New LLM Reinforcement Learning Framework: UCSD Multi-Agent Training Boosts LLM Tool-Use Capability by 5.8×
Reinforcement Learning Framework for Large Language Model Agents
First Implementation of Universal Multi-Agent Group Reinforcement
---
Background
Numerous studies show that multi-agent workflows with large language models (LLMs) often outperform single-agent systems — even without targeted training.
Yet, most current LLM agent training frameworks are limited to single-agent training, leaving universal multi-agent “group reinforcement” an open problem.
---
Introducing PettingLLMs
Researchers from UCSD and Intel developed PettingLLMs, a generalized multi-agent reinforcement learning framework that supports training multiple LLMs in arbitrary combinations.
Multi-agent LLM systems can significantly boost performance in:
- Healthcare
- Programming
- Scientific research
- Embodied AI
---
Core Algorithm: Group Relative Policy Optimization (GRPO)
GRPO has proven effective for large model agent training.
Principle:
- Receive the same input prompt
- Sample multiple candidate responses
- Evaluate them with a reward model
- Compute relative advantages within the group
⚠ Key Assumption: All responses are generated from exactly the same context (prompt).
---
Fundamental Challenge in Multi-Agent Environments
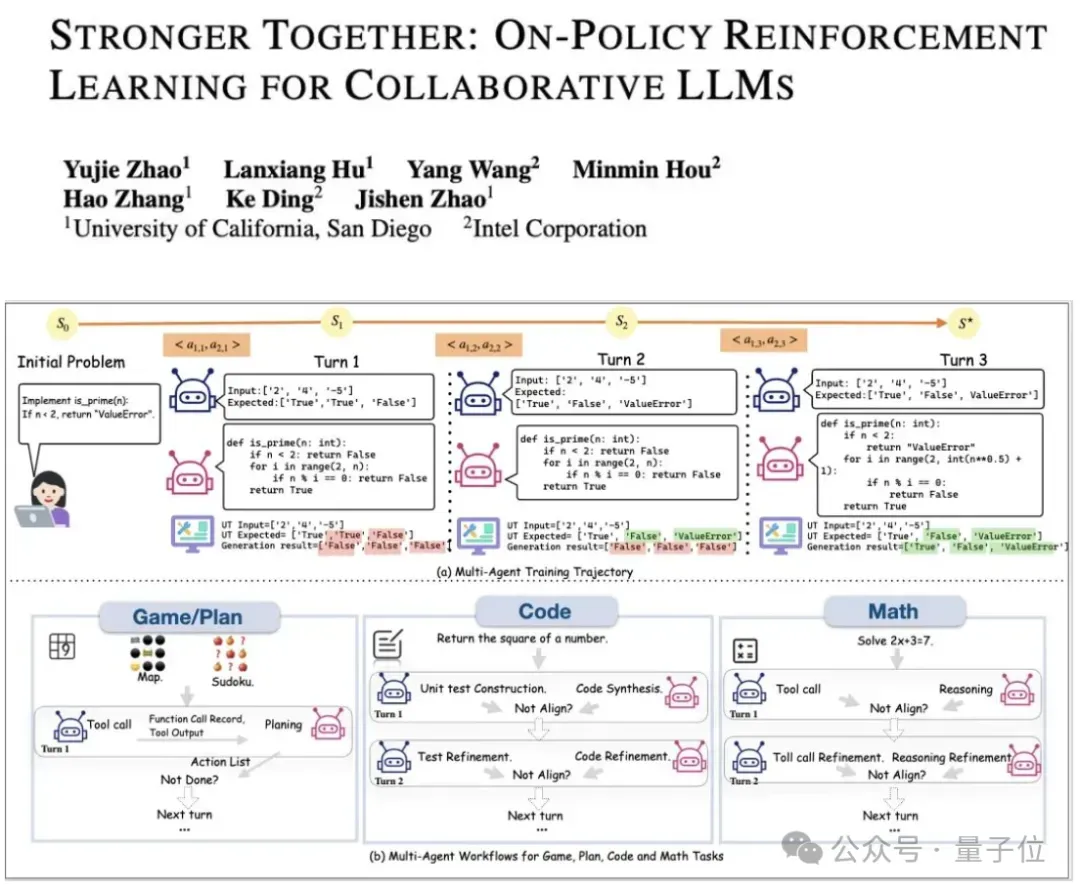
In multi-agent, multi-turn tasks:
- Prompts evolve differently per agent and turn
- Example: In coding tasks, a second-turn prompt may include:
- Original question
- Code from first turn
- Unit tests generated by other agents
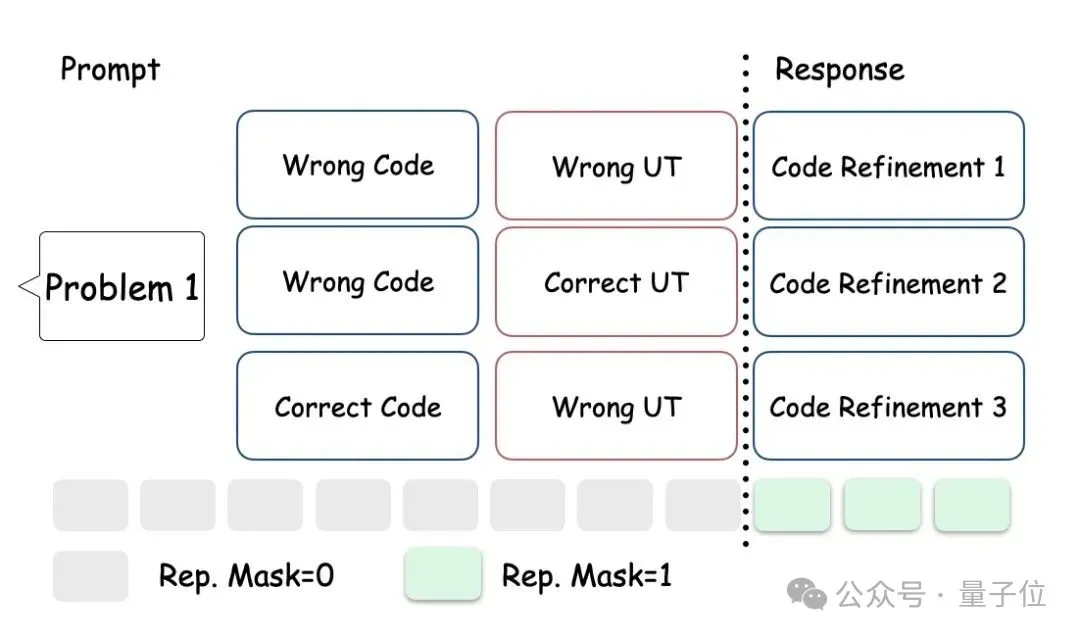
If we group responses from different prompts together for advantage calculation, this violates GRPO’s shared context requirement, harming fairness.
---
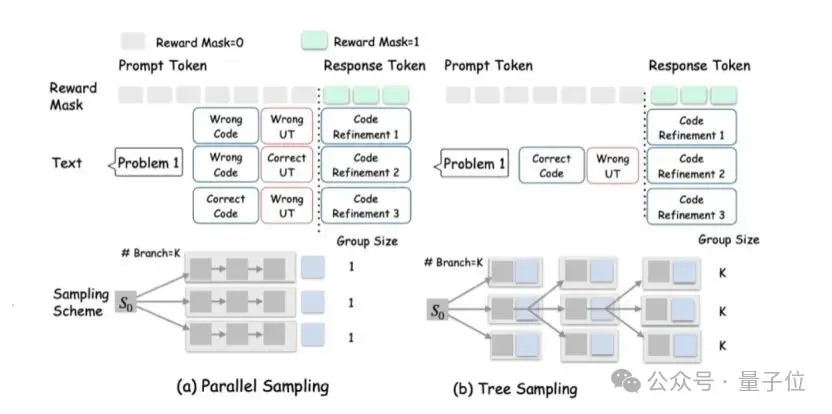
Solution: Greedy-Search Tree Sampling
Approach:
- Each turn: Every agent forms a node with K branches
- After branching: Only the highest-reward branch proceeds
- Balances exploration vs exploitation
Rewards:
- Role-specific rewards + global task rewards
- Drives specialized capabilities and cooperation skills
---
Specialization vs Shared Model Strategy
Question: When should agents have specialized models vs a shared model?
