# RewardMap: Tackling Sparse Rewards in Fine-Grained Visual Reasoning
## Research Collaboration
This work is led by the **ENCODE Lab at Westlake University** in collaboration with:
- **Tongji University**
- **Zhejiang University**
- **National University of Singapore**
The team has strong expertise in **large model reinforcement learning** and **multimodal reasoning**.
---
## Background
In recent years, **Large Language Models (LLMs)** and **Multimodal Large Models (MLLMs)** have achieved breakthrough progress in:
- Scene understanding
- Complex reasoning tasks
Yet a key question remains:
> When visual information becomes extremely complex and densely structured, can a model truly *“understand the picture”*?
Real-world examples — e.g., **high-resolution subway maps** — require:
- Fine-grained visual perception
- Spatial reasoning across multiple lines and stations
---
## Earlier Work: ReasonMap
The team’s prior work, **ReasonMap**, was **the first systematic study** to reveal challenges in high-resolution map reasoning:
- Even state-of-the-art MLLMs suffer from **reasoning hallucinations**:
- Misreading lines
- Missing stations
- Repeating routes
### Key Observation:
On high-resolution, information-rich subway maps:
- RL with **only success/failure signals** from final answers → **Sparse Reward Trap**
- Few accidental correct outputs cause **high-variance gradients**
- Training becomes **slow and unstable**
- Leads to hallucinations in long-chain path planning tasks
---
## Proposed Solution: RewardMap
**RewardMap** is a **multi-stage reinforcement learning framework** specifically designed for real-world map reasoning.
**Core Innovations:**
- **Difficulty-aware fine-grained rewards**
