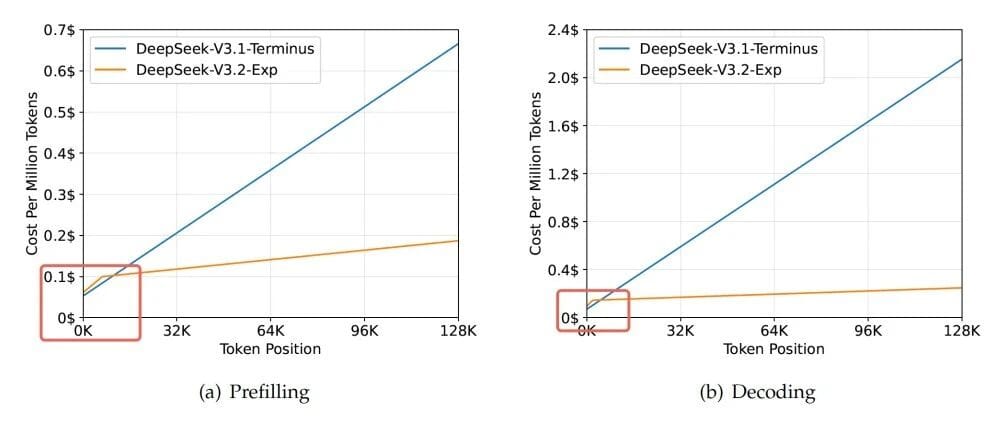
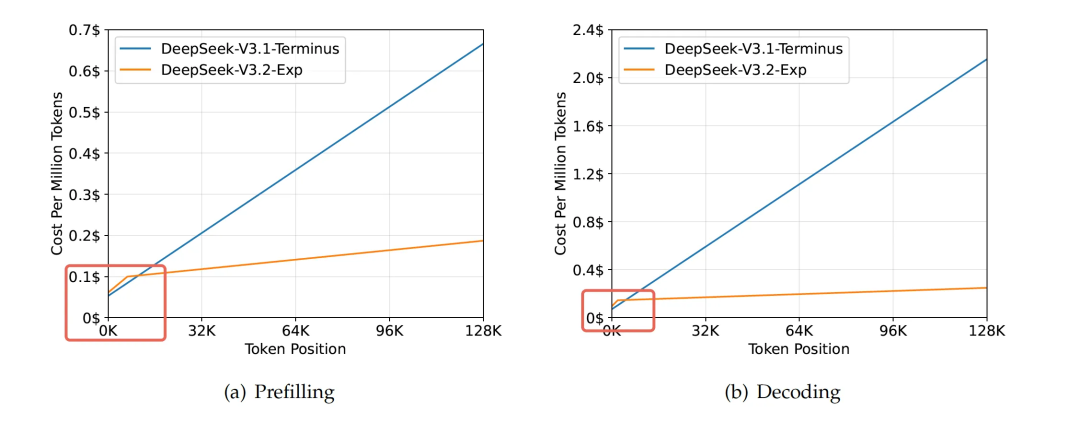
5. Astonishing Results
- Speed gain increases with longer context.
- Below 2K tokens: original faster; above → huge slope drop.
Complexity drop:
From

to
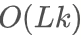
- Quadratic → linear complexity.
- Huge memory relief for limited GPUs.
---
6. Summary & Speculative Limitations
What it does:
- Removes most low-importance historical tokens from attention computation.
- Requires extra CPT & post-training → inference speed gains only.
Potential risk:
- Benchmarks used same corpus and post-training as V3.1.
- Missing evaluation in domains neither model was trained heavily on.
If SWA (Sliding Window Attention) merges with DSA, acceleration may climb further — though complexity will be much higher.
---
📌 Closing Thoughts
Sparse attention like DSA is part of a broader AI trend toward efficient compute usage. For those creating AI-driven content, platforms like AiToEarn allow automatic multi-platform publishing (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X) — integrating generation, publishing, analytics, and model ranking in one ecosystem.

---
💬 Discussion:
Have you tried DeepSeek-V3.2? Is the speedup noticeable?
Comment below — best comment wins a Tencent Cloud custom file bag set announced Oct 21, 12:00 PM.






---