Implemented System: Asynchronous distributed training:
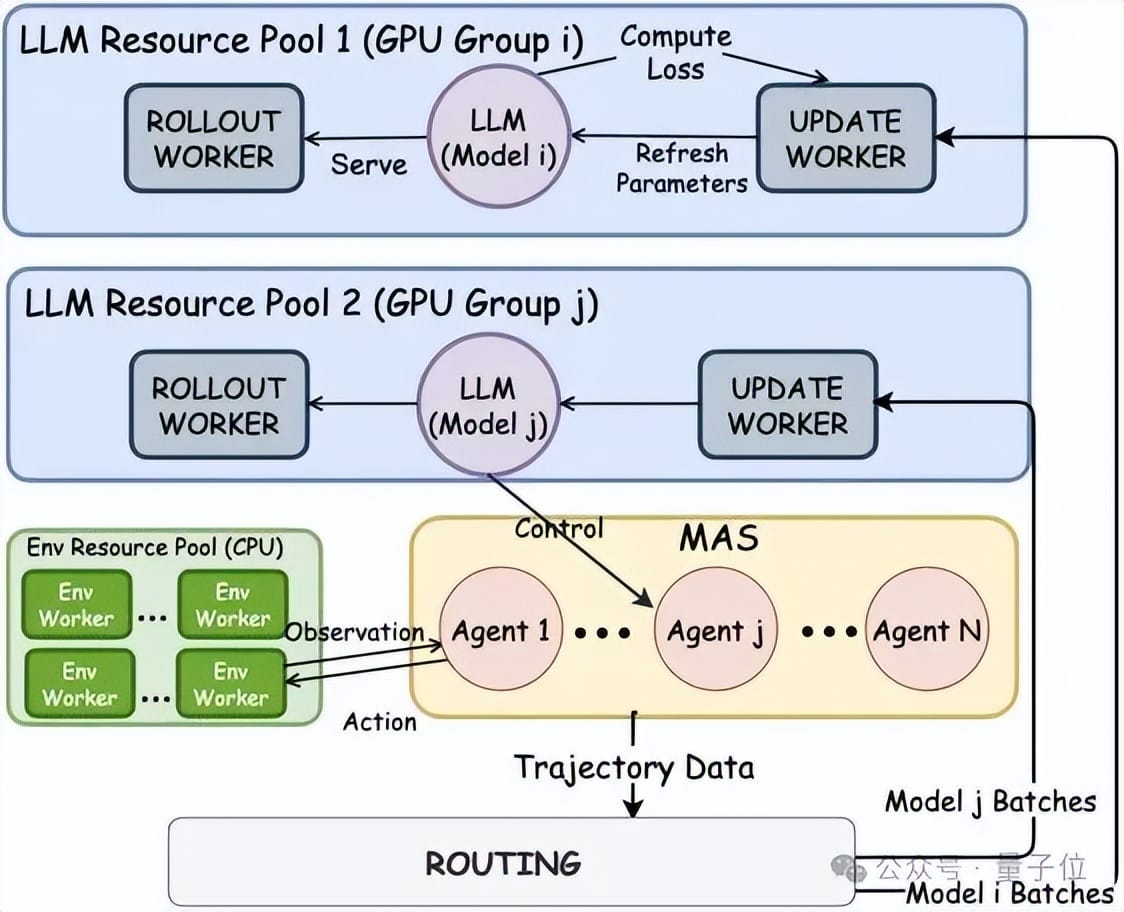
Training Modes
- Specialized Model Mode:
- Multiple independent model pools (Pool i, Pool j)
- Routing sends Agent i’s data to Pool i → updates Model i only
- Shared Model Mode:
- Merges all agents’ data into one pool
- Updates a shared model for all agents
---
Framework Advantages
PettingLLMs unifies multi-agent cooperation & specialization.
It’s open-source for faster development.
Environment Support:
- Developers only need to implement:
- Task-specific interaction logic
- Reward functions
- Built-in environments: mathematics, coding, games
- Arbitrary mappings between models and agents
- Individual LoRA configurations per agent
---
Real-World Training Results
In Sokoban (long-horizon task), AT-GRPO improved task performance from 14% to 96%.