- **Curriculum learning** from easy to hard tasks
**Outcome:**
Improved **fine-grained visual understanding** and **spatial reasoning** in MLLMs.

---
**Paper Title:**
*RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement Learning*
**Links:**
- **[Paper](https://arxiv.org/abs/2510.02240)**
- **[Project Homepage](https://fscdc.github.io/RewardMap/)**
- **[Code](https://github.com/fscdc/RewardMap)**
- **[Dataset](https://huggingface.co/collections/FSCCS/reasonmap-688517b57d771707a5d64656)**
---
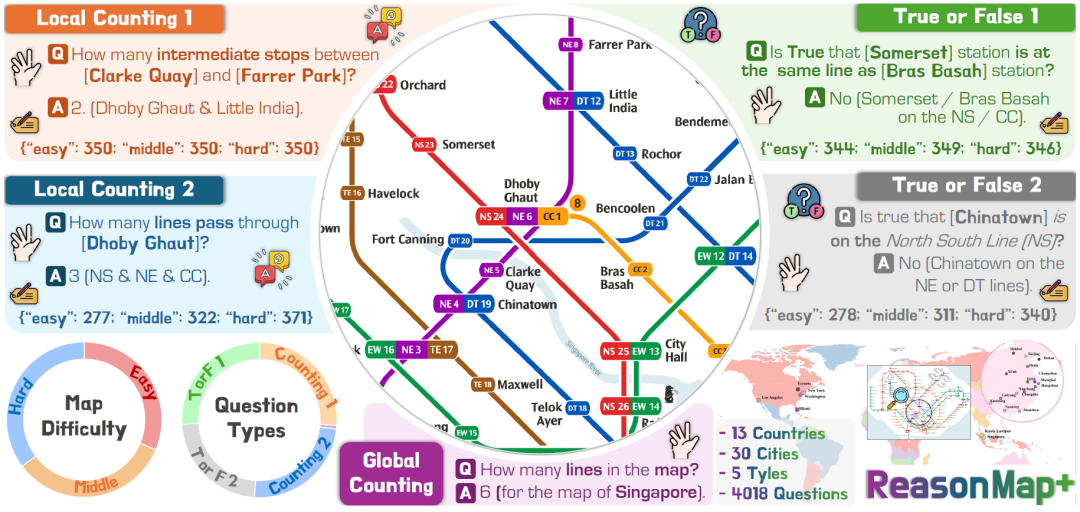
## ReasonMap-Plus: Dense Supervision for Cold Start
Building on ReasonMap, the team developed **ReasonMap-Plus**:
- High-resolution metro/rail maps from **30 cities**
- **4,018 problem samples**
- Five categories of **fine-grained perception-focused tasks**:
- Two types of Local Counting
- Global Counting
- Two types of True/False
- **Difficulty tags**: Easy / Medium / Hard
- **Balanced train/test splits** by city and difficulty
---
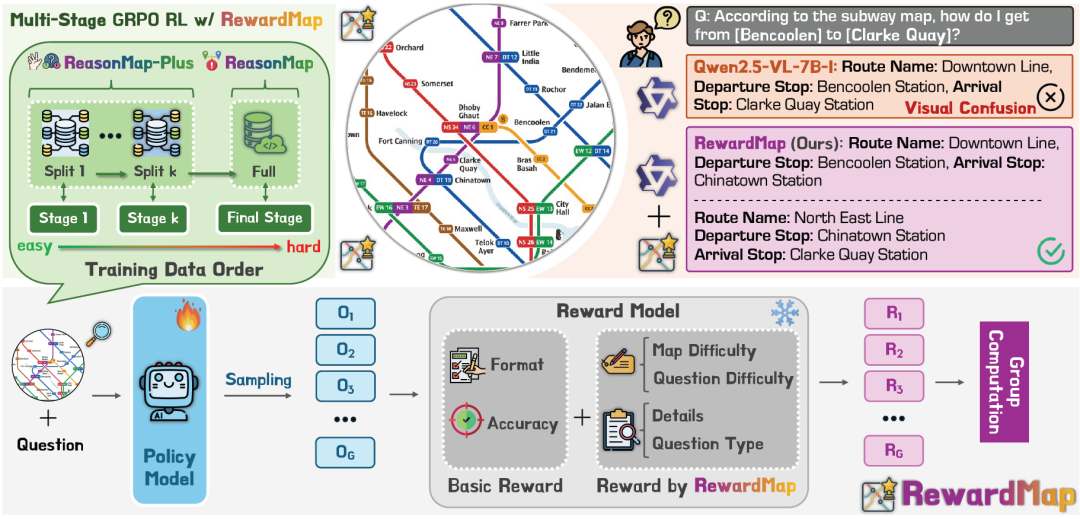
## RewardMap Framework
### Step-by-Step Approach
1. **Decomposable Fine-Grained Rewards**
Split route planning into evaluable sub-goals; avoid binary-only signals.
2. **Curriculum Training**
Train first on dense, low-noise subtasks → then on full real-world planning.
### Core Components
1. **Difficulty-Aware Fine-Grained Rewards**
2. **Multi-Stage RL** leveraging ReasonMap-Plus tasks for strong cold start signals.
**Difficulty Awareness:**
Reward weighting considers:
- **Map difficulty** (three levels)
- **Problem difficulty** (number of transfers → implies higher difficulty)
---
## Reward Function Design
Reward components:
- **Format compliance**
- **Final correctness**
- **Detail items** (weighted by α = 0.5)
