Scaling Law in Expanding External Tests: New Discovery from Zhongguancun College — Lightweight Validators Unlock Optimal LLM Reasoning Choices

2025-11-06 13:26 — Beijing
Rather than chasing ever-larger models, it can be smarter to fully leverage the capabilities of existing ones.


Author & Institution Collaboration
This work is a joint effort by researchers from:
- Beijing Zhongguancun College
- Harbin Institute of Technology (HIT)
- Institute of Automation, Chinese Academy of Sciences
- Other collaborators
Key contributors:
- First Author: Yu Bin — Joint PhD student at Beijing Zhongguancun College & HIT
- Supervisors:
- Prof. Wang Bailing — Dean, HIT Qingdao Research Institute
- Chen Kai — Head of Embodied AI, Beijing Zhongguancun College & Zhongguancun Institute of AI
---
Research Background: Two Paradigms of Test-Time Scaling (TTS)
In an LLM-driven era, Test-Time Scaling boosts reasoning by allocating more computation at inference. Two main paradigms exist:
- Internal TTS: Extends reasoning chains (e.g., DeepSeek-R1)
- External TTS: Generates multiple reasoning paths and aggregates them into the final answer
Challenge:
Internal chain-of-thought extensions are reaching saturation — can external TTS drive further improvement?
---
Best-of-N Paradigm in External TTS
For complex problems (e.g., math):
- Generate N reasoning paths
- Select the most likely correct one
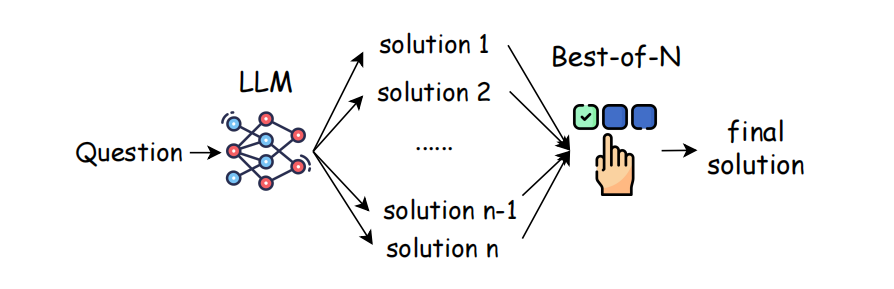
Traditional methods:
- Majority Voting: Chooses most frequent answer (but correct answers often fall in the minority)
- Process Reward Model (PRM): Scores every reasoning step using a separate model — but PRM stability issues arise when used with reasoning-focused LLMs
---
Introducing TrajSelector
A lightweight Best-of-N method that leverages LLM latent states:
- No costly process annotations
- No large PRMs (e.g., 7B parameters)
- Significant gains in mathematical reasoning tasks

