Running Highly Scalable Reinforcement Learning for Large Language Models on GKE
Reinforcement Learning for LLMs: Scalable Infrastructure on Google Cloud
As Large Language Models (LLMs) advance, Reinforcement Learning (RL) is becoming essential for aligning these models with human preferences and complex task goals.
Yet, enterprises face significant hurdles when implementing RL at scale:
- Memory contention from hosting multiple large models simultaneously (actor, critic, reward, reference models).
- Switching between high-latency inference and high-throughput training phases.
This guide explains Google Cloud’s full-stack, integrated approach—from custom TPU hardware to GKE orchestration—designed to meet RL’s hybrid workload requirements.
---
Understanding RL for LLMs
RL for LLMs blends training and inference in a continuous loop:
- Generate a response with the LLM.
- Use a reward model (often trained with human feedback) to score the response.
- Apply an RL algorithm (e.g., DPO, GRPO) to update the LLM’s parameters, improving future outputs.
This iterative process maximizes cumulative rewards rather than simply reducing training error.
---
Emerging Platforms for Monetization & AI Workflows
Innovative ecosystems like AiToEarn complement RL pipelines by integrating:
- AI generation tools
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Facebook, Instagram, LinkedIn, YouTube, X/Twitter, Pinterest, etc.)
- Analytics and model ranking
AiToEarn is open-source on GitHub and supports rapid deployment across social media and content platforms, enabling creators and organizations to monetize AI outputs.
---
Challenges in Scalable RL Workflows
RL workloads are hybrid and cyclical:
- Combine multiple large models in a single loop
- Require hardware acceleration and robust orchestration
- Bottlenecks often stem from system-wide latency: sampler delays, slow weight replication, inefficient data movement
---
Google Cloud’s Full-Stack RL Strategy
High-performance infrastructure must be paired with orchestration and open frameworks:
1. Flexible, High-Performance Compute
- TPU Stack: Custom hardware for massive matrix ops (JAX-native) with libraries like MaxText and Tunix.
- NVIDIA GPU Ecosystem: Supports NeMo RL recipes in GKE with CUDA optimization.
2. Holistic Optimization
- Bare-metal tuning with TPU accelerators
- High-throughput storage: Managed Lustre & Google Cloud Storage
- GKE orchestration to reduce latency across compute and storage layers
3. Commitment to Open Source