**Detail items** add/deduct points based on:
- Correct start/end stations
- Correct route names
- Proper transfer stations
- Correct number of route segments
**Benefit:** Delivers *partial correctness signals*, stabilizing gradients compared to all-or-nothing scoring.
---
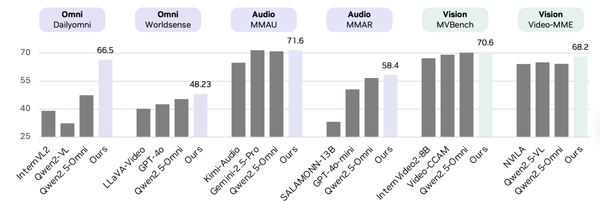
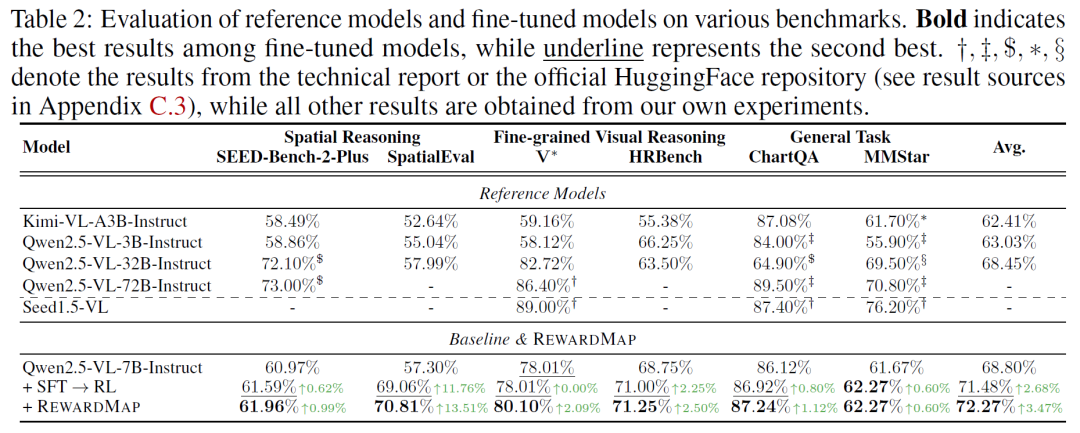
## Results
📈 **Performance Gains**
RewardMap was evaluated on:
1. **ReasonMap**
2. **ReasonMap-Plus**
3. Six external benchmarks across:
- Spatial reasoning
- Fine-grained vision
- General VQA
**Highlights:**
- **Largest improvement**: +13.51% on *SpatialEval*
- Outperformed traditional SFT → RL pipelines
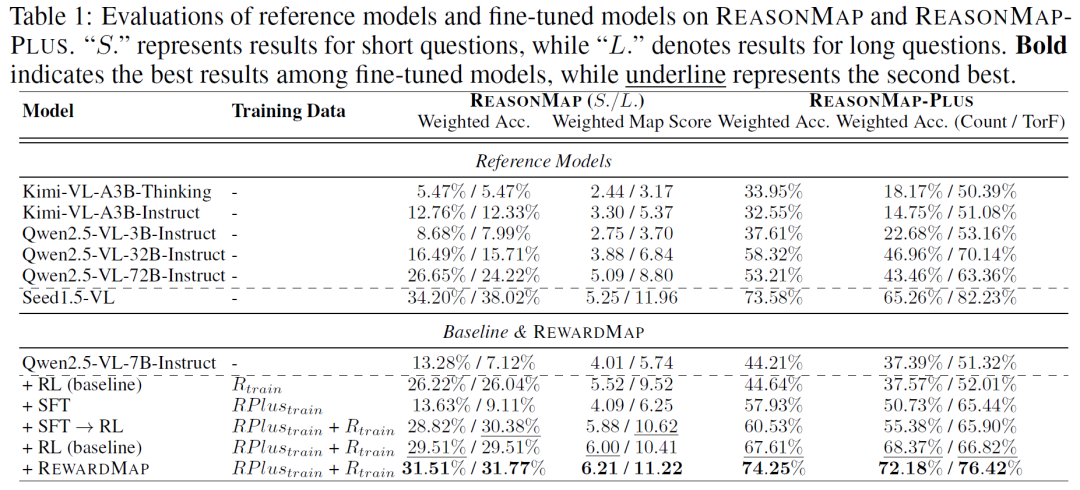
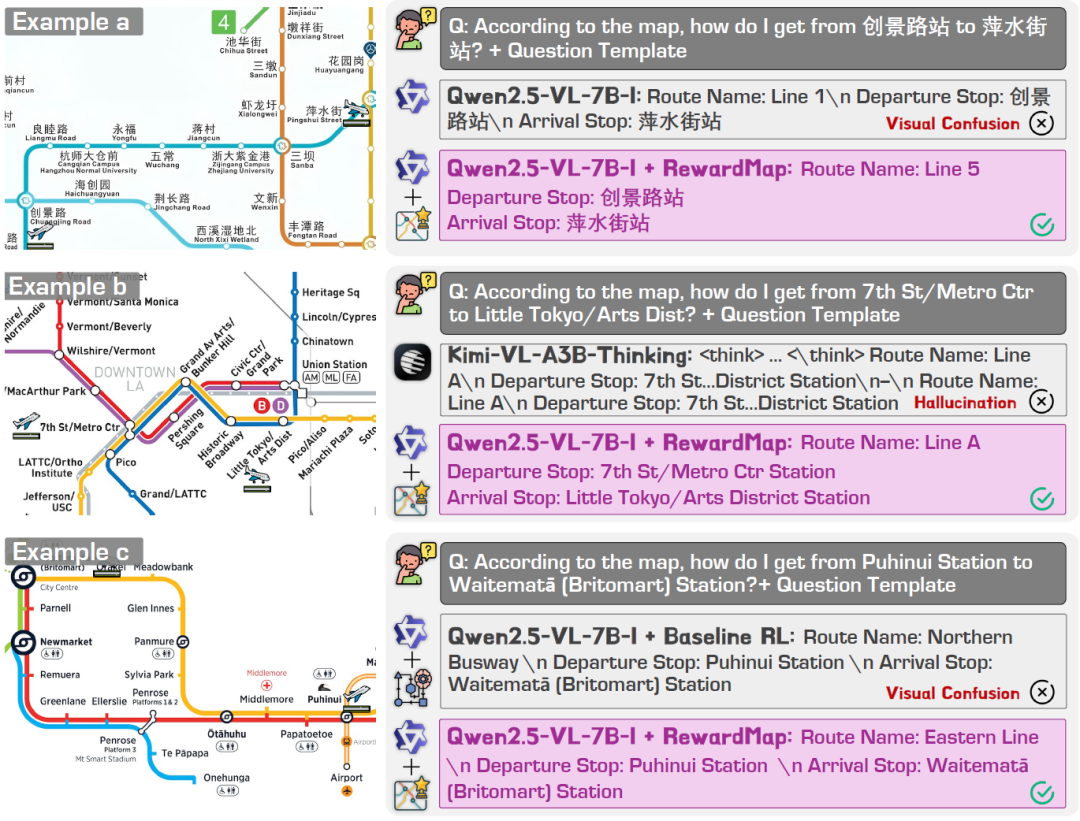
### Qualitative Improvements:
- Fewer line misidentifications
- Reduced hallucinations (repeated routes)
- More accurate start/end stations
- Better route segmentation matching real map structures
---
## Future Outlook
RewardMap demonstrates a **reusable RL paradigm** for high-resolution, structured visual tasks:
- Break problems into measurable sub-goals
- Apply difficulty modeling to balance sparse data
- Link perception-focused subtasks with reasoning-heavy tasks
This ensures the model progresses from:
> **"Seeing clearly" → "Thinking clearly"**
Post-training with map data boosts general MLLM capability — indicating bigger roles for real-world data in future multimodal AI development.
---
## Related Tools for AI Creators
Platforms like **[AiToEarn官网](https://aitoearn.ai/)** showcase how **integrated tooling** benefits creators:
- AI content generation
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X)
- Analytics and model rankings
Visit:
- [AiToEarn博客](https://blog.aitoearn.ai)
- [AI模型排名](https://rank.aitoearn.ai)
While distinct from RewardMap’s research goal, **structured methodologies + integrated ecosystems** apply across AI development and content workflows.
---