Xie Saining, Fei-Fei Li, and Yann LeCun Team Up for the First Time! Introducing the New "Hyperception" Paradigm — AI Can Now Predict and Remember, Not Just See

Spatial Intelligence & Supersensing: The Next Frontier in AI
Leading AI researchers — Fei-Fei Li, Saining Xie, and Yann LeCun — have been highlighting a transformative concept: Spatial Intelligence.
This goes beyond simply “understanding images or videos.” It’s about:
- Comprehending spatial structures
- Remembering events
- Predicting future outcomes
In essence, a truly capable AI should not only “see,” but also sense, understand, and actively organize experience — a core competency for future multimodal intelligence.
---
Introducing Cambrian-S: Spatial Supersensing in Video
The trio recently collaborated to publish Cambrian-S: Towards Spatial Supersensing in Video.

Their proposed paradigm — Supersensing — emphasizes that AI models must:
- Observe, recognize, and answer
- Remember and understand 3D structure
- Predict future events
- Organize experiences into an Internal World Model

Co-first author Shusheng Yang noted: supersensing demands active prediction, filtering, and organization of sensory inputs — not passive reception.

Saining Xie described Cambrian-S as their first step into spatial supersensing for video. Despite its length, the paper is rich with detail and groundbreaking perspectives — essential reading for those in video-based multimodal modeling.

---
Defining “Spatial Supersensing”
Background
Last year, Xie’s team released Cambrian-1 — focusing on multimodal image modeling.
Instead of rushing towards Cambrian-2 or Cambrian-3, they paused to reflect:
- What truly is multimodal intelligence?
- Is LLM-style perception modeling adequate?
- Why is human perception intuitive yet powerful?
Their conclusion: Without Supersensing, there can be no Superintelligence.
---
What Supersensing Is — and Isn’t
Supersensing is not about better sensors or cameras. It’s how a digital lifeform truly experiences the world — continuously absorbing sensory streams and learning from them.
Key point: Human agents can solve abstract problems without perception, but to operate in the real world, AI agents require sensory modeling.
As Andrej Karpathy has remarked: sensory modeling may be all that intelligence requires.
---
The Five Levels of Supersensing
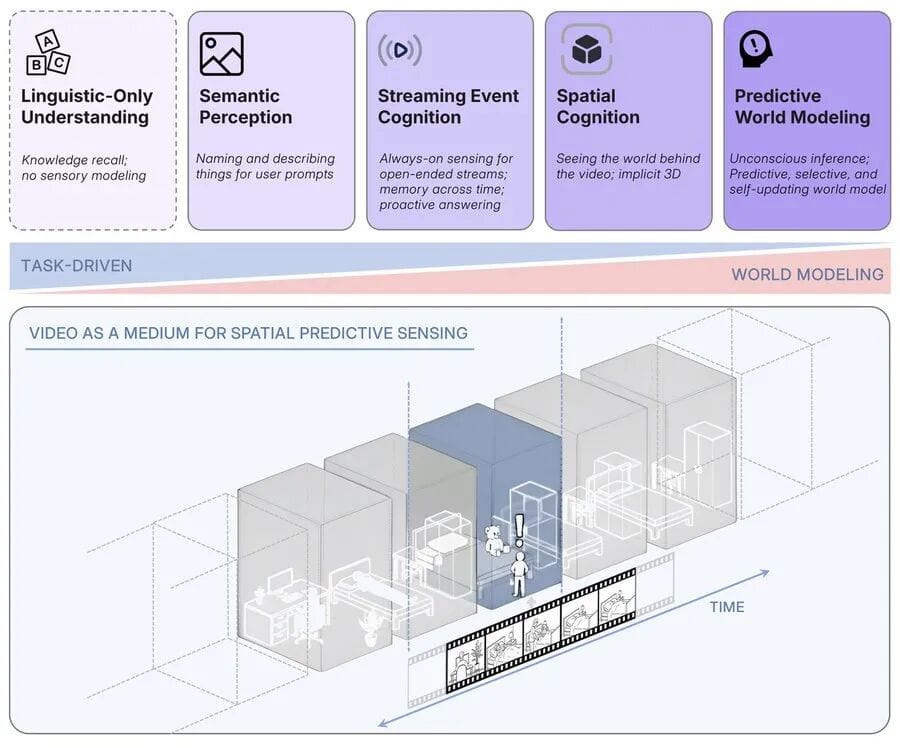
- No Sensory Capabilities
- Example: LLMs
- Operate purely on text/symbols, without grounding in the physical world.
- Semantic Perception
- Parsing pixels into objects, attributes, and relationships.
- Strong performance in “image captioning.”
- Streaming Event Cognition
- Handling continuous, real-time data streams.
- Active interpretation and response to ongoing events.
- Implicit 3D Spatial Cognition
- Understanding video as a projection of the 3D world.
- Answering “what exists,” “where it is,” and “how it changes over time.”
- Current video models are still lacking here.
- Predictive World Modeling
- Anticipating possible future states based on prior expectations.
- Using surprise as a driver for attention, memory, and learning.
---
Why Predictive World Modeling Matters
The human brain continuously predicts potential world states. High prediction errors trigger attention and learning, but current multimodal systems lack such mechanisms.

---
Evaluating Spatial Supersensing
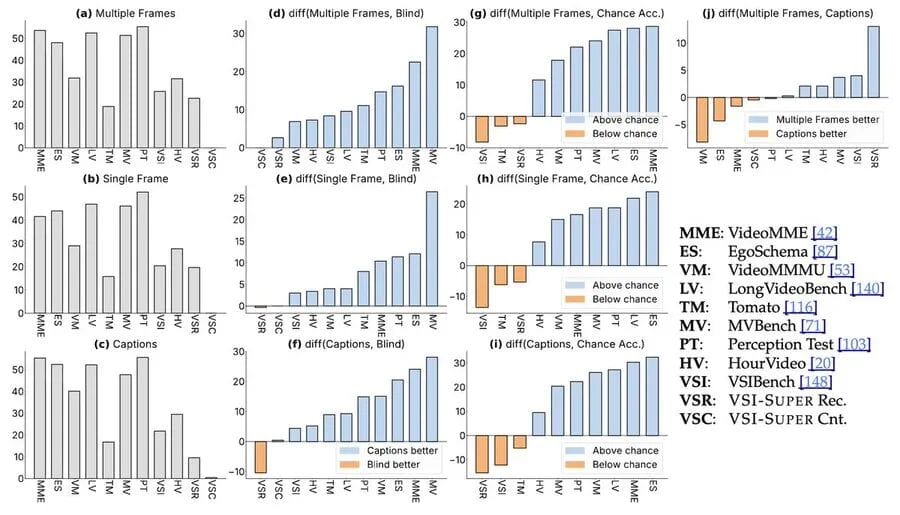
Existing video benchmarks focus on language understanding and semantic perception, but neglect higher-level supersensing.
Even efforts like VSI-Bench address spatial perception only for short videos, missing unbounded, continuous visual streams.
---
VSI-SUPER: A New Benchmark
VSI-SUPER introduces two challenging tasks:
- VSI-SUPER Recall (VSR)
- Recall anomalous object locations in long videos.
- VSI-SUPER Count (VSC)
- Continuously accumulate spatial information across long scenarios.
Unlike conventional tests, VSI-SUPER stitches short clips into arbitrarily long videos, challenging models to remember unbounded visual streams.
Testing Gemini-2.5 Flash revealed high performance on standard benchmarks, yet failure on VSI-SUPER.

