Tencent Youtu Introduces Training-Free GRPO: Reinforcement Learning for DeepSeek-V3.2 for Just $8

Reinforcement Learning for Ultra-Large Models — at a Fraction of the Cost

Richard Sutton — known as the “Father of Reinforcement Learning” and a Turing Award winner — predicts that the next generation of intelligent agents will achieve superhuman capabilities primarily by learning from experience, rather than relying solely on supervised learning with human-labeled data.
Traditionally, RL training on a 32B parameter model could cost tens of thousands of dollars.
Now, Training-Free GRPO makes it possible to train the latest 671B DeepSeek-V3.2 model for just $8, entirely by learning from experience — without expensive parameter updates.
On DeepSeek-V3.1-Terminus, Training-Free GRPO uses only 100 DAPO-Math training samples and $18, yet still delivers out-of-distribution transferable gains on the AIME leaderboard.
---
The Challenge: Cost and Poor Generalization
The Sky-High Cost of RL Training
and Misaligned Generalization in Large Models
While large models are powerful, their performance in niche areas is often lacking. Common solutions — supervised fine-tuning or RL with parameter updates — have drawbacks:
- ⚠ Compute Black Hole: Single training runs can cost tens of thousands of dollars; each iteration burns more resources.
- ⚠ Generalization Problem: Fine-tuned models excel at narrow tasks but generalize poorly, forcing enterprises to run multiple specialized models — raising complexity and maintenance costs.
- ⚠ Data Scarcity: Huge volumes of clean, labeled data are required. Sutton warns that human-generated knowledge is reaching its limits.
The question: In real-world deployment, is there a cost-efficient alternative?
---
The Breakthrough: Training-Free GRPO
Tencent Youtu Lab’s Training-Free GRPO gives a clear “Yes”!
Core Idea:
Freeze model parameters and iteratively guide behavior by accumulating experiential knowledge — perfectly aligned with Sutton’s vision: agents should keep learning from what they themselves do, not just replicate human labels.
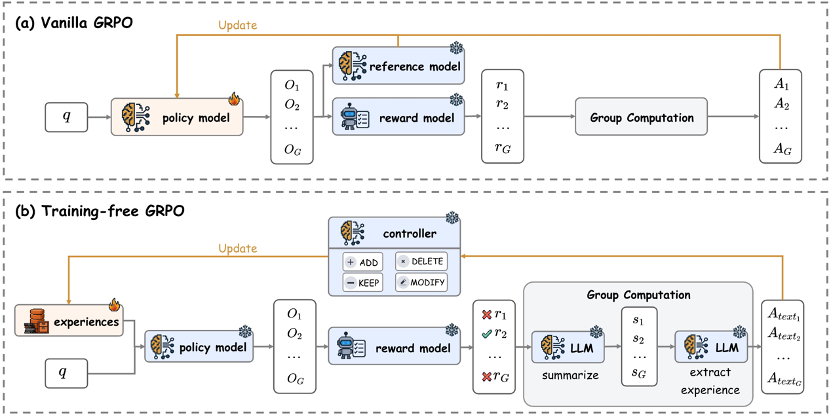
Difference from Traditional GRPO:
- Traditional: Updates model parameters with RL.
- Training-Free: Keeps parameters frozen, refines an experience bank across multiple RL rounds, and injects that experience at inference.
- Result: RL effect without retraining.
---
How to Shape a Model Without Training — 4 Steps
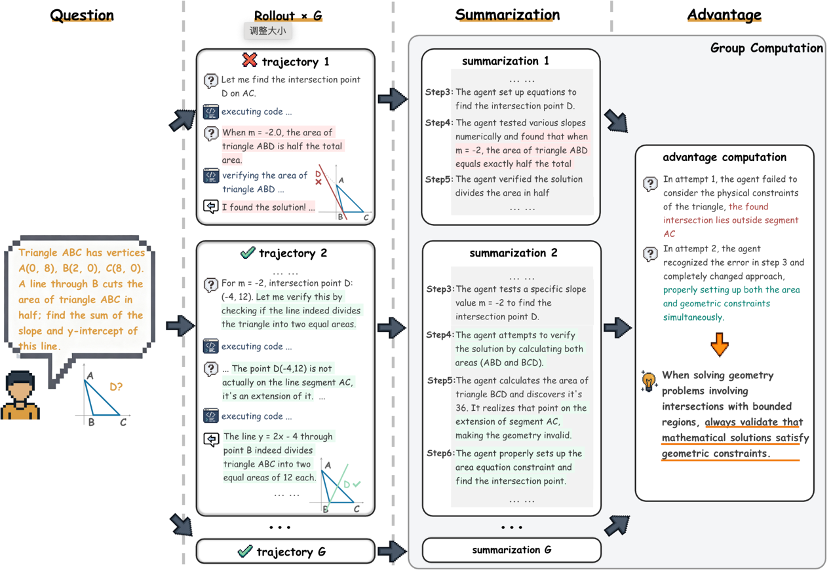
Step 1: Multi-Path Exploration (Rollout)
Generate several unique solution paths for each task, capturing different strategies.
Example: In math problems, one path may rely on coordinate geometry, another on geometric properties.
Step 2: RL Reward Assignment (Reward)
Reward direction is set using a small set of reference answers.
Each path is scored based on:
- Match with standard answer
- Correctness of executed code
- Success in search tasks
Step 3: Semantic Advantage Extraction (Group Advantage)
Compare solutions in the same batch and reflect: Why did A outperform B?
Example insights:
- Successful Path: Correct coordinate setup; thorough verification.
- Failed Path: Wrong direction setup; incomplete checks.
> Semantic insights outperform mere numeric scores.
Step 4: Experience Library Optimization (Optimization)
Update the bank of experience:
- Add: Strategies proven effective
- Revise: Refine guiding rules
- Remove: Ineffective approaches
Like a student continuously refining study notes — the model documents and builds on past success.
---
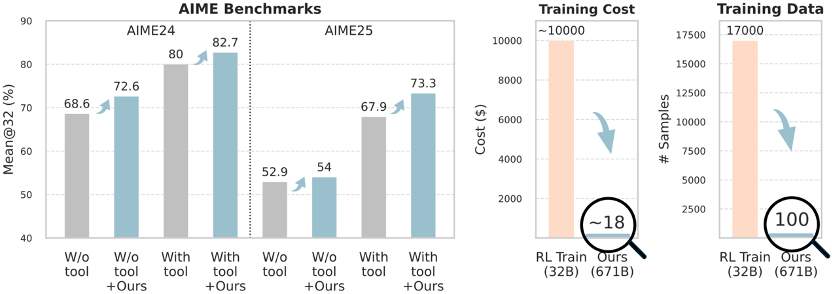
Results: Big Gains for $8–$18
Even for a massive 671B model, Training-Free GRPO boosts mathematical reasoning using only 100 samples.
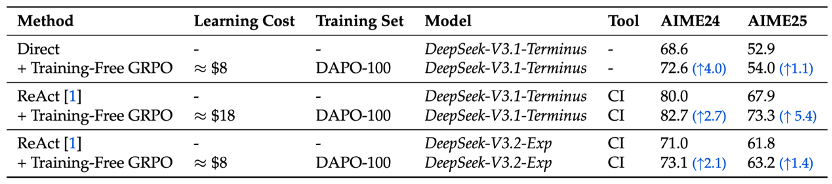
- Three training rounds are enough to raise AIME Mean@32 scores (with or without CI assistance).
- Performance improves steadily across rounds.
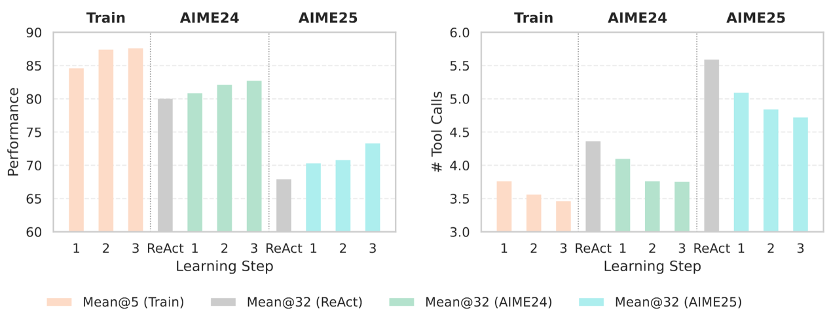
- Tool usage drops: The model learns better reasoning and efficient tool use.
In web search tasks, Training-Free GRPO gives a +4.6% Pass@1 uplift over DeepSeek-V3.1-Terminus — without touching parameters.