Paper Info:
- Title: TrajSelector: Harnessing Latent Representations for Efficient and Effective Best-of-N in Large Reasoning Model
- arXiv link
- Project homepage
---
Two Critical Flaws in Existing Best-of-N Methods
1. High Cost of Large PRMs
- PRMs (~7B parameters) have cost comparable to policy models (e.g., 8B Qwen3)
- Result: Steep computational overhead
2. Wasted Hidden States
- Hidden states encode “self-reflection” signals — yet often unused explicitly
- Performance varies across tasks → poor reliability
---
Why Hidden States Matter
Hidden states can indicate whether deductions are reasonable long before final output.
Goal: Fully exploit these signals with minimal parameter overhead, achieving efficient, effective Best-of-N.
---
TrajSelector Framework Overview
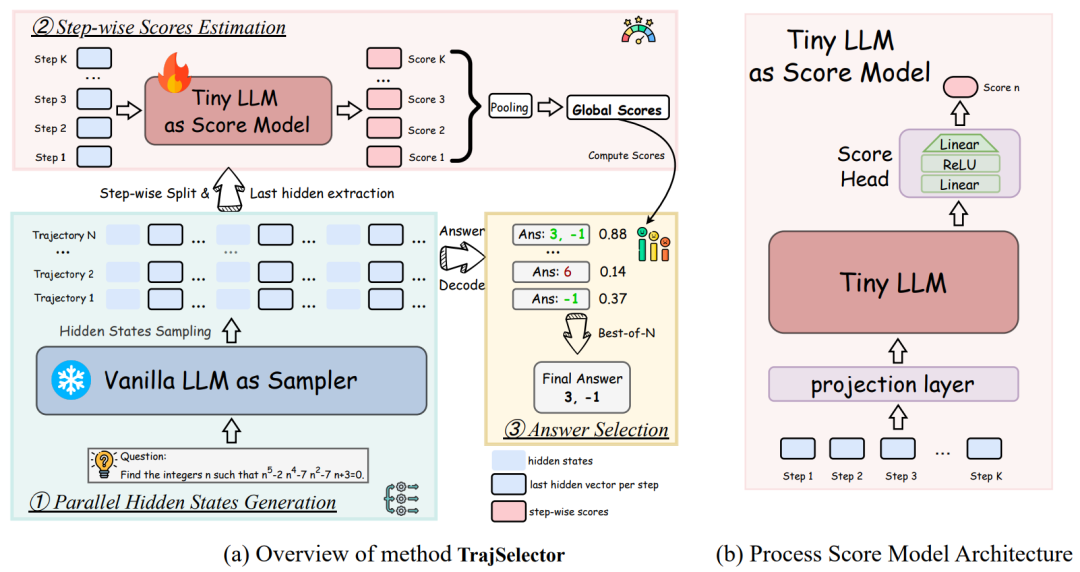
Pipeline:
- Parallel Sampling — Frozen policy model generates multiple trajectories + hidden states
- Step Scoring — Lightweight model (Qwen3-0.6B-Base) scores each step via hidden states
- Aggregation & Selection — Average trajectory scores, choose the highest
---
Training Without Manual Annotations
Challenge: Correct final answers may include incorrect intermediate steps.
Traditional PRMs need step-level human labels — costly.
TrajSelector Approach:
- Uses weak supervision + three-class loss (correct / incorrect / buffer-neutral)
- Inspired by FreePRM
- Buffer category absorbs noise
- Removes dependency on manual labels
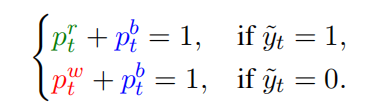
---
Experimental Results
Benchmarks (N = 1 → 64): AMC23, AIME24, AIME25, BeyondAIME, HMMT25, BRUMO-25
For Qwen3-8B with N=16 and N=32:
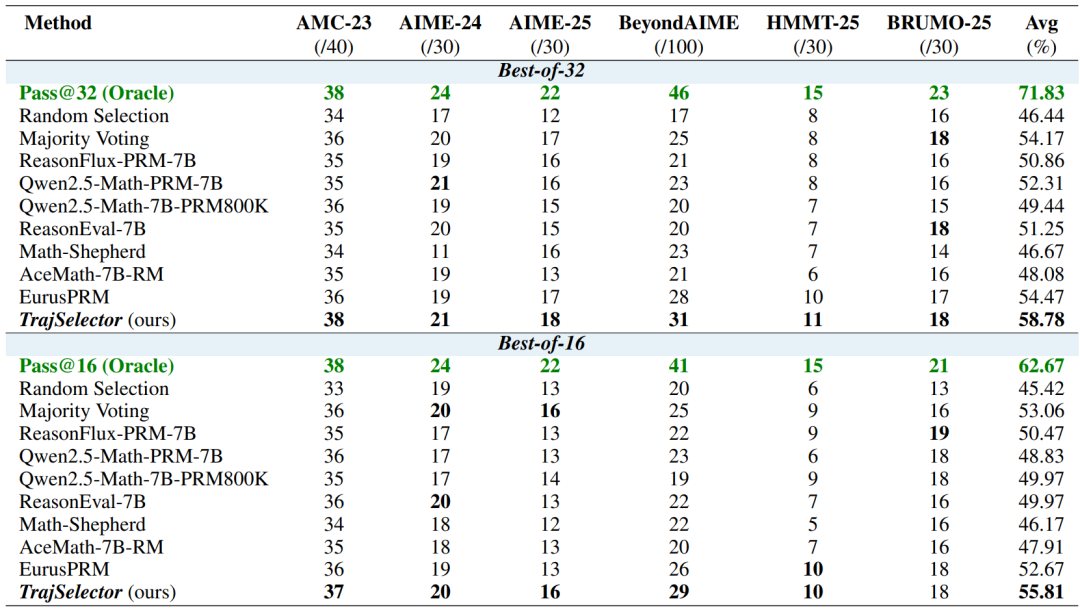
External TTS curve:
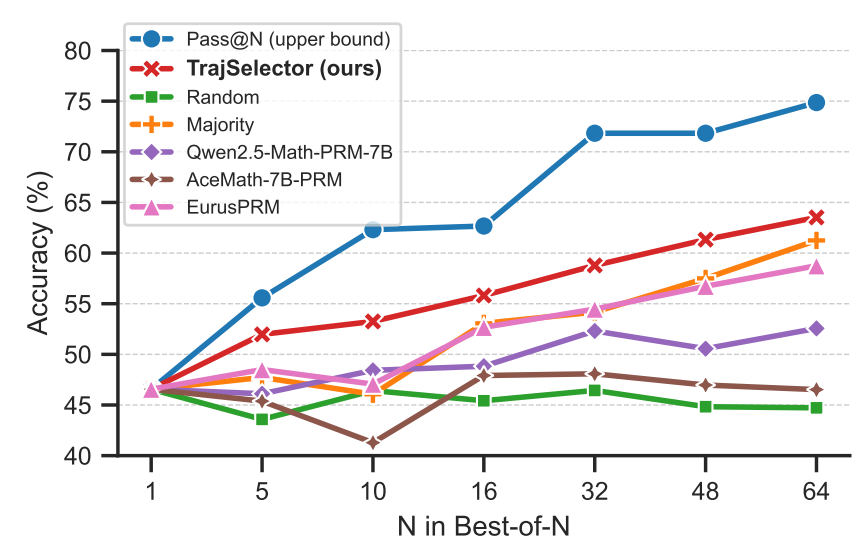
Outcome:
TrajSelector scales more stably than other baselines as N increases.
---
Conclusion
Key Benefits:
- Frozen large policy model + small scoring model (0.6B)
- Significant cost savings over 7B PRMs
- No manual process annotations
- Better Best-of-N reasoning performance
Practical for large-model inference in education, scientific computing, and beyond.

---
Broader Impact — Synergy with AI Content Platforms
Just as TrajSelector leverages existing models more intelligently, platforms like AiToEarn官网 do the same for content:
- AI generation → multi-platform publishing → analytics → monetization
- Supports: Douyin, Kwai, WeChat, Bilibili, Rednote, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X/Twitter
- Integrated AI model ranking (AI模型排名)
This pairing — technical efficiency + global reach — enables both high-quality AI outputs and broad, monetizable distribution.
---
References: