Open-Source Model Wins First Physics Olympiad Gold: Shanghai AI Lab's 235B Model Beats GPT-5 and Grok-4
🏅 Open-source AI Model Wins Gold at International Physics Olympiad
Historic Achievement
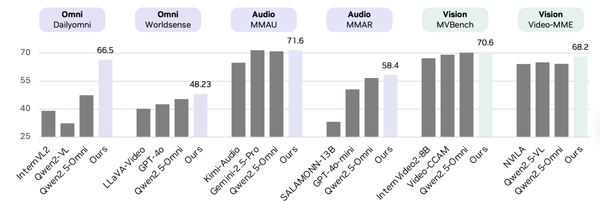
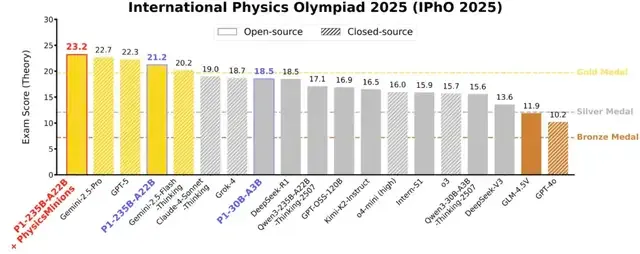
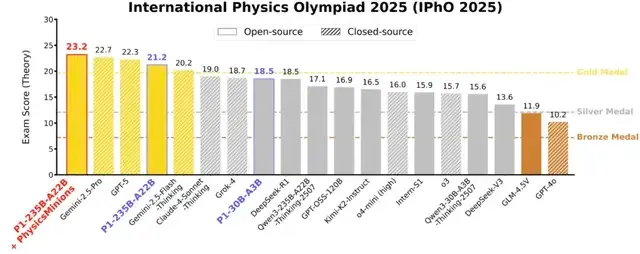
The P1-235B-A22B model from Shanghai AI Lab has achieved a 21.2/30 score at the International Physics Olympiad (IPhO) — surpassing the gold medal threshold and making history as the first open-source model to win gold.
In the HiPhO benchmark (13 top-tier global physics competitions, 2024–2025), P1-235B-A22B earned:
- 12 gold medals
- 1 silver medal
- Tied first place on the leaderboard with Google Gemini-2.5-Pro
This surpasses:
- GPT-5 – 11 golds
- Grok-4 – 10 golds
It demonstrates that open-source models have now matched — and even surpassed closed-source models — in physics reasoning.
---
🌍 Significance of AI in Physics Reasoning
Physics reasoning is critical for understanding and shaping the real world. Prestigious competitions such as IPhO require:
- Complex reasoning
- Deep physics understanding
Winning gold is a vital milestone toward general physics intelligence and showcases real-world problem-solving potential.
---
🧪 HiPhO: Benchmark for Physics Olympiads
HiPhO (High School Physics Olympiad) is the first benchmark dedicated to recent Olympiad-level physics contests with human-aligned evaluation.
Coverage (2024–2025):
- IPhO
- APhO
- EuPhO
- Other regional Olympiads (total: 13 contests)
Evaluation Approach:
- Official competition scoring standards
- Fine-grained human-aligned evaluation of both answers and reasoning steps
- Scores directly comparable to human contestants’ medal boundaries

HiPhO benchmark overview (13 competitions worldwide).
Training Dataset:
- Thousands of Olympiad-level problems
- Full context + verifiable answers
- Standard solution paths
- Purpose-built for reinforcement learning training
---
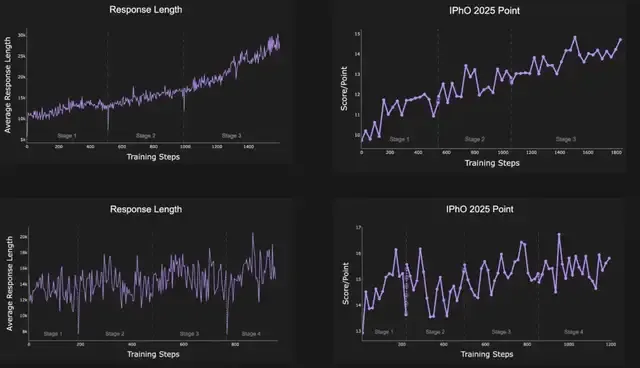
📈 Multi-stage Reinforcement Learning in P1
P1-series models achieve sustained improvement via multi-stage reinforcement learning, with two core strategies:
- Expanding Context Window
- Gradual increase of output length
- Enables longer chains of reasoning
- Improves complex problem-solving & reduces truncation errors
- Pass-rate Filtering
- Uses pass-rate statistics before training
- Filters out tasks that are too easy or too hard
---
🤝 PhysicsMinions: Evolutionary Multi-agent Reasoning
To overcome single-model limitations, the team built PhysicsMinions — a collaborative evolutionary multi-agent system. It consists of three interconnected modules:
- Visual Module (Visual Studio)
- Observes and verifies multimodal problems
- Extracts structured visual information
- (Not used in P1 model’s experiments)
- Logic Module (Logic Studio)
- Generates initial solutions
- Iteratively revises answers via self-reflection
- Review Module (Review Studio)
- Physics Validator: checks physical consistency (constants, units)
- General Validator: checks logical and calculation soundness
❗ If a stage fails, an error report is sent back to the Logic Module for refinement — iterating toward higher accuracy.
