Inference Speed Soars 60×: DiDi-Instruct Lets Diffusion LLMs Beat Thousand-Step GPT in Just 16 Steps

2025-10-27 13:21 Beijing
DiDi-Instruct introduces a breakthrough approach for extreme acceleration, alignment, and reinforcement learning in large-scale language models.


---
Overview
A collaboration between Purdue University, University of Texas, National University of Singapore, Morgan Stanley ML Research, and Xiaohongshu Hi-Lab has yielded a post-training method for Discrete Diffusion Large Language Models — called Discrete Diffusion Divergence Instruct (DiDi-Instruct).
Key advantages:
- Up to 60× acceleration over traditional GPT and standard diffusion LLMs.
- Distills a “student” from a diffusion “teacher” model — achieving improved efficiency and generation quality.
---
How It Works
Core Innovation — Post-training via Probability Distribution Matching
- Teacher model: Requires >500 inference steps.
- Student model: Generates a paragraph in only 8–16 steps.
- Benchmark results (OpenWebText):
- 64× speedup in inference.
- Outperforms the teacher (1024-step) dLLM and GPT-2 (1024-step) in quality.
Practical Impact
The algorithm improves both efficiency and reasoning quality, enabling ultra-efficient LLM deployment.

---
Related Links
- Paper: Ultra-Fast Language Generation via Discrete Diffusion Divergence Instruct
- www.arxiv.org/abs/2509.25035
- Code: github.com/haoyangzheng-ai/didi-instruct
- Project: haoyangzheng.github.io/research/didi-instruct
---
Research Background
The "Speed Limit" of LLM Generation
Autoregressive models (ARMs), e.g., ChatGPT, DeepSeek:
- Generate sequentially, token-by-token.
- Even with parallel hardware, long-form generation latency remains high.
Diffusion language models (dLLMs):
- Start with noise/masked sequences → iteratively denoise in parallel.
- Faster paragraph generation possible, but still require hundreds of steps.
Key research question:
Can a model, in just 8–16 iterations, outperform a 1024-step GPT?
---
DiDi-Instruct — The Game-Changer
Post-training algorithm for dLLMs:
- Reduces 1024 steps → 8–16 steps
- Improves performance vs. teacher and AR baselines.
Implication:
Optimizes high-speed generation without sacrificing quality — ideal for real-world deployment.
---
Link to AI Content Publishing Ecosystem
Platforms like AiToEarn官网 align with DiDi-Instruct’s goals by:
- Generating AI content.
- Publishing across multiple platforms (Douyin, Kwai, WeChat, YouTube, Pinterest, X/Twitter).
- Tracking performance & monetization.
---
Theoretical Foundation
Derived from Diff-Instruct (continuous diffusion).
Goal: Minimize integral KL divergence between student and teacher models across the entire discrete denoising trajectory.
This:
- Aggregates KL divergence across time steps (weighted).
- Ensures global matching rather than only final output alignment.
- Leads to better convergence and stability.
---
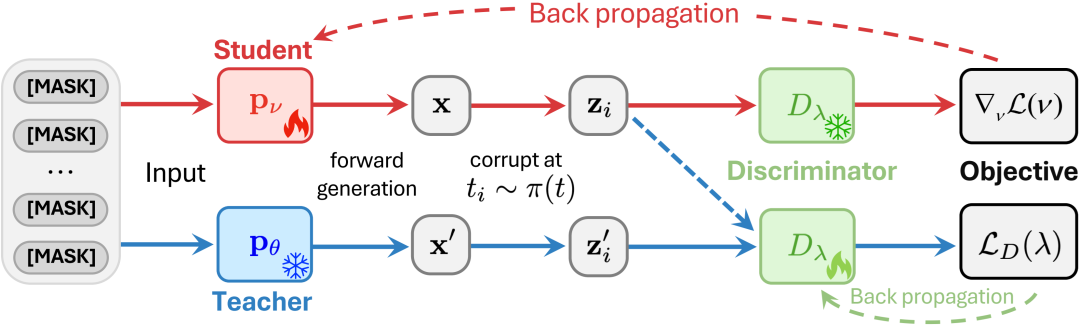
Pipeline:
- Reconstruct clean text from masked input (teacher & student).
- Discriminator compares outputs → reward signal.
- Student model learns to match teacher’s distribution.
---
Key Technical Innovations
- Policy-Gradient Distribution Matching
- Reformulates KL objective → policy gradient form with a reward function, avoiding discrete differentiation issues.
- Dynamic Reward Shaping (Adversarial Learning)
- Discriminator distinguishes noisy samples from student and teacher; log-density ratio → reward signal.
- Stability & Quality Enhancements:
- Grouped Reward Normalization
- Reduces variance, inspired by GRPO.
- Stepwise Intermediate-State Matching
- Prevents mode collapse; improves output diversity.
- Reward-Guided Ancestral Sampling
- Integrates gradient guidance + candidate re-ranking for high-quality inference.

