# HiPO: Intelligent Thinking Switch for Efficient LLM Reasoning
When a user asks a large language model (LLM) a simple question—
for example: *How many letters P are in the word “HiPPO”?*—
the model may unexpectedly produce a long chain-of-thought explanation:
> “First, let’s analyze the word HiPPO. The English term for ‘hippopotamus’ is hippo, a semi-aquatic mammal. Here the user used capital letters...”
Such verbose reasoning:
- **Wastes compute resources**
- **Increases wait time**
- **Can even result in wrong answers** due to reasoning loops
**This overthinking habit** is a growing issue as LLMs pursue stronger reasoning capabilities.
---

## The Problem: Overthinking in LLMs
LLMs excel at complex cognitive tasks thanks to **Chain-of-Thought (CoT)** reasoning, which mimics human step-by-step analysis.
However, they often apply deep reasoning to trivial questions.
### Key Drawbacks
- **High cost & latency**: Longer outputs mean more tokens, inflated API costs, and slower responses.
- **Poor adaptability**: The same “think deeply” mode is applied everywhere—simple or complex.
- **Error risk**: Over-complicated reasoning can deviate from the correct answer.
### Existing Mitigation Approaches
1. **Training-based Adaptive Reasoning**: RL with length penalties or SFT promoting brevity
↳ Risk: Penalizing length harms performance on genuinely hard tasks.
2. **External Controls**: Prompt engineering to limit reasoning steps
↳ Risk: Manual, non-scalable, poor generalization.
3. **Post-hoc Optimization**: Pruning generated reasoning chains
↳ Limitation: Cannot fundamentally change the model’s thinking process.
---
## Introduction to HiPO
The **KwaiKAT team** at Kuaishou, in collaboration with **Nanjing University’s NLINK** group (Prof. Liu Jia-heng) and the **ARiSE lab** (Prof. Zhang Yu-qun), launched **HiPO (Hybrid Policy Optimization)**—an intelligent “thinking switch” for LLMs.
**Core idea:**
Enable the model to decide **when** to activate detailed reasoning (**Think-on**) and **when** to give a direct answer (**Think-off**).
Benefits:
- **Improved accuracy** on complex tasks
- **Reduced token consumption** and latency on simple tasks

**Resources:**
- Paper: [https://arxiv.org/abs/2509.23967](https://arxiv.org/abs/2509.23967)
- Model: [https://huggingface.co/Kwaipilot/HiPO-8B](https://huggingface.co/Kwaipilot/HiPO-8B)
---
## I. Root Cause: Cognitive Inertia in LLMs
### Why LLMs Overthink
The success of step-by-step reasoning in hard problems has led to **cognitive inertia**:
models treat every task as complex.
---
## II. HiPO’s Two-Component Solution
### Component 1: Hybrid Data Cold-Start
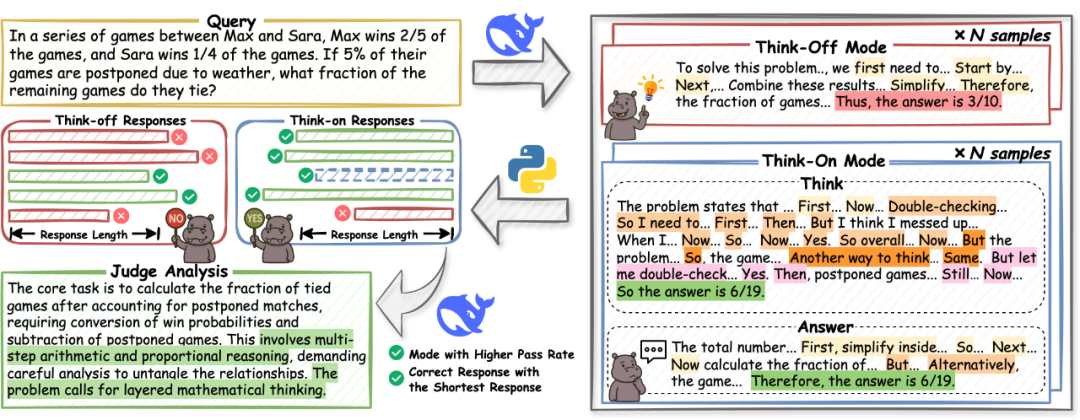
**Goal:** Provide training data for both “think” and “no-think” modes.
**Process:**
1. **Collect diverse datasets** – math & code reasoning sources like AM-Thinking-v1-Distilled, AceReason-Math, II-Thought-RL, Skywork-OR1-RL-Data.
