Profound Insights on Large Models and AGI — Gathering the Wisdom of Top AI Experts
Large Model Intelligence | Insights & Synthesis
Expert Perspectives on AI's Future
Drawing from interviews with leading figures in the AI community:
- Andrej Karpathy — Former Tesla Autopilot Director: AGI is still a decade away.
- Richard Sutton — Father of Reinforcement Learning: LLMs may be a dead end.
- Wu Yi — Former OpenAI, now Tsinghua University: GPT playing Werewolf reveals cognitive quirks.
- Yao Shunyu — Former OpenAI: Building systems for new worlds.
- Tian Yuandong — AI researcher: How large models “compress the world” and experience “epiphany.”
- Yang Zhilin — Moonshoot CEO: Standing at the beginning of infinity.
This synthesis integrates and aligns their insights into a single, content-rich, thought‑provoking narrative.
---
00. Introduction — AI at the Crossroads
The stunning success of Large Language Models (LLMs) has placed AI at a pivotal moment:
> Is the data‑driven, imitation-heavy LLM paradigm a direct path to Artificial General Intelligence — or an impressive detour?
In this piece we explore contrasting and converging visions:
- Karpathy — Large models as “ghosts” born from human cultural compression.
- Sutton — Reinforcement Learning as the nucleus of true intelligence.
- Wu Yi — Cognitive flaws undermining current models.
- Yang Zhilin — Capability evolution toward AGI.
- Yao Shunyu — Shifting from “model-centric” to “task-centric” thinking.
- Tian Yuandong — Mechanisms behind sudden leaps in model understanding.
---
01. Two Paradigms of Intelligence
1.1 Imitation Intelligence — The “Ghost” Paradigm
- Origin: Mimics massive human datasets, compressing knowledge into digital form.
- Karpathy’s View: LLMs are ghosts of human culture, distinct from organisms shaped by billions of years of evolution.
- Critique: Sutton notes this imitation bypasses direct world interaction — yielding correlation without causation.
> Key Difference: Pretraining ≈ “crude evolution” → powerful representation learning, but disconnected from physical experience.
1.2 Goal‑Directed Intelligence — The Reinforcement Learning Paradigm
- Definition: Ability to learn through experience to achieve goals.
- Core Elements:
- Substantive Goal — Alters the world, not just predicts tokens.
- Learning from Interaction — Trial, feedback, refinement.
Sutton: Only agents with goals and experiential learning deserve the label “intelligent.”
---
1.3 Shared Foundation — Representation Learning
Tian Yuandong’s Insight:
Both imitation and RL build on world representations.
- Karpathy’s cognitive core: Pretraining offers foundational algorithms & structures.
- Yao Shunyu: Language enables generalization → LLMs gain logic and reasoning patterns.
> Convergence: Divergent paths share the aim of robust world representation.
---
02. Fault Lines in Current Large Models
2.1 Wu Yi’s Three Intrinsic Defects
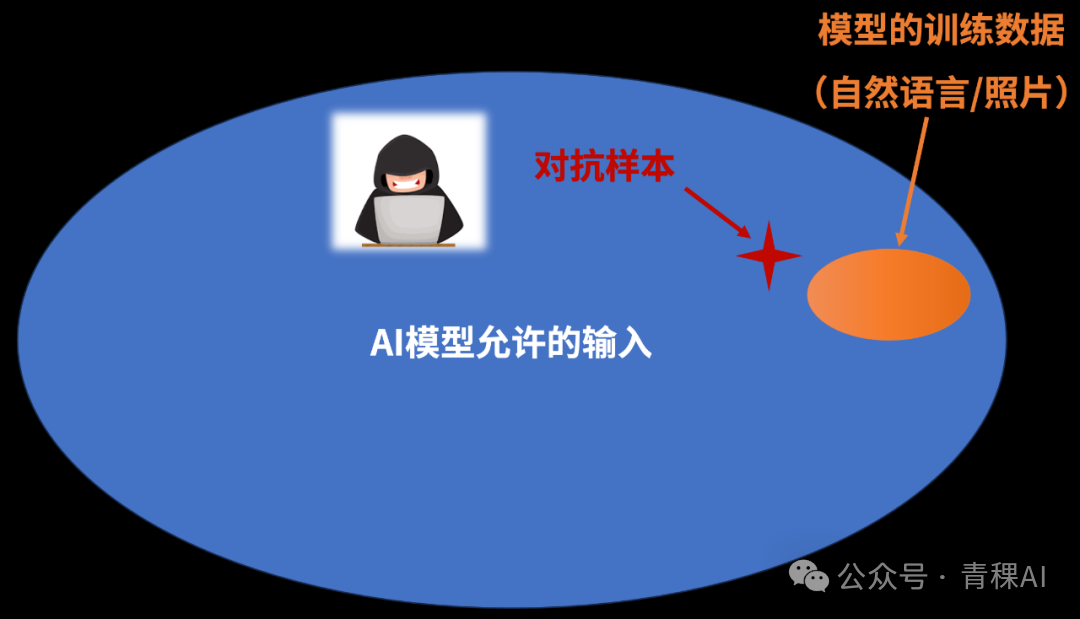
- Adversarial Examples — Unseen inputs trigger instability.
- Bias — Learned from flawed, biased human data; amplified by model overconfidence.
- Hallucinations — Mimicry without causal reasoning; confident predictions for unknowable events.
2.2 Karpathy’s Learning Paradoxes
- Over-Memory — Perfect recall blocks generalization.
- Model Collapse — Synthetic data training reduces diversity, degrading performance.
2.3 Sutton’s “Bitter Lesson”
- History rewards general computation over encoded human expertise.
- Contradiction: LLMs use both massive computation and massive human-generated data — are they the triumph or victim of the Bitter Lesson?
---
03. Roadmaps Toward AGI
3.1 Karpathy’s “Decade of Agents”
Incremental, engineering-focused path:
- Address continual learning, multimodal capability, tool use.
- RL critique: Sparse, noisy reward signals → need better algorithms.
3.2 Yang Zhilin’s Capability Ladder (L1–L5)
L1: Chatbot
L2: Reasoner
L3: Agent
L4: Innovator — Self-evolution
L5: Organizer — Multi-agent collaboration
> Test-Time Scaling — Slow thinking via more compute at inference.
3.3 Yao Shunyu’s “Second Half” — Task-Centric
Focus on:
- Long-term Memory.
- Intrinsic Reward for exploration.
- Multi-Agent Systems for collaboration.
---
04. Mechanisms of Breakthrough
4.1 Tian Yuandong’s “Grokking”
From memorization to generalization:
- Memory Peak: Fragile, high-dimensional memorization.
- Generalization Peak: Robust, low-dimensional rules.
> Crossing over = sudden “epiphany.”
4.2 Reinforcement Learning Creates Causality
- Moves models from correlations to cause-effect understanding.
- Wu Yi’s example: Penalize wrong guesses, reward “I don’t know.”
4.3 Generalization — The Core Challenge
- Sutton: No automatic methods to ensure transfer.
- Risk: Overfitting to benchmarks, poor real-world performance.
---
05. The Ultimate Vision
5.1 Economic Impact
- Gradualist View: Continuation of ~2% GDP growth (Karpathy).
- Explosive View: Infinite digital labor changes economic model.
5.2 Sutton's “Age of Design”
From evolution to intentional creation — AI as humanity's offspring.
5.3 Human-Centered Path
- Safety & Alignment — Complex values, hard to encode.
- Empowerment — Education to avoid societal stagnation.
- Centralization vs. Diversity — Super-apps vs. individual creativity.
---
06. Conclusion & Outlook
The journey toward AGI is defined by:
- Technological divergence — LLMs vs. RL.
- Cross-pollination — Shared representation learning goals.
- Persistent challenges — Generalization, causality, value alignment.
Key Takeaway: The richness of debate mirrors the complexity of intelligence itself; sustained independent thought and open dialogue are critical as we shape a future of human–machine coevolution.


