Flexing Muscles While Building Walls: NVIDIA Launches OmniVinci, Outperforms Qwen2.5-Omni but Faces “Fake Open Source” Criticism
NVIDIA OmniVinci: A Breakthrough in Multimodal AI
NVIDIA has unveiled OmniVinci, a large language model designed for multimodal understanding and reasoning — capable of processing text, visual, audio, and even robotic data inputs.
Led by the NVIDIA Research team, the project explores human-like perception: integrating and interpreting information across multiple data types.
---
Core Architecture & Innovations
OmniVinci blends architectural innovation with a large-scale synthetic data pipeline. According to the research paper, the model features three key components:
- OmniAlignNet — Aligns visual and audio embeddings into a shared latent space.
- Temporal Embedding Grouping — Captures dynamic relationships between video and audio signals over time.
- Constrained Rotary Time Embedding — Encodes absolute time information, enabling synchronization across multimodal inputs.
---
Synthetic Data Engine
To support training, the team built a data synthesis engine that produced 24+ million single- and multi-modal dialogues.
This training covered 0.2 trillion tokens — just one-sixth of Qwen2.5-Omni’s usage — yet achieved superior benchmark results.
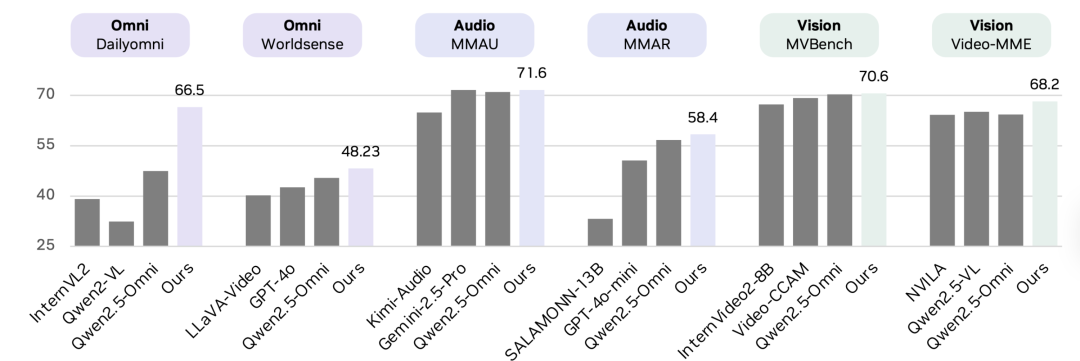
Performance Gains:
- +19.05 on cross-modal understanding (DailyOmni)
- +1.7 on audio (MMAR)
- +3.9 on visual (Video-MME)
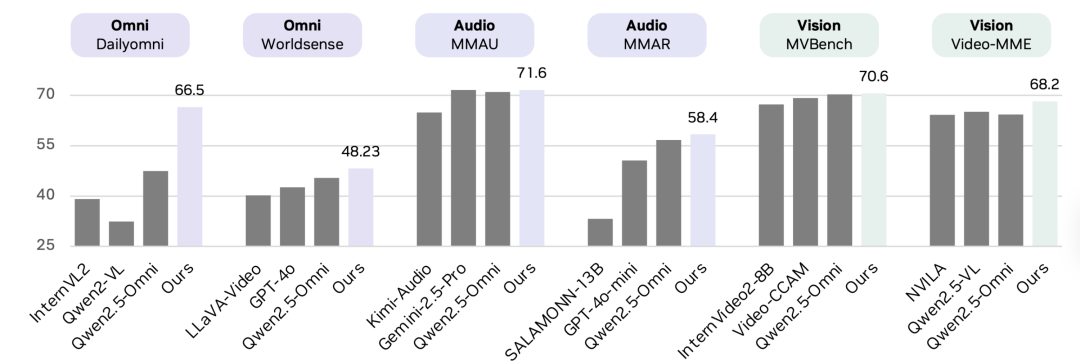
Benchmark source:
https://huggingface.co/nvidia/omnivinci
---
Why It Matters
NVIDIA researchers emphasize that modalities reinforce each other: combining visual and auditory inputs boosts perception and reasoning abilities.
Early experiments show promise in:
- Robotics
- Medical imaging
- Smart factory automation
These domains could benefit from higher decision accuracy and lower response latency with multimodal AI.
---
Licensing Controversy
Although described as an open-source release, OmniVinci is actually under NVIDIA’s OneWay Noncommercial License, which prohibits commercial use.
This restriction has sparked debate:
> Julià Agramunt (LinkedIn): “Releasing a ‘research-only’ model while locking up commercial rights isn’t open source. It’s ‘profit wrapped in a generosity façade.’”
> Reddit user: “I just wanted to check their benchmark results and got stuck in their ‘user review’ process — it’s absurd.”
---
How to Access & Deploy
For approved researchers, NVIDIA offers:
- Deployment scripts via Hugging Face
- Examples for inference on video, audio, and image data
- Built on NVILA multimodal infrastructure
- Full GPU acceleration for real-time applications
---
Related Link
Original article:
https://www.infoq.com/news/2025/10/nvidia-omnivinci/
---
Broader Context: Monetizing Multimodal AI
In the growing field of multimodal AI, tools that integrate generation, publishing, and monetization are becoming essential — especially for independent creators and developers.
One example is AiToEarn官网, an open-source platform that helps creators:
- Produce AI-generated content
- Publish across major platforms (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Analyze performance metrics
- Rank models via AI模型排名
By uniting AI generation, cross-platform publishing, analytics, and model rankings, AiToEarn streamlines the process of turning AI creativity — including projects like OmniVinci — into sustainable revenue.


