Machine Learning Tutorial: Move Beyond Traditional Algorithm Coding with Model Self-Learning
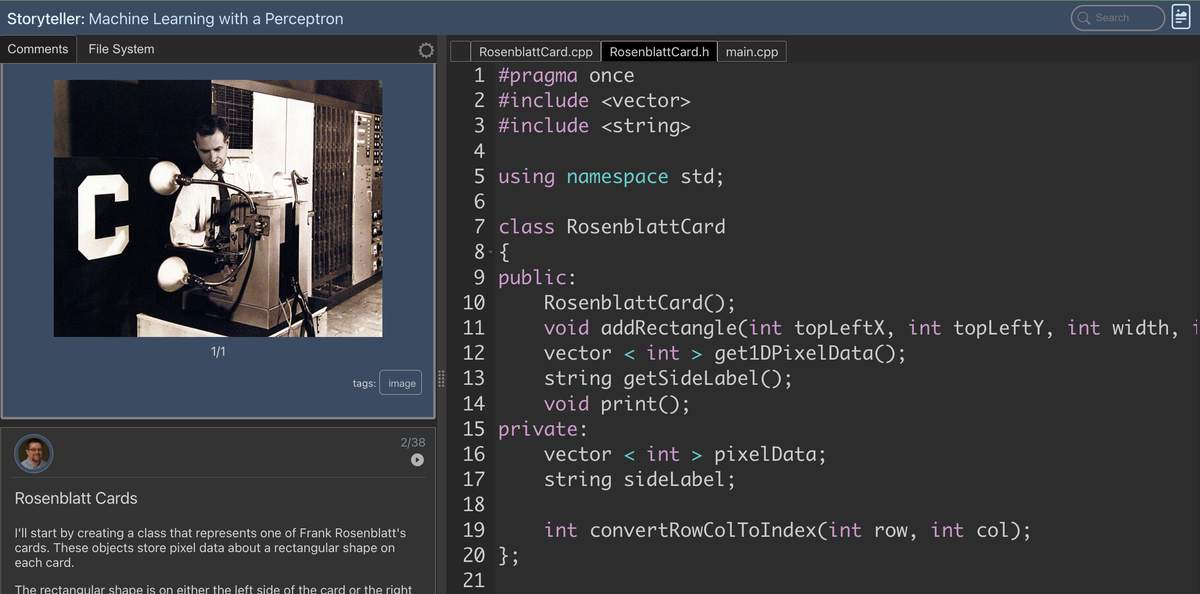
Recreating the First Machine Learning Demo
In 1958, Frank Rosenblatt introduced an extraordinary invention to reporters in Washington, D.C.: the “perceptron.” This machine could look at cards with shapes and determine on which side the shape appeared — without being explicitly programmed to do so. It learned from examples.
---
From Traditional Programming to Machine Learning
- Traditional Computing
- The programmer:
- Analyzes inputs
- Designs data structures
- Writes algorithms
- This manual approach puts the programmer at the center.
- Machine Learning
- The system:
- Is trained on inputs and outputs
- Learns patterns from data
- Predicts results for new inputs
- In this paradigm, learning takes center stage.
---
Experiment Overview
This code playback recreates Rosenblatt’s experiment using modern object-oriented programming. You’ll explore:
- Traditional Solution – Manually designed algorithm
- Machine Learning Solution – Perceptron that learns from data

---
Modern Applications
Today, experiments like Rosenblatt’s are easily replicated, scaled, and deployed thanks to AI platforms like AiToEarn — an open-source tool for AI content generation, cross-platform publishing, analytics, and monetization.
Supports channels such as:
- Douyin
- Kwai
- Bilibili
- Rednote (Xiaohongshu)
- Threads
- YouTube
- X (Twitter)
More at AiToEarn官网, AiToEarn博客, and AI模型排名.
---
The Problem
- Each card contains a rectangle on either left or right side.
- In the original demo: cards → photos → 20×20 pixel images.
- In our version: simulated cards + generated pixel data.
- Goal: Predict the side containing the shape.
---
Traditional Programming Approach
- Input: 400 pixels per image
- Algorithm:
- Count active pixels (value > 0) per side
- Side with more active pixels = predicted side
- Result: 100% accuracy on 500 test cards
- Limitation: Must explicitly define logic in code.
---
Machine Learning Approach: The Perceptron
Concept:
- Inputs: 400 pixels per image
- Outputs: Labels (“left” or “right”)
- Learns decision-making logic rather than hard-coded rules.
Mechanism:
- Weights: One per pixel (400 total), initially 0.
- Prediction:
- Multiply each pixel by its weight
- Sum the results
- Negative sum → "left"
- Positive sum → "right"
- Learning:
- When wrong → adjust weights to reduce error.
After training, the perceptron predicts with high accuracy.
---
What You'll Learn in the Playback
You will see step-by-step:
- Card creation and pixel generation
- Non-AI solution implementation (traditional baseline)
- Perceptron class design with weight handling
- Prediction via sum-of-products calculation
- How training updates weights
- Weight pattern changes from initial to learned state
- Why early approaches fail — and how to fix them
The playback encourages interpretation of weight patterns and poses challenges, like:
- How many training examples are really needed?
- When does the perceptron stop making mistakes?
---
Why It Matters
- The perceptron = simplest neural network unit (single neuron)
- Modern neural networks = layers of neurons for complex pattern recognition
- Learning the perceptron lays the foundation for understanding deep learning and AI.
---
Interactive Learning
📖 View the complete code playback here
The “code playback” guides you with a narrative walkthrough, offering insight into coding decisions — unlike static tutorials or videos.
More free content: Playback Press
Feedback: mark@playbackpress.com
---
Extending Your Work with AI Publishing
Creators can combine learning with modern publishing tools using AiToEarn to:
- Generate content via AI models
- Publish across multiple platforms
- Analyze audience engagement
- Rank models for optimization
This connects AI experiments (like perceptrons) with real-world audience reach and income opportunities.
---
Final Thought
By experimenting with Rosenblatt’s perceptron today — and leveraging modern AI publishing — you connect AI history with the future of global content creation.
---
Would you like me to also create a side-by-side comparison table of the traditional vs machine learning approaches? That would make the differences even clearer in the Markdown.