HKUST Proposes New Algorithm to Revolutionize LLM Reasoning: Random Strategy Evaluation Emerges as a Breakthrough in Mathematical Reasoning
2025-10-31 · Beijing
“Simplify, Don’t Complicate” — The Real Key to Advancing Performance


Authors & Affiliations
- He Haoran — PhD student at The Hong Kong University of Science and Technology (HKUST), specializing in reinforcement learning and foundation models.
- Ye Yuxiao — First-year PhD student at HKUST (Co-first author).
- Pan Ling — Assistant Professor, Department of Electronic and Computer Engineering & Department of Computer Science and Engineering, HKUST (Corresponding author).
---
Background: Reinforcement Learning in LLM Reasoning
In large language models (LLMs), Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key strategy for improving mathematical reasoning.
However, mainstream approaches—such as PPO and GRPO—are based on policy gradient updates within a policy iteration framework:
- Policy evaluation: Assessing current policy performance.
- Policy improvement: Iterative refinement via optimization.
Problem: These methods often bring unstable training, loss of diversity, and complex tuning requirements.
---
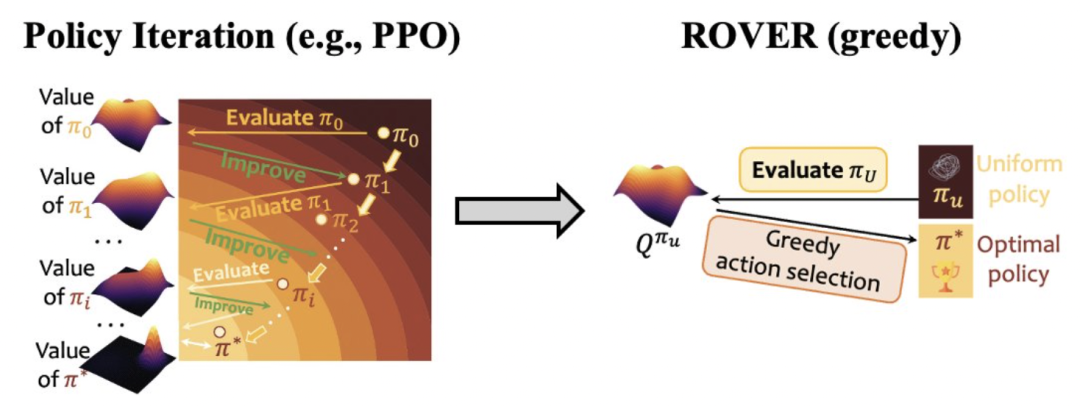
A Radical Proposal: ROVER
A collaborative team from HKUST, Step (Jieyue), and Kwai presents ROVER
(Random Policy Valuation for Diverse Reasoning), an ultra-minimalist method that skips the policy improvement loop entirely.
- Core idea: Evaluating the value of a completely random policy can be enough to find an optimal reasoning path.
- Impact:
- Outperforms existing methods on multiple benchmarks.
- Maintains high quality and diversity.
- Eliminates extra networks or reference models—lighter and more efficient.
Resources:

---
The Pain Points of Traditional RL
Mainstream methods (PPO, GRPO) operate under Generalized Policy Iteration (GPI):
Iterative Steps
- Policy evaluation: Compute advantage function or value estimates.
- Policy improvement: Update policy based on optimization rules.
Key Problems
- Poor stability: Non-stationary targets cause collapses; fixes like KL regularization or entropy monitoring add fragility.
- Heavy infrastructure: Extra value networks or reference models increase compute cost.
- Reduced diversity: Models overfit to single-step correctness, hurting exploration and pass@k performance.
---
ROVER’s Radical Simplicity
Theoretical Insight
LLM reasoning tasks can often be modeled as finite-horizon, tree-structured MDPs with:
- Deterministic transitions.
- Single parent per state.
- Binary sparse rewards (Correct / Incorrect).
Finding:
In such MDPs, Q-values from a uniform random policy naturally indicate the optimal policy.
Proof intuition:
If an action leads to a subtree with a correct solution, its Q-value > 0.
Greedy selection on Q-values guarantees optimal paths.
---
ROVER Workflow: Three Minimal Steps
1. Q-value Estimation
Use a generalized Bellman equation under a uniform random policy:
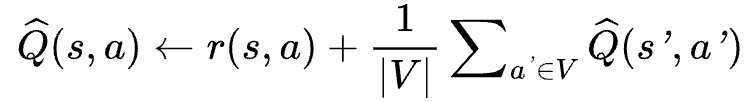
2. Policy Construction
- Greedy choice is optimal but can reduce diversity.
- ROVER applies softmax sampling over Q-values:
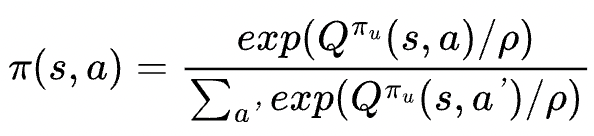
- Temperature parameter tunes exploration.
3. Training Objectives
- No separate value network: Embed value function within LLM parameters.
- Group reward centralization: Reduces variance for stable Q-value learning.
Loss Function:
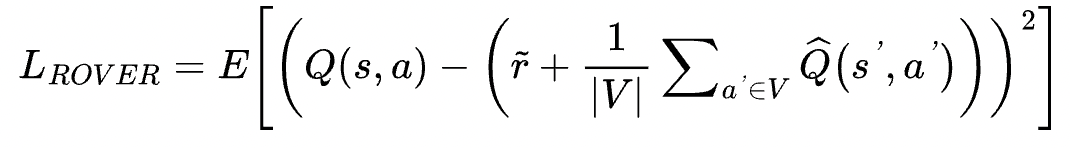
---
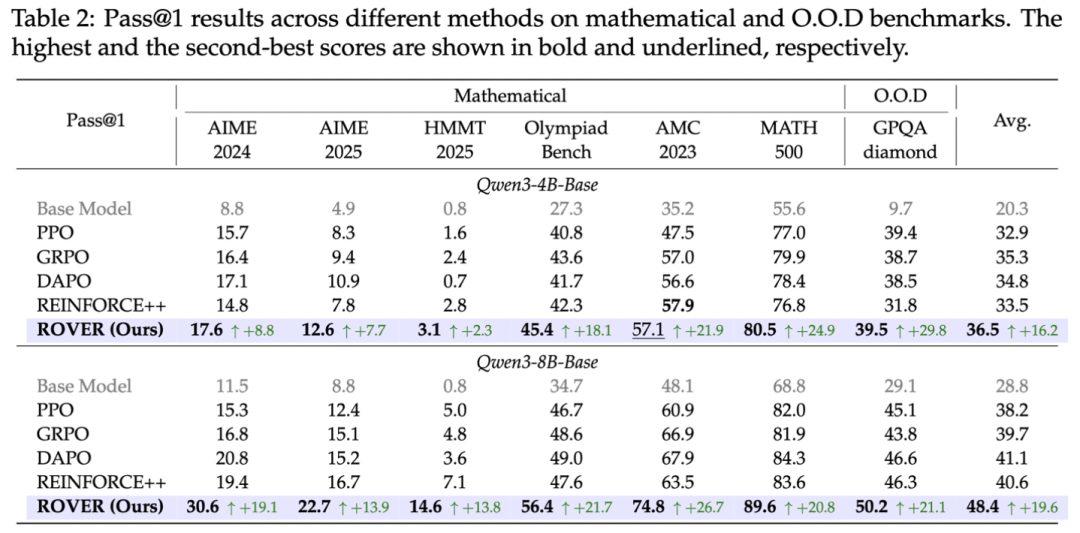
Experimental Results
Benchmarks
ROVER evaluated on AIME24/25, HMMT25, AMC, MATH, Countdown, and GPQA-diamond.