---
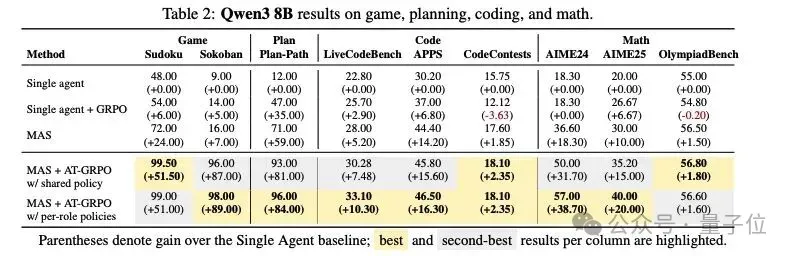
Large-Scale Experiments
Models: Qwen3-1.7B and Qwen3-8B
Tasks:
- Planning: Sokoban, Plan-Path
- Coding: LiveCodeBench, APPS, CodeContests
- Mathematics: AIME 24/25, OlympiadBench
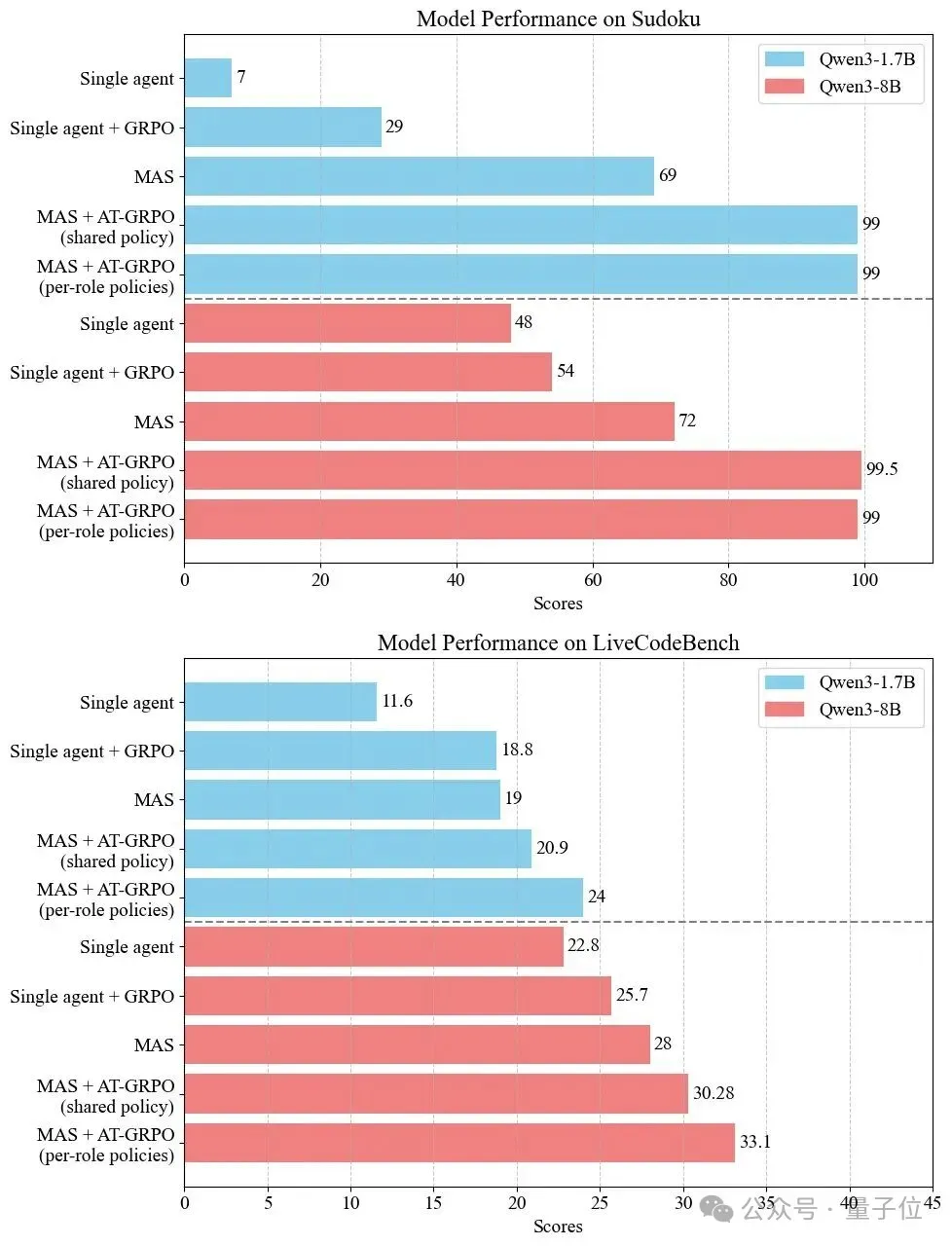
Performance Gains:
- Planning: Sokoban +82%, Plan-Path +52.5%
- Coding: LiveCodeBench +6.1%, APPS +4.2%, CodeContests +7.0%
- Math: AIME 24 +9.0%, AIME 25 +17.9%
---
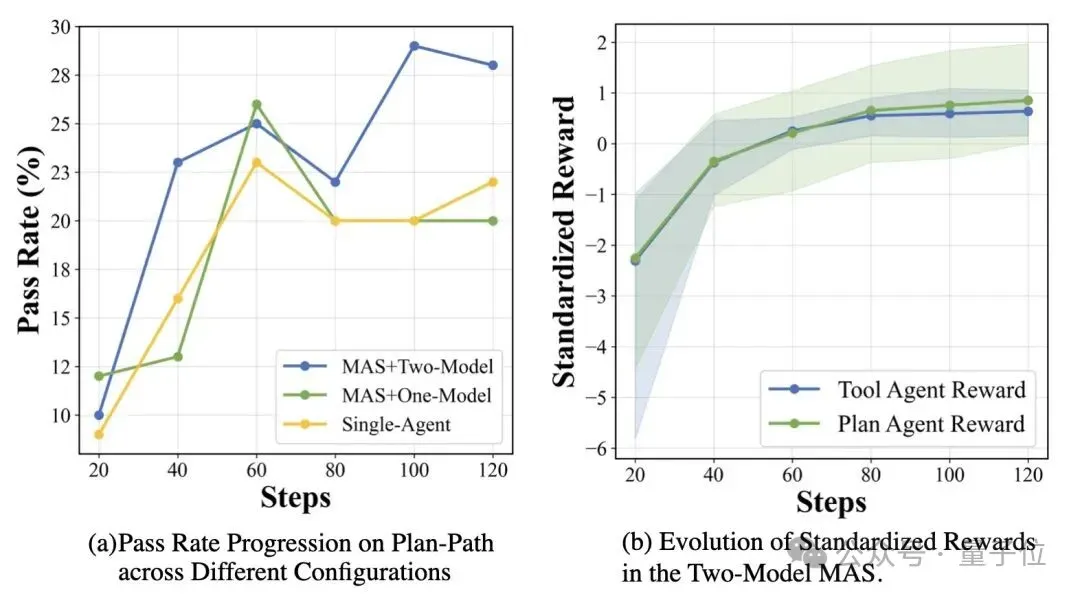
Ablation Studies
- Single-agent training is limited:
- Planning/tools single-agent: +6–9% → MAS only +16% total
- Role strategy swapping causes collapse:
- Accuracy drops from 96% → 6%
- Cooperation improves over time:
- Sync rewards + fewer rounds required
---
Resources
- Paper: https://huggingface.co/papers/2510.11062
- GitHub: https://github.com/pettingllms-ai/PettingLLMs
---
Complementary Tools
For deployment and publication, AiToEarn官网 offers:
- Open-source AI content monetization platform
- Publishing to Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
- Integrated analytics and AI model rankings
- Docs: AiToEarn文档
- Repo: AiToEarn开源地址
---
Conclusion:
PettingLLMs bridges the gap between single-agent RL training and universal multi-agent group reinforcement — enabling coordinated, specialized, and scalable LLM agent evolution across diverse tasks.
Would you like me to also create a diagram summarizing PettingLLMs’ architecture so it’s easier to grasp the system at a glance? That could make this Markdown even more readable.