---
Cost Impact — A Dimensional Reduction Blow
Cost comparison:
| Method | Cost | Notes |
|---------------------------|-----------------------|-------|
| Traditional RL (32B) | ~$10,000 | 20k GPU-hours / 400 steps |
| Training-Free GRPO (671B) | ~$8–$18 | No parameter updates |
Advantages:
- No dedicated inference GPUs — API access only.
- Ideal for:
- Long-tail niche adaptation
- Rapid iteration
- Budget-limited teams (independent devs, SMEs, researchers)
---
Conclusion
Training-Free GRPO makes RL for ultra-large LLMs viable for any developer.
Low-cost, parameter-free experience shaping removes the entry barrier.
Reinforcement learning for $8 — why wait?

Try it here:
GitHub → https://github.com/TencentCloudADP/youtu-agent/tree/training_free_GRPO
Paper → https://arxiv.org/abs/2510.08191
---
Bonus: Monetizing AI Creativity
Platforms like AiToEarn官网 help creators:
- Generate AI content
- Publish simultaneously across Douyin, Kwai, WeChat, Bilibili, Xiaohongshu, Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter)
- Access analytics & AI model rankings (AI模型排名)
- Maximize reach & monetization
Integrating Training-Free GRPO with AiToEarn opens the door to fully optimized content production pipelines — fast iteration meets global distribution.
---
Preview: Training-Free GRPO will be part of the Youtu-Agent framework, enabling customizable, high-performance AI applications.
> Costs are based on official DeepSeek API pricing and may vary with usage.