Highlights:
- AIME24 pass@1: 30.6 — +19.1 over baseline.
- HMMT25 pass@1: 14.6 — 106% gain over best baseline.
---
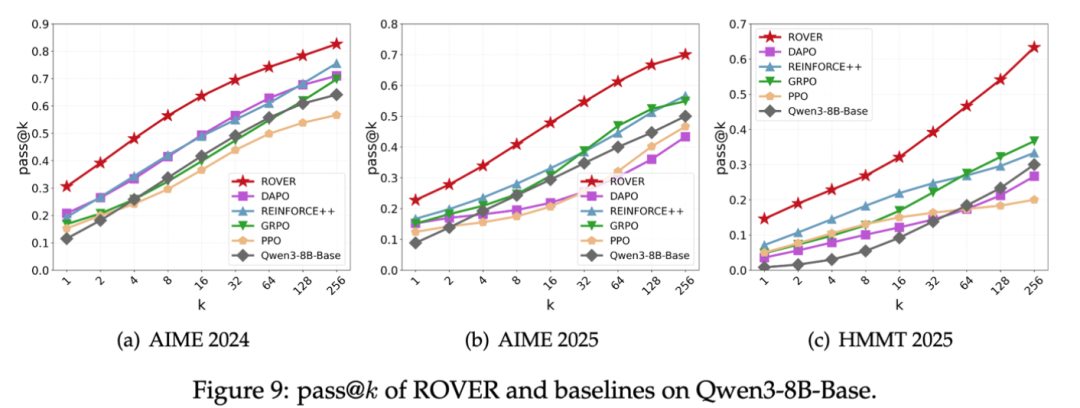
Sustained Exploration
Unlike PPO/GRPO which plateau quickly in pass@k, ROVER retains strong improvement even at pass@256.
---
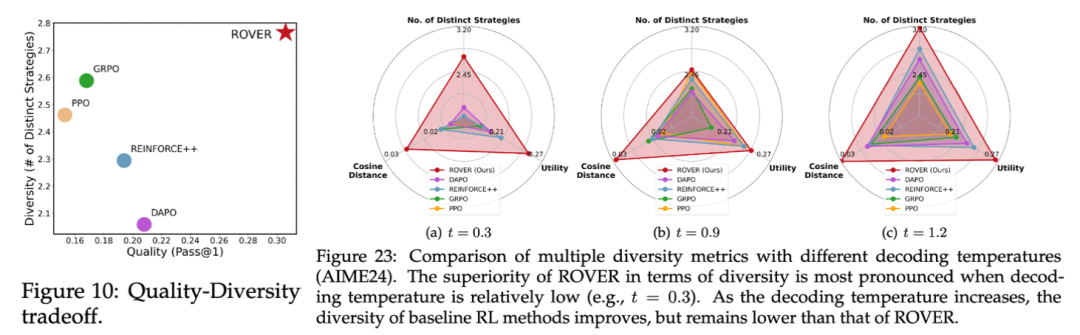
Diversity Gains
- +17.6% average strategy diversity over baseline.
- Excels in cosine distance & utility measures.
- Improved O.O.D. task performance (GPQA-diamond).
---
Case Study: More Solution Paths
Example: 2×3 grid arrangement problem.
- Base & GRPO: 2 strategies.
- ROVER: 4 strategies — including novel methods such as bar method and inclusion–exclusion principle.

---
Broader Impact & Outlook
Key message: In structured reasoning tasks — simplify rather than complicate.
> Simplicity is the ultimate sophistication. — Da Vinci
ROVER embodies this principle, offering:
- Lower computational load.
- Higher diversity.
- Robust performance.
For scaling such models in practice, open-source AI platforms like AiToEarn provide:
- AI content generation.
- Cross-platform publishing.
- Analytics & model ranking (AI模型排名).
---

Read More: