Zhiyuan Wujie · Emu3.5 Reshapes the World Model Landscape: Introducing the First Multimodal Scaling Paradigm for Next-Gen AI Understanding
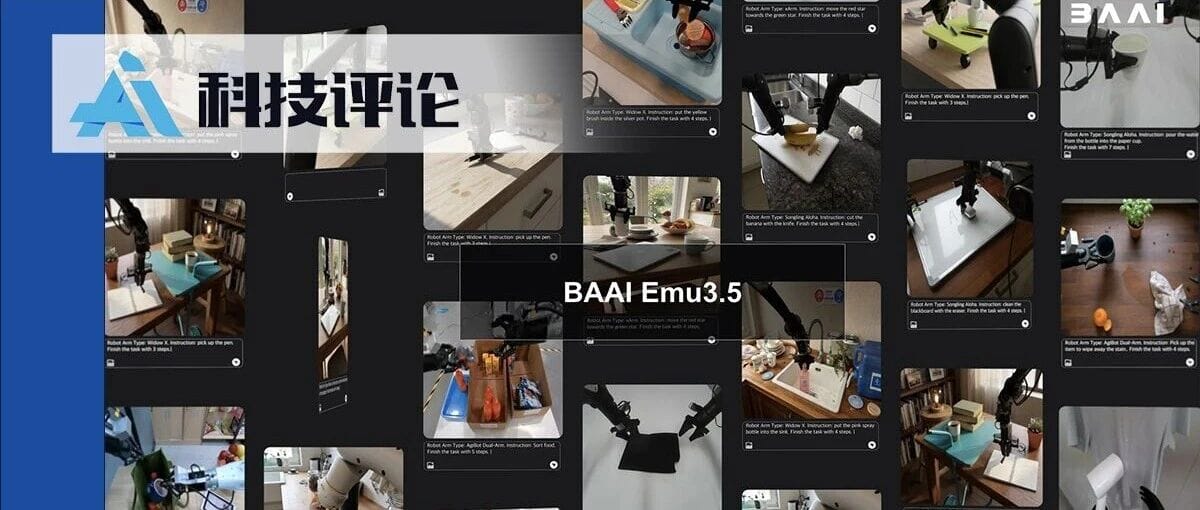
Once Again, Pushing the Limits of World Models

A new benchmark has been set in the race for world models.
The Beijing Academy of Artificial Intelligence (BAAI) has announced its large-scale multimodal world model — Wujie·Emu3.5.
It not only simulates complex, dynamic physical realities with remarkable realism, but also reveals the existence of a Multimodal Scaling Paradigm.
---
Key Capabilities Demonstrated
- World Exploration
- Embodied Operations
- Visual Guidance
- Example: Prompted with “How to make shrimp and celery dumplings”, the model generates a step-by-step, accurate and coherent recipe — covering ingredient preparation, mixing, wrapping, boiling, and plating — along with vivid, realistic images.

- Visual Storytelling
- Image Editing and Generation
---
The Context: World Model Competition
From OpenAI’s Sora to DeepMind’s Genie, and from Yann LeCun’s JEPA to Fei-Fei Li’s Marble, researchers and tech giants are converging on the potential of world models.
Yet, as visual realism approaches perfection, deeper questions arise:
> Is there a scalable, first-principles path enabling a model to autonomously learn the causal laws of the world from vast multimodal data — and truly comprehend physical reality?
BAAI’s Wujie·Emu3.5 is designed to address this challenge.