---
Cambrian-S: Addressing the Challenge
While data and scale matter, the key missing factor is training data designed for spatial cognition.
VSI-590K Dataset
- 590,000 samples from:
- First-person indoor environments (3D annotations)
- Simulators
- Pseudo-labeled YouTube videos
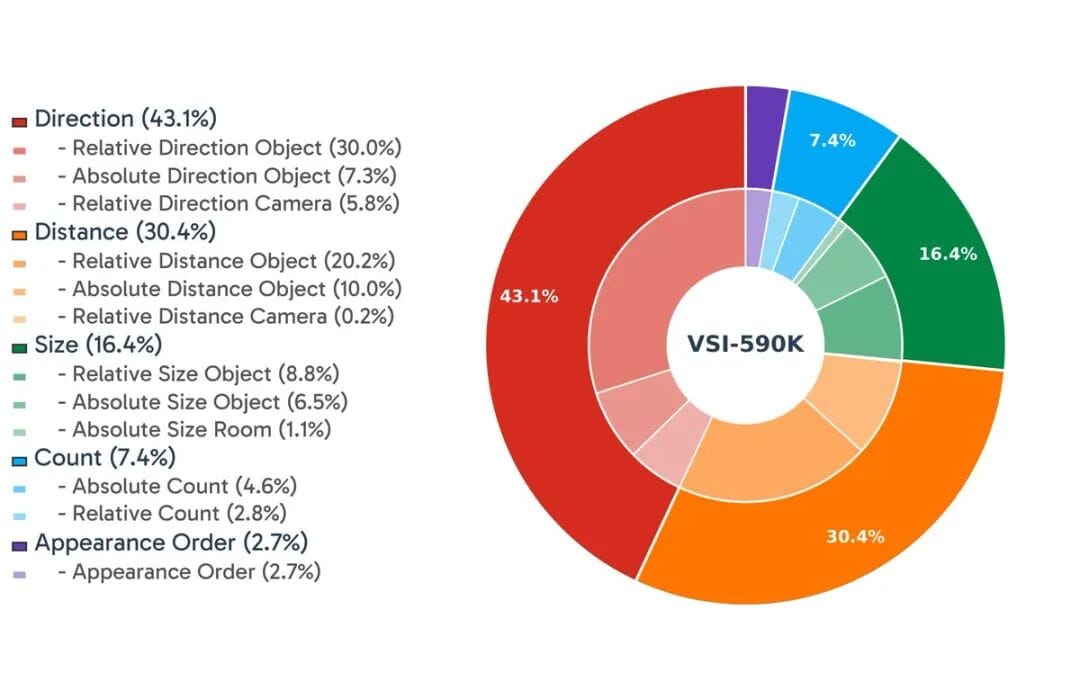
Models from 0.5B to 7B parameters were trained, achieving up to +30% spatial reasoning gains over baseline MLLMs.

Still, VSI-SUPER remains unfixed — suggesting LLM-style multimodal systems are not the ultimate path to supersensing.

