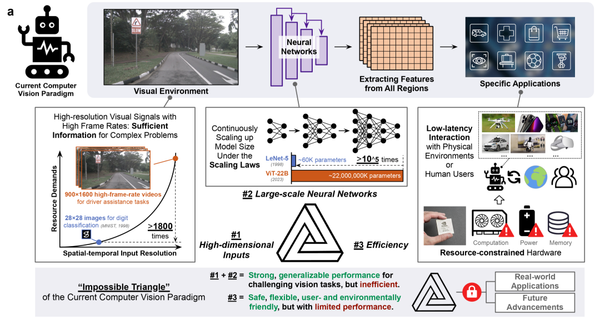
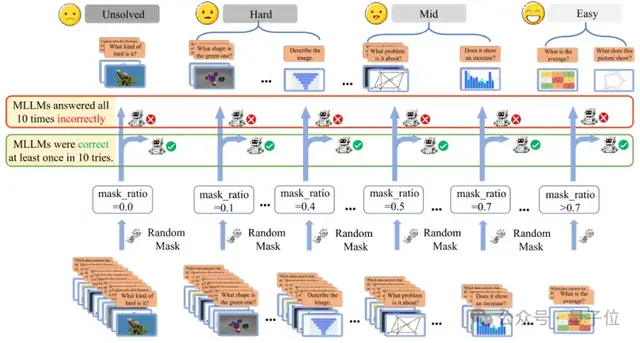
AI news
Quark AI Glasses Review: Ultra-Thin Temples, Flagship-Level Smartphone Image Quality
Quark AI Glasses — Smart Tech That Looks Just Like Ordinary Eyewear For smart glasses, “looks just like ordinary glasses” is actually high praise — and it’s the standout advantage of the Quark AI Glasses. Yesterday, Alibaba’s Quark officially launched two product lines: * S1 series (with display) — starting at RMB