---
01 — Wujie·Emu3.5: Power in Simplicity and Scale
October 2024 marked the release of Wujie·Emu3, a native multimodal world model built on a single Transformer for next-token prediction. It unified text, images, and video without diffusion models or hybrids, attracting major industry attention.
But new challenges emerged:
- How to learn efficiently from long videos
- How to achieve truly general multimodal interaction
- How to keep inference efficient at trillion-token scales
Emu3.5 addresses these with a simple, unified Next-State Prediction (NSP) objective and a broadly applicable architecture — at massive scale.
Core Breakthroughs
- Native Multimodal Unified Architecture
- Single 34B dense Transformer
- Uniform encoding of all modalities into discrete token sequences
- End-to-end autoregressive processing for true modality unification
- Single Training Objective: Predict the Next State
- Predicts the next probable state in interleaved visual-language sequences
- Forces the model to learn the “grammar” of the dynamic world — like LLMs learn language via next-token prediction
- Massive Multimodal Dataset (>10 Trillion Tokens)
- ~790 years of training-time video + speech transcripts
- Rich spatiotemporal and causal information through Video-Text Interleaved Data
---
💡 Tip for Creators & Researchers:
Platforms like AiToEarn官网 help creators leverage models like Emu3.5. AiToEarn is an open-source AI content monetization platform with:
- AI generation tools
- Cross-platform publishing (Douyin, Kwai, WeChat, Bilibili, Instagram, LinkedIn, YouTube, etc.)
- Analytics and model rankings
---
4 — First-Ever Revelation of the Multimodal Scaling Paradigm
The Emu3.5 technical report shows: as compute during pretraining scales, the model’s error rate on out-of-distribution tasks drops predictably and smoothly.
This means its embodied world knowledge generalizes stably beyond training data.
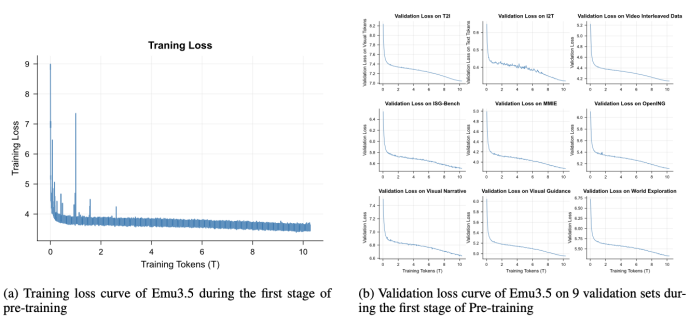
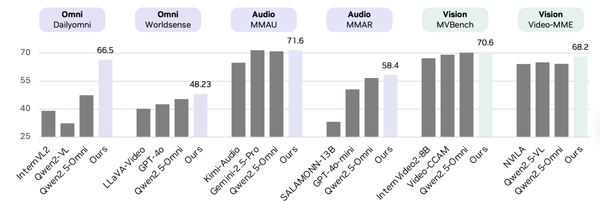
Scale & Performance Gains
- Parameters: 8B → 34B
- Video-data scale: 15 years → 790 years
- Key metric gains: temporal consistency, cross-modal reasoning, embodied interaction planning
Significance: Comparable to GPT-3’s revelation of the language model scaling law.
Scaling laws make progress predictable, moving world model research from alchemy to engineering — enabling confident investment.
---

02 — Opening a New Era for Multimodal World Models
Strategic Importance
World models are critical for:
- General-purpose robotics
- L5 autonomous driving
- Artificial General Intelligence (AGI)
Wujie·Emu3.5’s native multimodality + unified autoregression paradigm, combined with its scaling insights, set a clear R&D roadmap:
- Future competitions will focus on scale, data richness, and physical-world comprehension — not just video quality.
---
Recommended Reading
- 
- From “WuDao” to “WuJie”: ZhiYuan Steps into the New Era of Large Models
- 
---
Toward Collective Intelligence
BAAI’s Cross-Ontology Embodied Large–Small Brain Framework

BAAI has released:
- A cross-ontology embodied “large brain–small brain” framework
- An open-source embodied brain
This addresses the challenge of heterogeneous intelligent agents — having different bodies, sensors, and action spaces — cooperating in complex, dynamic environments.
Cross-Ontology Embodied Intelligence
Traditional assumption: All agents share the same ontology (perception, actions, world view).
Reality:
- Biped robots, drones, simulation agents vary dramatically in sensors & controls.
- Cooperation demands bridging ontological differences.
BAAI’s approach:
- “Large brain”: High-level planning, strategy, reasoning
- “Small brains”: Modality-specific perception, control, execution
- Enables flexible, robust cooperation among diverse agents
---
Open-Sourcing the Embodied Brain
An embodied brain integrates:
- Perception
- Decision-making
- Action control
For physical robots, virtual avatars, or simulation agents.
BAAI’s open-source release invites community experimentation — fostering interoperability standards between heterogeneous AI agents.
---
Significance for Collective Intelligence
Potential applications:
- Robotics
- Industrial automation
- Swarm systems
- Search & rescue
- Multi-agent simulations
Fits into AI collaboration ecosystems — modular, open frameworks to scale abilities by combining specialized agents into powerful collectives.
---
Looking Ahead
- Open platforms & interoperability are essential.
- AiToEarn官网 demonstrates how AI generation + multi-platform distribution + analytics + monetization can amplify both creative and technical work.
Future AI development will converge on seamless AI-human and AI-AI collaboration, powered by scalable, open, and interoperable architectures.
---
Would you like me to also create a summary infographic-style section for Emu3.5, so that readers can grasp the specs and breakthroughs in under 30 seconds? That would make the Markdown even more digestible.



{kind=link}
{kind=link}