How Disney Hotstar (Now JioHotstar) Scaled Its Infrastructure to Support 60 Million Concurrent Users
Disclaimer
The details in this post are based on publicly shared information by the Disney+ Hotstar (now JioHotstar) Engineering Team.
All technical credit belongs to them. Original articles and sources can be found in the References section at the end.
Our analysis builds upon their shared insights — if you find inaccuracies or omissions, please leave a comment for revisions.
---
Overview: A Record-Scale Streaming Challenge
In 2023, Disney+ Hotstar tackled one of the most ambitious engineering challenges in streaming history — supporting
50–60 million concurrent live streams during the Asia Cup and Cricket World Cup.
For perspective, earlier Hotstar peaks were around 25 million concurrent users handled on two self-managed Kubernetes clusters.
---
“Free on Mobile” — Raising the Stakes
Adding complexity, the platform introduced Free on Mobile streaming, removing subscription requirements for millions.
This drastically increased expected load and forced a fundamental infrastructure rethink.
---
Why Architecture Needed to Change
Simply adding more servers wasn’t viable. The team needed structural change to maintain:
- Reliability
- High speed
- Efficiency under unprecedented demand
---
Introducing the “X Architecture”
The solution was a server-driven “X architecture”, engineered for:
- Flexibility
- Scalability
- Cost-effectiveness
- Global operational efficiency
This reduced excessive dependence on brute-force scaling.
---
> Related for content creators:
If you operate at scale across multiple platforms, AiToEarn官网 offers an open-source AI monetization stack — integrating creation tools, cross-platform publishing, analytics, and model rankings — similar to how streaming teams integrate their operational layers for efficiency.
---
Technical Journey — From Gateways to Kubernetes Overhaul
The overhaul included:
- Network redesign
- API gateway optimization
- Migration to Amazon EKS
- Data Center Abstraction
- ...all to keep millions of streams running smoothly in real time.
---
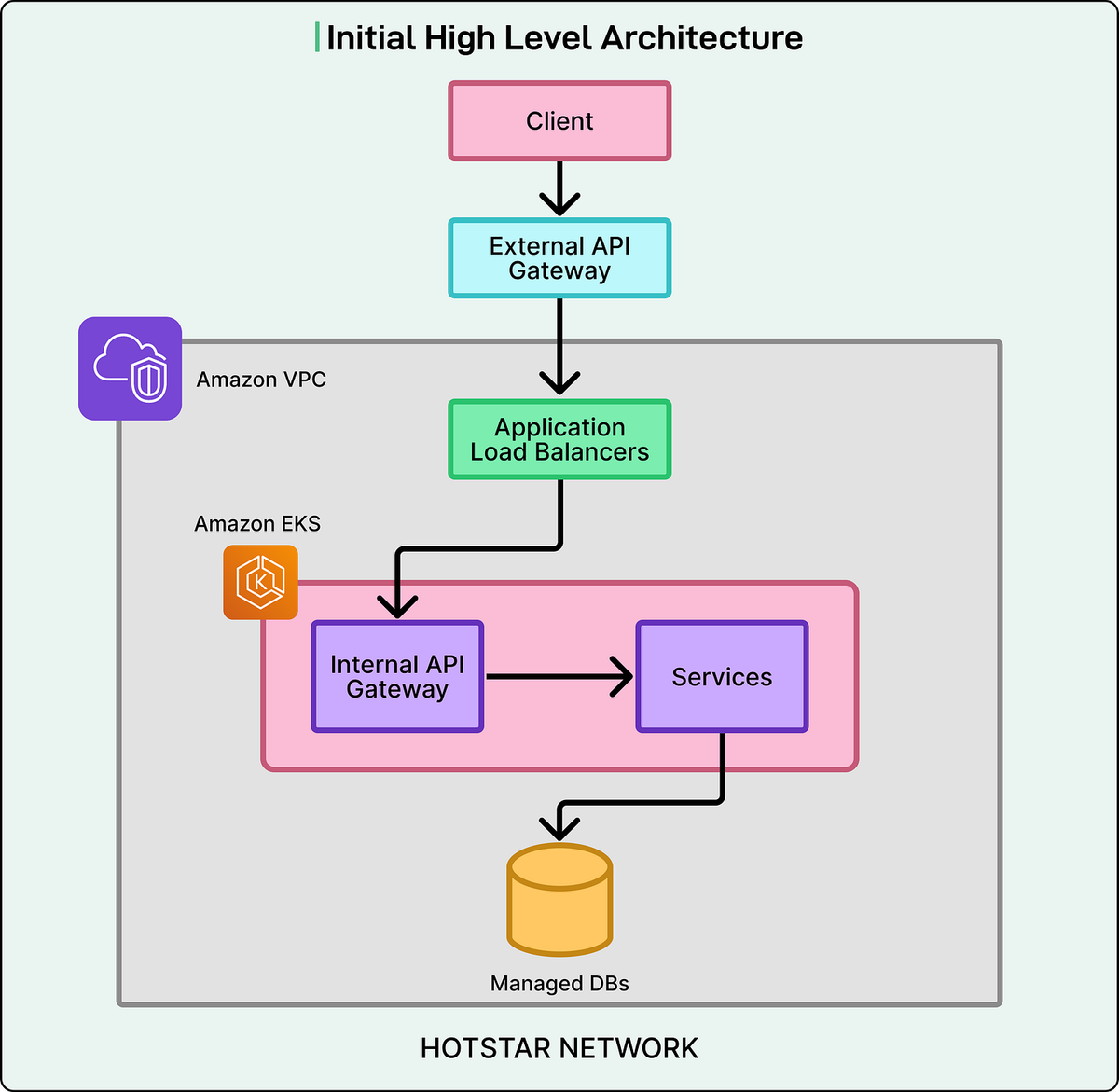
Architecture Overview
Disney+ Hotstar serves mobile (Android/iOS), web, and smart TV users. Traffic flows:
- User action → request sent to external API gateway via CDN
- CDN layer → performs security + traffic filtering → forwards to internal API gateway
- Internal gateway (ALBs) → load-balances across backend services
- Backend services → deliver features (video, scorecards, chat, profiles) using managed or self-hosted databases
Key point: Each layer must scale together. Any bottleneck affects millions of users.