2. **Dual-mode generation** – Use a strong model (e.g., DeepSeek-V3) to produce multiple “Think-on” and “Think-off” answers per question.
3. **Select mode via pass rate comparison**:
- Choose **Think-on** if significantly better; else prefer **Think-off**.
- If pass-rate difference < δ threshold → lean toward Think-off.
4. **Pick shortest correct answer** in chosen mode.
5. **Add justification signals** – Short explanations for mode choice, injecting “why” reasoning awareness.
---
### Component 2: Hybrid Reinforcement Learning Reward System
**Goal:** Refine mode choice; avoid “thinking” inertia.
**Rewards:**
1. **Base reward** – Based on answer correctness and format.
2. **Bias adjustment mechanism**:
- Calculate avg reward in Think-on; set bias for Think-off using ω (~0.01).
- Boost Think-off when performance difference is small → encourages brevity.
3. **Advantage functions**:
- **Judgment Advantage** *(A_judge)*: Ensures mode choice aligns with justification quality.
- **Answer Advantage** *(A_answer)*: Improves answer quality within chosen mode.
**Training:** PPO-like algorithm with token-level optimization for both reasoning and answer segments.
---
## III. Results: Faster & More Accurate
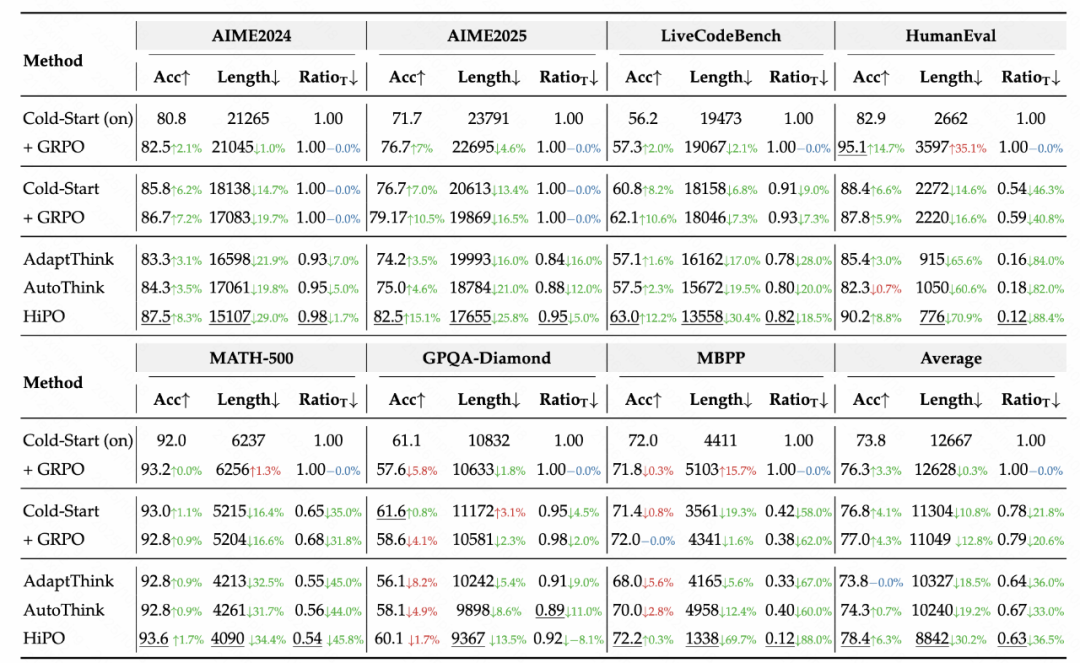
**Benchmarks:** AIME2024/25, HumanEval, LiveCodeBench v6, MATH-500, GPQA-Diamond.
**Highlights:**
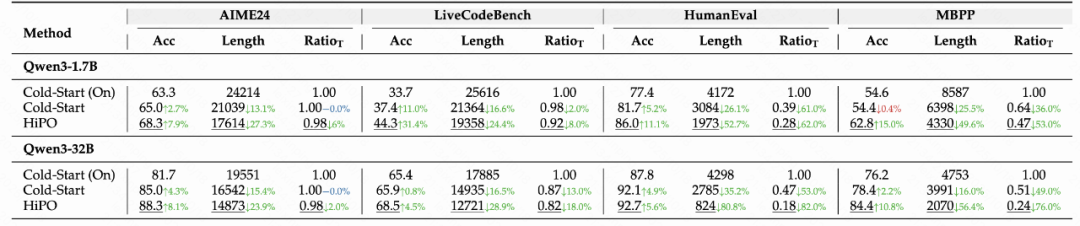
- **30% shorter outputs**, **37% lower “thinking” rate** (RatioT)
- **+6.3% accuracy improvement**
- Outperforms **AdaptThink** and **AutoThink**
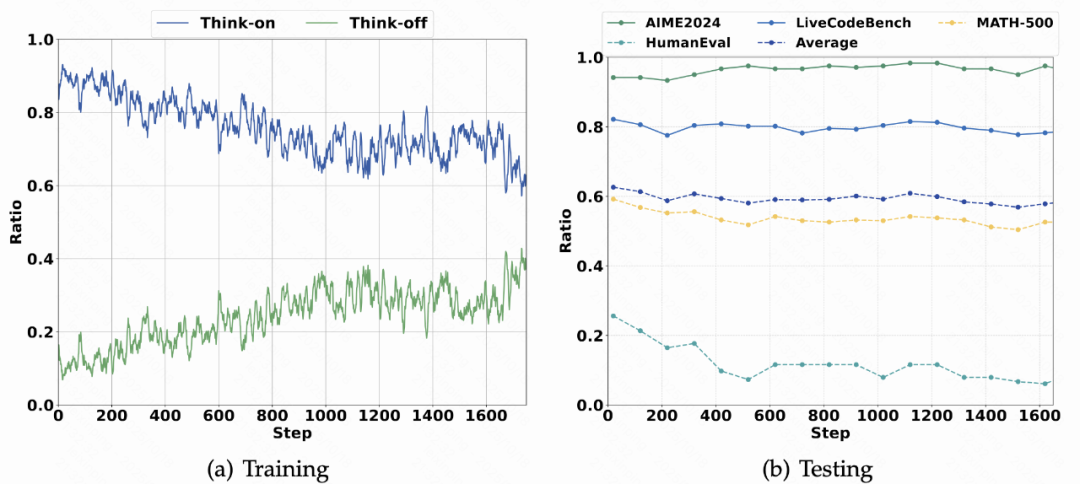
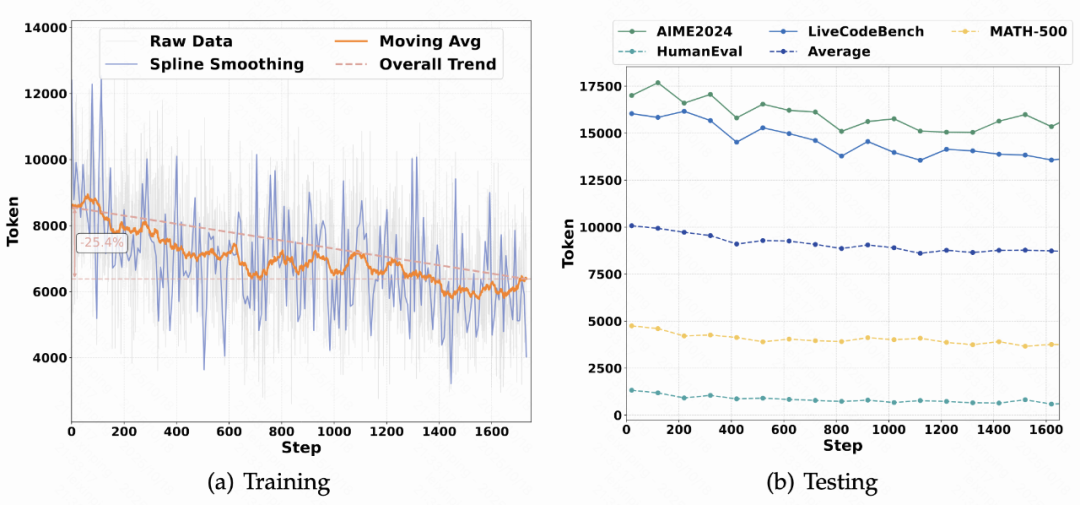
**Dynamic decision analysis:**
- Mode activation gap narrowed from **89.5% to 53.1%** over RL training
- Mode rates adapt by dataset difficulty
↳ High Think-on for hard tasks (AIME), low for simpler (HumanEval)
---
## IV. Future Outlook
1. **Practical LLM deployment** – Lower latency & cost for large-scale applications.
2. **Model lightweighting** – “Stop thinking” when unnecessary can aid compression/distillation.
3. **Metacognitive AI** – Models deciding *how* to think represent a leap in AI intelligence.
---
## V. Conclusion
The HiPO framework teaches LLMs **to discern when deep reasoning is warranted** vs when a direct answer suffices—balancing **quality** and **efficiency**.
**Open-source model**: [https://huggingface.co/Kwaipilot/HiPO-8B](https://huggingface.co/Kwaipilot/HiPO-8B)
---