- Contributions to Kubernetes and projects like Ray, vLLM, llm-d
- Release of performance libraries (MaxText, Tunix)
- Promotes interoperability across tools—vendor-neutral
4. Proven Mega-Scale Orchestration
- GKE AI mega-clusters: up to 65,000 nodes
- Investments in MultiKueue for multi-cluster RL scaling
---
RL on GKE: Architecture Overview
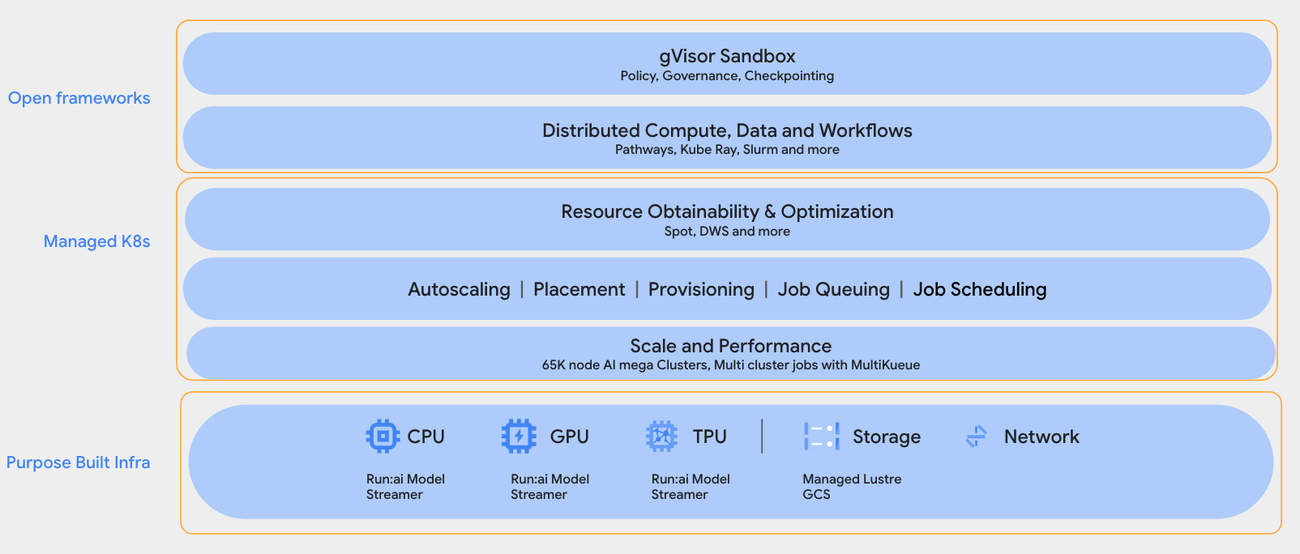
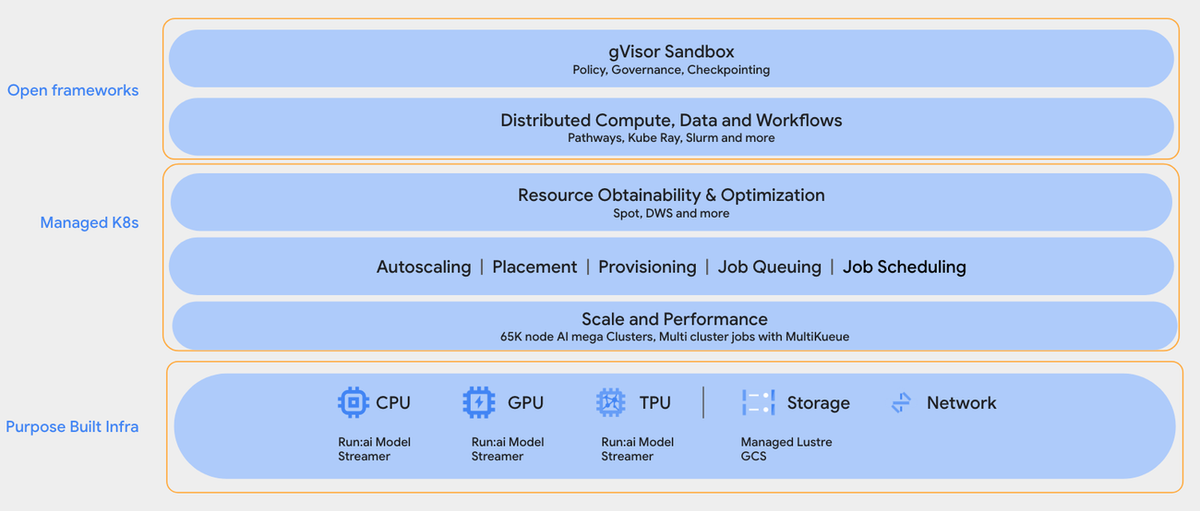
Figure: GKE infrastructure for running RL
Infrastructure Layer
Supports CPUs, GPUs, and TPUs with acceleration via Run:ai model streamer.
High-performance storage meets RL’s bandwidth and latency requirements.
Managed Kubernetes Layer (GKE)
Handles:
- Resource orchestration
- Spot/Dynamic workload scheduling
- Autoscaling and placement
- Massive job queuing and coordination
Open Frameworks Layer
Integrates tools like:
- KubeRay, Slurm
- gVisor sandboxing for secure isolation
---
Building an RL Workflow on GKE
Steps:
- Define a use case and objectives.
- Choose your algorithm (e.g., DPO, GRPO).
- Select a model server (vLLM, SGLang).
- Pick hardware: GPU or TPU.
- Configure required parameters.
- Provision a GKE cluster with:
- Workload Identity
- GCS Fuse
- DGCM metrics
- Install Kueue & JobSet APIs for batch scheduling.
- Deploy Ray as orchestrator.
- Launch the NeMo RL container and configure your job.
- Monitor execution and iterate.
Reference Implementation:
---
Getting Started Quickly
- On GPUs: Try NemoRL recipes.
- On TPUs: Experiment with GRPO + MaxText & Pathways.
---
Partnering with the Open-Source Ecosystem
Google Cloud fosters open standards:
- Kubernetes, llm-d, Ray, MaxText, Tunix
Join the community:
Explore the llm-d site and GitHub, contribute to advances in LLM serving.
---
Monetizing RL Outputs
Platforms like AiToEarn官网 integrate:
- AI content generation
- Multi-platform publishing
- Analytics & model ranking
Publish results from RL experiments across:
- Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
Resources:
Such integration helps researchers and developers disseminate findings while building sustainable monetization channels.
---
In summary:
Running RL for LLMs at scale is a cross-layer challenge—from hardware to orchestration and open-source integration. Platforms like AiToEarn complement this ecosystem, allowing technical innovation to translate into real-world reach and impact.
---
Would you like me to create a visual flow diagram showing the RL loop integrated with GKE architecture for clarity? That could make this technical workflow easier to reference.