---
Predictive Perception Prototype
Cambrian-S features:
- Strong general video/image understanding
- Leading spatial perception performance
Additional strengths:
- Generalizes to unseen spatial tasks
- Passes debias stress tests
---
Human Analogy
In baseball, players predict ball trajectory before their brain fully processes the visual input — a skill rooted in internal predictive world models.
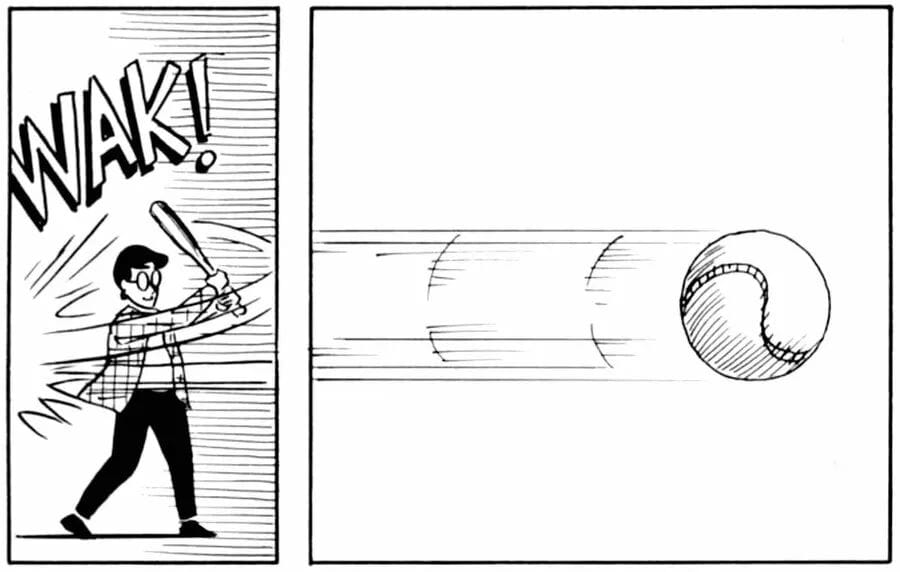
This ability filters sensory overload by ignoring low-error predictions & focusing on surprises.
---
Latent Frame Prediction
The team trained a latent frame prediction (LFP) head that:
- Predicts the next input frame
- Compares predicted vs actual (difference = surprise value)
- Uses surprise for:
- Memory management (skip unremarkable frames)
- Event segmentation (detect scene boundaries)
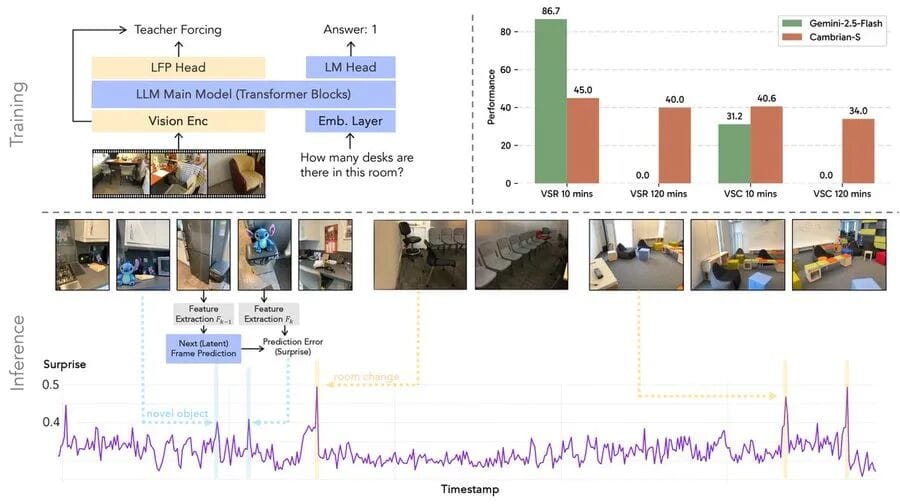
Even a smaller model using this method beat Gemini on VSI-SUPER.
---
Related Releases
- Multimodal Benchmark Design research — removing language bias
- Simulator tools for collecting spatial perception video data



---
Open-Source Resources
- Project homepage: https://cambrian-mllm.github.io/
- Paper: https://arxiv.org/abs/2511.04670
- Code: https://github.com/cambrian-mllm/cambrian-s
- Models: https://huggingface.co/collections/nyu-visionx/cambrian-s-models
- Dataset: https://huggingface.co/datasets/nyu-visionx/VSI-590K
- Benchmark: https://huggingface.co/collections/nyu-visionx/vsi-super
---
Connection to AI Content Platforms
Advanced cognitive capabilities like predictive perception could power AI-driven creators.
Platforms such as AiToEarn官网 allow:
- AI content generation
- Multi-platform publishing (Douyin, Kwai, WeChat, Bilibili, Rednote, YouTube, LinkedIn, Instagram, Pinterest, Threads, X)
- Integrated analytics & model ranking
Read AiToEarn Blog | Open-source Repo
---
Summary:
Spatial Supersensing represents a paradigm shift in AI development — moving from passive perception to active, predictive, and structurally aware intelligence. Benchmarks like VSI-SUPER and models like Cambrian-S are critical steps toward this future, where AI can remember, predict, and organize experiences across unbounded multimodal streams.