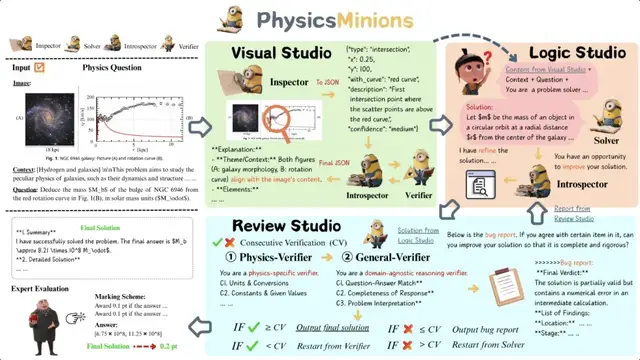
PhysicsMinions framework and module interactions.
---
📊 Results & Benchmark Highlights
P1-235B-A22B:
- 12 gold + 1 silver (HiPhO)
- Surpassed: GPT-5 (11 gold), Grok-4 (10 gold)
- Scored 21.2/30 at IPhO 2025 — only open-source gold winner
P1-30B-A3B:
- 8 gold, 4 silver, 1 bronze (HiPhO)
- Ranked 3rd among open-source models
- Beats several closed-source models (e.g., o4-mini, Claude-4-Sonnet)
PhysicsMinions Impact:
- P1-235B-A22B avg score: 35.9 (HiPhO)
- With PhysicsMinions: 38.4 — overall 1st place surpassing Gemini-2.5-Pro (37.7) and GPT-5 (37.4)
P1 models also improved in math, code, STEM — showing generalization beyond physics.
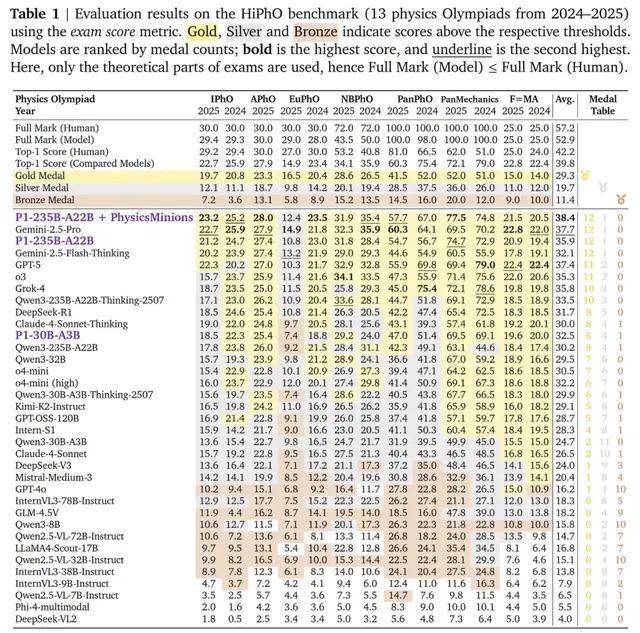
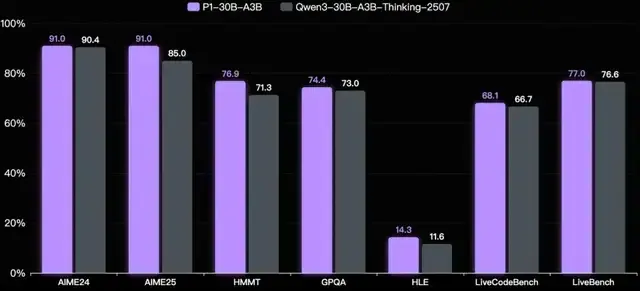
---
🔗 Project Links
P1 Models:
- Project Page: https://prime-rl.github.io/P1
- GitHub: https://github.com/PRIME-RL/P1
HiPhO Benchmark:
- Paper: https://arxiv.org/abs/2509.07894
- Dataset: https://huggingface.co/datasets/SciYu/HiPhO
- Leaderboard: https://phyarena.github.io/
PhysicsMinions:
- Paper: https://arxiv.org/abs/2509.24855
---
🚀 Real-world Application for Creators
Platforms like AiToEarn官网 allow creators to:
- Generate AI-assisted content
- Publish across multiple social channels (Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter)
- Track analytics & performance
- Monetize creativity efficiently
By integrating outputs from advanced AI models such as P1 into content workflows, creators can achieve global reach and fast monetization — powered by open-source AI breakthroughs.