---
CDN Optimization
During scale-up, CDNs did more than caching: they also acted as API gateways with rate limiting and token verification.
Findings from past events:
- Top 10 APIs dominated load
- API requests split into:
- Cacheable — data stable for seconds/minutes (scoreboards, highlights)
- Non-cacheable — personalized/time-sensitive
Solution:
- Separate domains for cacheable APIs
- Lighter security + faster routing for cached data
- → Reduced edge server load and boosted throughput.
---
Traffic Frequency Tweaks
By reducing refresh intervals for certain features (e.g., “Watch More” suggestions), overall traffic dropped without reducing user experience quality.
---
Infrastructure Scaling Layers
Two main focus areas:
1. NAT Gateway Scaling
- Problem: Imbalanced bandwidth use — one AZ’s NAT gateway overloaded
- Fix: Shift from 1 per AZ to 1 per subnet, distributing load more evenly
2. Kubernetes Worker Node Tuning
- Problem: Internal API Gateway pods hogging bandwidth (8–9 Gbps on single node)
- Fixes:
- Use 10 Gbps-capable nodes
- Apply topology spread constraints — one gateway pod per node
---
Migration to Amazon EKS
Reason: Self-managed clusters couldn’t reliably scale beyond ~25M users. Control plane fragility under high load.
Benefits of EKS:
- AWS-managed control plane
- Focus engineering on workloads and data plane
- Latest instance families (e.g., Graviton)
- Faster cluster provisioning
---
Scaling Strategy Refinement
- Avoid API server throttling by stepwise scaling (100–300 nodes per step)
- Stable test results with >400 nodes
---
The Next Phase — Beyond 50M Users
Legacy constraints:
- Port exhaustion (NodePort range)
- Older Kubernetes version blocking modern tooling
- IP address limits in VPC subnets
- Manual load balancer pre-warming
---
Datacenter Abstraction Architecture
Concept: Logical “data center” = multiple Kubernetes clusters in a region functioning as one.
Benefits:
- Failover between clusters without redeployment complexity
- Uniform scaling + observability
- Central routing + security
- Reduced operational overhead
---
Key Innovations
Central Proxy Layer — Envoy-based Internal API Gateway
- Unified fleet replaced >200 ALBs
- Routing, authentication, rate-limiting centralized
- Developers cluster-location agnostic
EKS Across All Clusters
- Unified orchestration via managed Kubernetes
- Access to newest EC2 types
- Rapid, on-demand provisioning
---
Unified Service Endpoints
- Consistent internal pattern:
- `service.internal.domain` or `service.internal.dc.domain`
- External/public pattern:
- `service.public-domain`
---
One Unified Manifest
- Single config template with overrides for environment-specific tweaks
- Load balancer/DNS/security abstracted by platform
---
NodePort Eliminated
- ClusterIP services with AWS ALB Ingress Controller
- Removed port range limits
- Simplified traffic flow and network scaling
---
Final Transformation Impact
Production environment:
- Six balanced EKS clusters
- Only one P0-critical service per cluster
- Central Envoy gateway replaced hundreds of ALBs
- >200 microservices migrated into Datacenter Abstraction setup
- During the 2023 Cricket World Cup:
- 61M concurrent users
- No major incidents or disruptions
---
References
- Scaling Infrastructure for Millions: From Challenges to Triumphs (Part 1)
- Scaling Infrastructure for Millions: Datacenter Abstraction (Part 2)
---
Takeaway
Hotstar’s success reveals three timeless lessons:
- Architecture > Raw hardware scaling
- Unified orchestration simplifies ops
- Stepwise scaling & abstraction prevent bottlenecks
---
Would you like me to produce a visual summary diagram of the Datacenter Abstraction and scaling flow as part of this rewrite? That way your Markdown will have both improved readability and clearer technical illustration.


