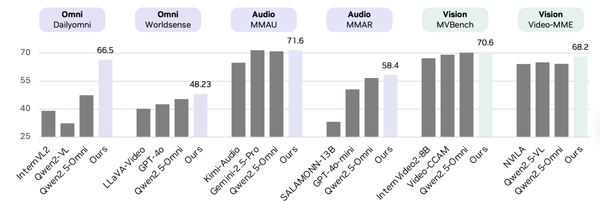
Today’s Open Source (2025-10-27): PRIME-RL Breakthrough — Multi-Stage RL and Coevolutionary System Achieve IPhO Gold-Level Physics Reasoning
Open-Source AI Model Series & Frameworks Overview
This document highlights several cutting-edge open-source AI projects, frameworks, and tools across physics reasoning, multimodal intelligence, reinforcement learning, inference acceleration, and agent-based deep research.
---
🏆 Base Models
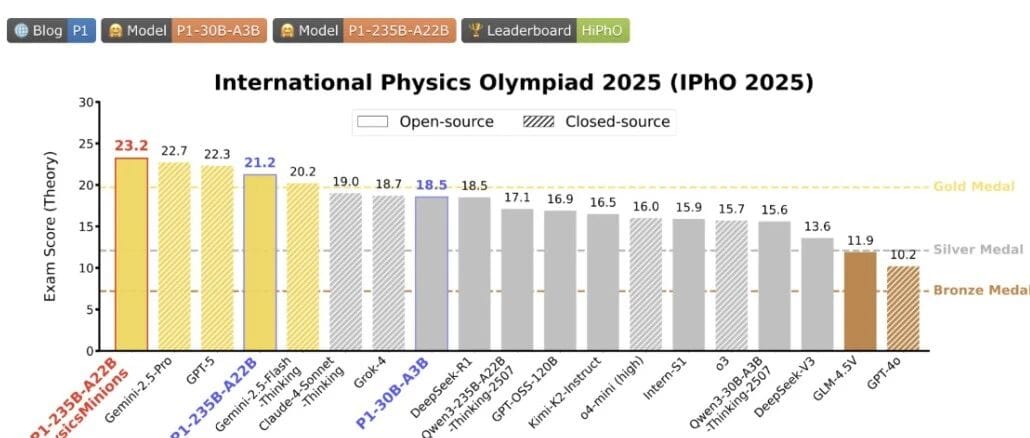
① P1 Project — Physics Reasoning at Olympiad Level
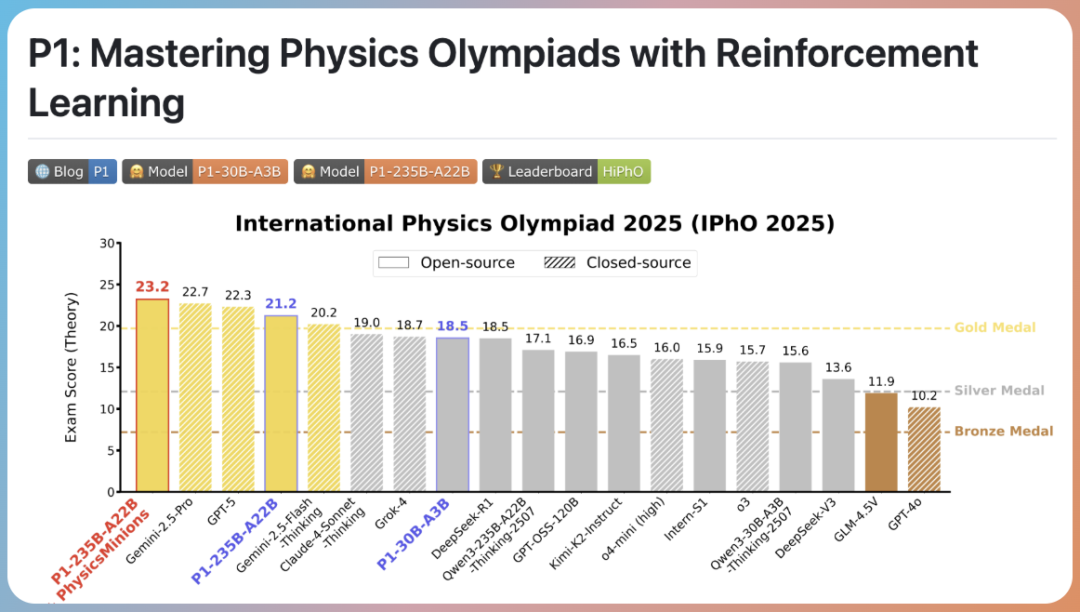
Key Highlights:
- First open-source model series from PRIME-RL.
- Designed for Olympiad-level physics problems using multi-stage reinforcement learning and a co-evolutionary multi-agent system (PhysicsMinions).
- Achieved gold-medal-level performance at the 2025 International Physics Olympiad (IPhO).
- Released in two sizes:
- P1-30B-A3B — 30B parameters
- P1-235B-A22B — 235B parameters
Learn More: P1 Project Details
---
② Puffin Project — Camera-Centric Multimodal Model

Key Highlights:
- Pioneering camera-centric framework integrating camera geometry into a unified multimodal model.
- Improves spatial reasoning and multimodal generation capabilities.
- Includes model variants:
- Base models for general tasks
- Spatial reasoning–enhanced models
- Instruction-tuned models for cross-view & complex multimodal interaction
Learn More: Puffin Project Details
---
🛠️ Frameworks & Essential Tools
① DisCO — Discriminative RL Optimization

Key Highlights:
- Reinforcement Learning framework improving convergence speed and optimization stability.
- Rewards correct answers, penalizes incorrect ones.
- Solves difficulty bias and entropy collapse, outperforming GRPO on reasoning benchmarks.
- Uses unclipped scoring with simple constrained optimization.
Learn More: DisCO Framework
---
② Fast-dLLM — Accelerated Diffusion-based LLMs

Key Highlights:
- Diffusion-based LLM inference acceleration framework.
- Optimized for models like Dream and LLaDA.
- Implements KV caching and parallel decoding to reduce inference time.
- Works without additional training.
Learn More: Fast-dLLM Framework
---
③ CE-GPPO — Stable Gradient-Clipped PPO

Key Highlights:
- Introduces mild, bounded clipped-token gradients into PPO.
- Controls out-of-bound gradient magnitudes for balanced exploration vs. exploitation.
- Reduces entropy instability on mathematical reasoning benchmarks.
- Consistently outperforms strong baselines across scales.
---
> Tip: Combining model innovation with streamlined deployment & monetization can accelerate adoption.
> Platforms like AiToEarn integrate analytics, publishing automation, and AI model rankings — valuable for projects like P1, Puffin, or Fast-dLLM.
---
🤖 AI Agent Development
① PokeeResearchOSS — 7B Deep Research Agent

Key Highlights:
- PokeeResearch-7B Agent built for complex question answering.
- Integrates real-time web search and content parsing.
- Delivers citation-rich research reports.
- Powered by a 7B parameter model for efficient reasoning at scale.
Quick Access: PokeeResearchOSS Project

---
🌍 Broader AI Publishing Context
Platforms like AiToEarn enable creators to:
- Publish across major channels — Douyin, Kwai, WeChat, Bilibili, Rednote (Xiaohongshu), Facebook, Instagram, LinkedIn, Threads, YouTube, Pinterest, X (Twitter).
- Automate workflows with integrated analytics.
- Rank models via AI model rankings to benchmark & promote capabilities.
---
References:
---
Do you want me to also add a comparison table summarizing each project’s parameters, purpose, and unique features for quick reference? That would make this overview even more user-friendly.