Post-training algorithm.

Reward-guided ancestral sampling.
---
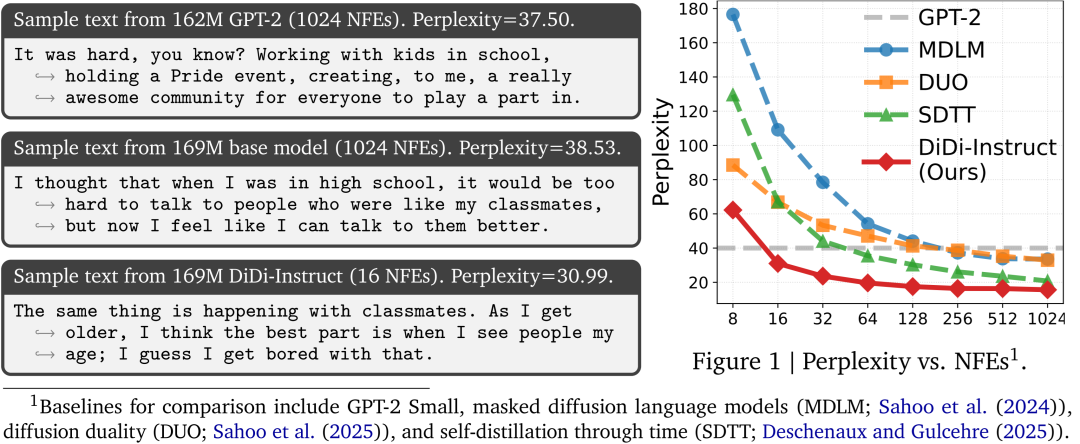
Experimental Results
1. New Quality Benchmark
- Outperformed GPT-2, MDLM, DUO, SDTT across NFEs from 8–128.
- 16 NFE output exceeds 1024-step teacher quality — 30% improvement.
- Maintains diversity (entropy loss ~1%).
---
2. Training Efficiency
- Distillation training: ~1 hour on 1× NVIDIA H100 GPU.
- Competing baselines: >20× longer training times.
---
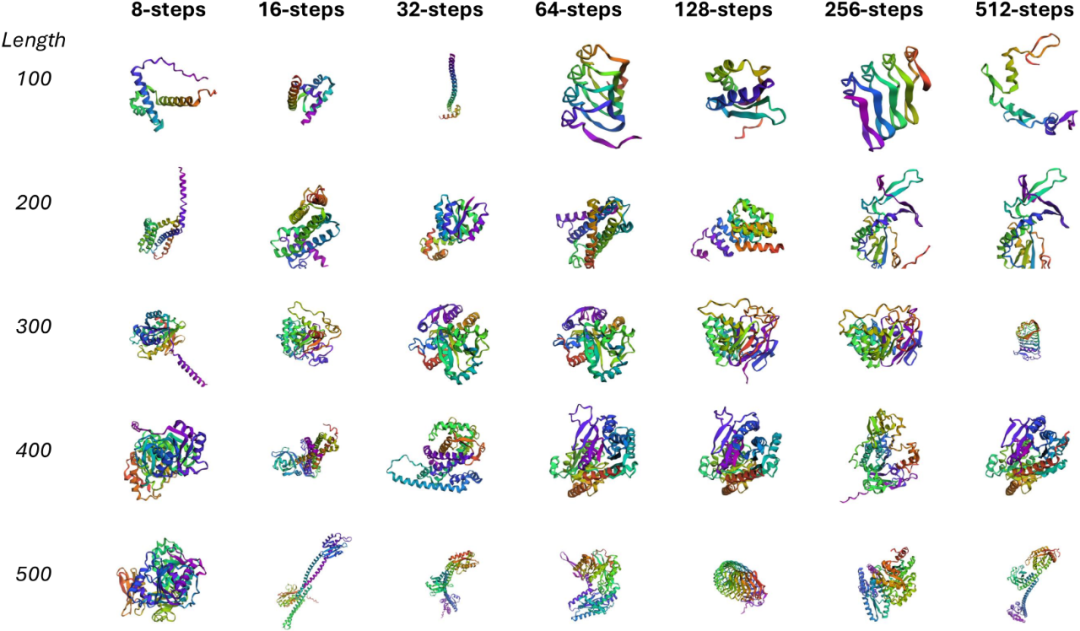
3. Cross-Domain Generalization
- Applied to protein sequence generation.
- Student retained variable-length generation capacity.
- Produced high-confidence structures in few steps.
---
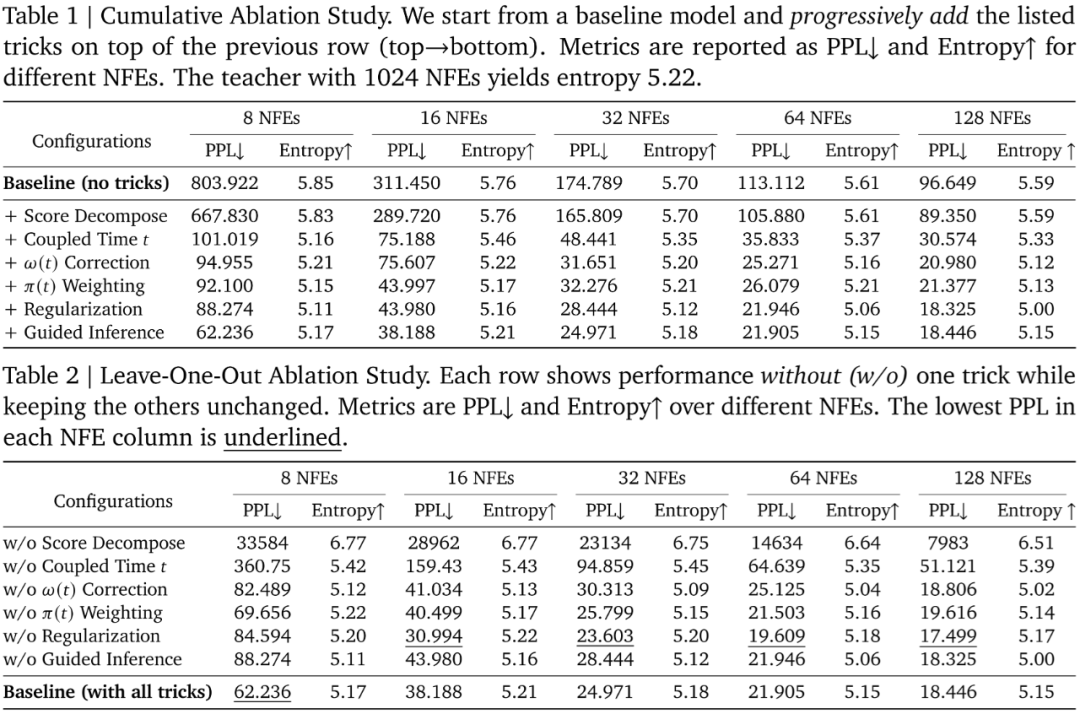
4. Ablation Studies
Key findings:
- Intermediate state matching: Crucial stability driver.
- Time-step coupling: Major PPL reduction at low steps.
- Regularization: Helps at low NFEs, may hinder at high NFEs.
- Guided inference: Improves quality at low NFEs, boosts diversity in high NFEs.
---
Technical Outlook
Promise:
Efficient, adaptive generative models across NLP, bioinformatics, and beyond.
Future potential:
Coupling breakthroughs like DiDi-Instruct with deployment platforms (AiToEarn官网) →
Mass-scale, fast, monetizable AI generation.
---
Team
- Haoyang Zheng (First Author, Ph.D. candidate, Purdue University, supervised by Prof. Guang Lin).
- Weijian Luo (Hi-Lab, Xiaohongshu).
- Wei Deng (Morgan Stanley ML Research, NY).

---
Conclusion:
DiDi-Instruct delivers record-setting acceleration and top-tier quality in discrete diffusion LLMs — establishing a robust framework for next-gen AI content generation at unprecedented efficiency.
---
Would you like me to prepare an English annotation set for all workflow diagrams?
That would make this article fully accessible to non-Chinese technical readers.